Spark SQL是用于结构化数据处理的Spark模块(结构化数据可以来自外部结构化数据源也可以通过RDD获取) 。与基本的Spark RDD API不同,Spark SQL提供的接口为Spark提供了有关数据结构和正在执行的计算的更多信息。在内部,Spark SQL使用此额外信息来执行额外的优化。有几种与Spark SQL交互的方法,包括SQL和Dataset API。在计算结果时,使用相同的执行引擎,与您用于表达计算的API /语言无关。这种统一意味着开发人员可以轻松地在不同的API之间来回切换,从而提供表达给定转换的最自然的方式。
支持多种数据源:Hive、RDD、Parquet、JSON、JDBC等。
多种性能优化技术:in-memory columnar storage、byte-code generation、cost model动态评估等。
组件扩展性:对于SQL的语法解析器、分析器以及优化器,用户都可以自己重新开发,并且动态扩展。
1、内存列存储(in-memory columnar storage)
Spark SQL主要用于进行结构化数据的处理。它提供的最核心的编程抽象,就是DataFrame和DataSet。同时Spark SQL还可以作为分布式的SQL查询引擎 。
DataSet(数据集)是分布式数据集合[A Dataset is a distributed collection of data] 。数据集是Spark 1.6中添加的一个新接口,它提供了RDD的优势(强类型,使用强大的lambda函数的能力)以及Spark SQL优化执行引擎的优点。数据集可以从JVM对象中被构造,然后使用transformation(转换操作)(map,flatMap,filter等等)。数据集API在Scala和 Java中可用。Python没有对Dataset API的支持。但由于Python的动态特性,数据集API的许多好处已经可用(即您可以自然地按名称访问行的字段 row.columnName)。R语言的情况类似。这里,博客中的实现代码大多采用Spark的原生代码scala实现。DataFrame是组织为命名列的数据集[A DataFrame is a Dataset organized into named columns] 。它在概念上等同于关系数据库中的表或R / Python中的数据框,但在引擎盖下具有更丰富的优化。DataFrame可以从多种来源构建,例如:结构化数据文件,Hive中的表,外部数据库或现有RDD。DataFrame API在Scala,Java,Python和R中可用。在Scala和Java中,DataFrame由Rows 的数据集表示。在Scala API中,DataFrame它只是一个类型别名Dataset[Row]。而在Java API中,用户需要使用Dataset来表示DataFrame。
简单的来理解:RDD(弹性分布式数据集)是我们在Spark Core中常用的最小基本单位。而DataFrame是我们在进行SparkSQL进行数据查询数据分析时的最小基本单位 。那么这两者有何区别联系了,请看下图。
总结 :
2、什么是DataFrame
内部数据无类型,统一为Row
DataFrame是一种特殊类型的DataSet,DataSet[Row]=DataFrame
DataFrame自带优化器Catalyst,可以自动优化程序
DataFrame提供了一整套的Data Source API
3、DataSet的产生
dataframe.filter("salary>1000").show()
由于DataFrame的数据类型统一是Row,所以DataFrame也是有缺点的。
明显缺点:
1、Row不能直接操作domain对象
2、函数风格编程,没有面向对象风格的API
所以,Spark SQL引入了DataSet,扩展了DataFrmae的API,提供了编译时类型检查,面向对象风格的API
从spark2.0以上版本开始,Spark使用全新的SparkSession接口替代Spark1.6中的SQLContext及HiveContext接口来实现其对数据加载、转换、处理功能。SparkSession实现了SQLContext及HiveContext所有功能。
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
/**
* 通过SparkSession创建DataFrame
* @author xjh 2018.11.26
*/
object CreateDataFrame {
def main(args: Array[String]): Unit = {
val conf=new SparkConf().setAppName("CreateDataFrame").setMaster("local")
val spark=SparkSession.builder().appName("CreateDataFrame").config(conf).getOrCreate()
val df=spark.read.json("hdfs://m1:9000/spark/people.json")
df.show()
}
}
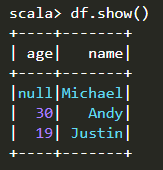
运行结果:
在Spark 2.0中,DataFrames只是RowScala和Java API中的数据集。与“类型转换”相比,这些操作也称为“无类型转换”,带有强类型Scala / Java数据集。
object CreateDataFrame {
def main(args: Array[String]): Unit = {
val conf=new SparkConf().setAppName("CreateDataFrame").setMaster("local")
val spark=SparkSession.builder().appName("CreateDataFrame").config(conf).getOrCreate()
import spark.implicit._
val df=spark.read.json("hdfs://m1:9000/spark/people.json")
//df.show()
// Print the schema in a tree format
df.printSchema()
// root
// |-- age: long (nullable = true)
// |-- name: string (nullable = true)
// Select only the "name" column
df.select("name").show()
// +-------+
// | name|
// +-------+
// |Michael|
// | Andy|
// | Justin|
// +-------+
// Select everybody, but increment the age by 1
df.select($"name", $"age" + 1).show()
// +-------+---------+
// | name|(age + 1)|
// +-------+---------+
// |Michael| null|
// | Andy| 31|
// | Justin| 20|
// +-------+---------+
// Select people older than 21
df.filter($"age" > 21).show()
// +---+----+
// |age|name|
// +---+----+
// | 30|Andy|
// +---+----+
// Count people by age
df.groupBy("age").count().show()
// +----+-----+
// | age|count|
// +----+-----+
// | 19| 1|
// |null| 1|
// | 30| 1|
// +----+-----+
// Register the DataFrame as a SQL temporary view
df.createOrReplaceTempView("people")
val sqlDF = spark.sql("SELECT * FROM people")
sqlDF.show()
// +----+-------+
// | age| name|
// +----+-------+
// |null|Michael|
// | 30| Andy|
// | 19| Justin|
// +----+-------+
}
}
