版权声明:本作品采用知识共享 署名-非商业性使用 3.0 中国大陆 许可协议进行许可。 https://blog.csdn.net/jinping_shi/article/details/52281127
问题起因
学长之前用Java写了一个程序,有两个文档,其中一个文档是regular expression,大概有8万行,每一行是一个regular expression,我们称之为pattern;另一个文档其实是文件夹里的一个,该文件夹里的所有文档都是从twitter上抓取下来的数据,数量从7万~30万不等。文件夹中的每一个文档代表一个topic,共有8个文档,即8个topic.
目的:
以上问题跟统计词频类似。程序用的是常规的嵌套循环,如下:
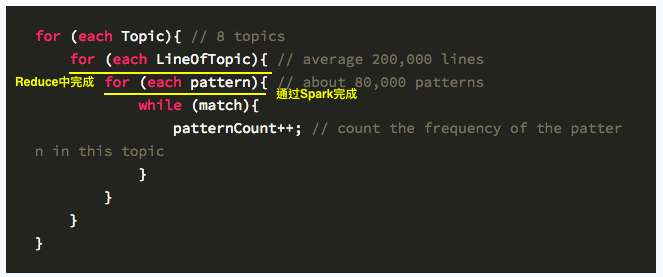
for (each Topic){
for (each LineOfTopic){
for (each pattern){
while (match){
patternCount++;
}
}
}
}一共有8个topic,每个topic的行数平均约20万,pattern数量约8万,以上代码一共需要循环8 × 200000 × 80000 = 1.28 × 10 11
整个程序看起来跟MapReduce的经典例子WordCount很像,于是我觉得用MapReduce的方法可以优化一下。但其实,我没有学过Java,也没有学过并行运算。算是学过MapReduce,在Data Mining的课上有MapReduce的讲解和上机作业。但是上机讲解我有事没有去上课,然后我就去爬山了,等到下山当天才发现第二天就是MapReduce作业的deadline…
MapReduce与Spark
Apache Spark是由加州大学伯克利分校AMPLab开发的用于处理大数据处理的框架,可以在上面实现MapReduce. spark是『闪光,闪烁』的意思,表示Spark处理数据其实很快哦!
据资料讲,Spark比Hadoop更高,更快,更强。之前Data Mining课程上我们实现MapReduce应用时用的是Hadoop,第二年老师就换成Spark了。
没有打算在这里介绍MapReduce和Spark,因为我也不是很懂。我参考的资料并且觉得比较好的有下面这些:
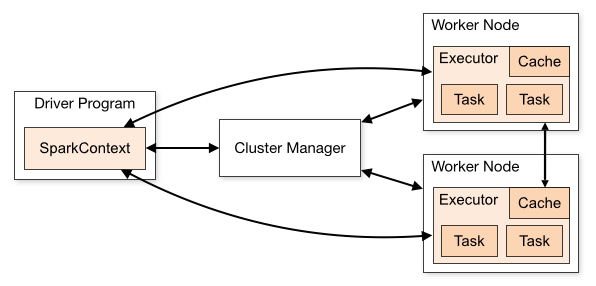
一个Saprk应用是b运行包含了一个在用户定义的main函数中的驱动程序(driver program),然后在集群(cluster)上并行执行各种操作。driver program由SaprkContext对象定义,所以要使用Spark首先要用SparkContext创建一个driver program,然后才在该驱动程序上运行cluster. 而运行cluster时Spark要先连接Cluster Manager来分配资源。一旦连接上Cluster Manager,Saprk会在这个cluster的每一个节点(node)上建立executor. executor是用于处理数据计算数据存储数据的处理器(processor)。之后Spark会将用户写的代码发送到各个节点的executor上。这时,executor有了代码就可以执行各种操作了,Spark让executor执行指定操作(由代码决定)的过程叫做任务(task)。下图是Spark执行一个任务的框架图。
程序优化
创建Spark on Java
我没有学过Java,因此只能一步一步照着各种文档操作。Spark on Java是通过Maven建立的(Maven是什么?我不懂……)。创建Maven时官方文档说需要在pom.xml中加上如下信息:
<dependencies >
<dependency >
<groupId > org.apache.spark</groupId >
<artifactId > spark-core_2.11</artifactId >
<version > 2.0.0</version >
</dependency >
</dependencies > 但我使用NetBeans 8.1添加以上信息后编译没有通过,后来网上查到还需要在pom.xml中的properties节点下添加以下内容才可以(不知道原因):
<spark.version > 2.0.0</spark.version > 首先在使用到Spark的函数中创建driver program.
SaprkConf conf = new SaprkConf().setAppName("countPatternPerTopic" ).setMaster("local[4]" );
JavaSparkContext sc = new JavaSparkContex(conf);上面代码中的变量sc就是driver program啦!
读取数据
Spark读取数据很简单:
JavaRDD<String> patternRDD = sc.textFile(filePath);注意到text是一个RDD. 以上代码会将文本一次性全部读入内存,然后自动按行分割。
map与reduce操作
map操作将数据分为若干子数据集,使得Spark可以将这些数据集分配到不同的节点上执行并行操作。执行map操作后返回的是RDD数据类型。Spark的map操作有很多种,这里用的是mapToPair ,返回的是一个pair RDD,即Key/Value结构。
JavaPairRDD<String, Integer> PattPair = patternRDD.mapToPair(user_defined_func);上述代码中的JavaPairRDD<String, Integer>表示这个pair RDD的key是String类型,即pattern名称;value是int类型,即pattern的出现次数。user_defined_func是自己定义的map算子,它的输入默认是文本