Spark SQL中的临时视图(TempView)是会话范围的,如果创建它的会话终止,它将消失。例如上面的代码样例,在执行spark.sql之前,注册DataFrame为SQL临时会话。
数据集与rdd类似,但它不使用Java序列化或Kryo,而是使用专门的编码器序列化对象,以便通过网络进行处理或传输。虽然编码器和标准序列化都负责将对象转换为字节,但编码器是动态生成的代码,使用的格式允许Spark执行许多操作,如过滤、排序和散列,而无需将字节反序列化回对象。
case class Person (name : String , age : Long )
//为case类创建编码器
val caseClassDS = Seq (Person (“Andy” , 32 ))。toDS ()
caseClassDS 。show ()
// + ---- + --- +
// | name | age |
// + ---- + --- +
// | Andy | 32 |
// + ---- + --- +
对于最常见的类型//编码器是通过导入spark.implicits._自动提供
VAL primitiveDS = SEQ (1 , 2 , 3 )。toDS ()
primitiveDS 。地图(_ + 1 )。collect () //返回:数组(2,3,4)
//通过提供类可以将DataFrame转换为数据集。映射将通过名称
val path = “examples / src / main / resources / people.json”
val peopleDS = spark完成。读。json (路径)。作为[ 人]
人DS 。show ()
// + ---- + ------- +
// | 年龄| 名称|
// + ---- + ------- +
// | null | Michael |
// | 30 | 安迪|
// | 19 | 贾斯汀|
// + ---- + ------- +
Spark官网提供了两种方法来实现从RDD转换得到DataFrame。第一种方法是,利用反射机制来推断包含特定类型对象的RDD的schema,适用对已知数据结构的RDD转换;
ase class Person(name: String, age: Long)
object RDDToDataFrame {
def main(args: Array[String]): Unit = {
val conf=new SparkConf().setAppName("CreateDataFrame").setMaster("local")
val spark=SparkSession.builder().appName("CreateDataFrame").config(conf).getOrCreate()
import spark.implicits._ //这里的spark不是某个包下面的东西,而是我们SparkSession.builder()对应的变量值
val peopleDF=spark.sparkContext
.textFile("file:///D:\\softInstall\\BigData\\spark-2.3.1-bin-hadoop2.6\\spark-2.3.1-bin-hadoop2.6\\examples\\src\\main\\resources\\people.txt")
.map(_.split(",")).map(attributes => Person(attributes(0), attributes(1).trim.toInt)).toDF()
//从文本文件创建Person对象的RDD,将其转换为DataFrame
peopleDF.createOrReplaceTempView("people") //必须注册为临时表才能供下面的查询使用
val personsRDD=spark.sql("select name,age from people where age > 20")
personsRDD.map(t => "Name:"+t(0)+","+"Age:"+t(1)).show()
//DataFrame中的每个元素都是一行记录,包含name和age两个字段,分别用t(0)和t(1)来获取值
}
}
运行结果:
+-------------------+
| value|
+-------------------+
|Name:Michael,Age:29|
| Name:Andy,Age:30|
+-------------------+
第二种方法是,使用编程接口,构造一个schema并将其应用在已知的RDD上。
Row从原始RDD 创建s的RDD;
创建由与步骤1中创建的RDD中的行结构匹配的StructType表示的模式。
Row通过createDataFrame提供的方法将模式应用于s 的RDD SparkSession。
import org.apache.spark.SparkConf
import org.apache.spark.sql.{Row, SparkSession}
import org.apache.spark.sql.types._
/**
* 编程方式定义RDD模式
* @author xjh 2018.11.28
*/
object RDDToDataFrame2 {
def main(args: Array[String]): Unit = {
val conf=new SparkConf().setAppName("RDDToDataFrame2").setMaster("local")
val spark=SparkSession.builder().appName("RDDToDataFrame2").config(conf).getOrCreate()
import spark.implicits._
//创建RDD
val peopleRDD=spark.sparkContext.textFile("file:///D:\\softInstall\\BigData\\spark-2.3.1-bin-hadoop2.6\\" +
"spark-2.3.1-bin-hadoop2.6\\examples\\src\\main\\resources\\people.txt")
//定义一个模式字符串
val schemaString="name age"
//根据模式字符串生成模式schema
val fields = schemaString.split(" ")
.map(fieldName => StructField(fieldName, StringType, nullable = true))
val schema=StructType(fields)
//将RDD(人员)的记录转换为行
val rowRDD=peopleRDD.map(_.split(",")).map(attributes=>Row(attributes(0), attributes(1).trim))
//将模式应用于RDD
val peopleDF=spark.createDataFrame(rowRDD,schema)
//使用DataFrame创建临时视图
peopleDF.createOrReplaceTempView("people")
//SQL可以在使用DataFrames创建的临时视图上运行
val results = spark.sql("SELECT name,age FROM people")
// results.map(attributes => "name: " + attributes(0)+","+"age:"+attributes(1))
results.map(attributes => "name: " + attributes(0)+","+"age:"+attributes(1)).show()
//官网上这句运行报错,需添加rdd 但是这样又不能写show()
}
}
运行结果:
+--------------------+
| value|
+--------------------+
|name: Michael,age:29|
| name: Andy,age:30|
| name: Justin,age:19|
+--------------------+
博客参考:http://spark.apache.org/docs/2.3.0/sql-programming-guide.html#datasets-and-dataframes https://blog.csdn.net/weixin_43909426/article/details/86141232#commentBox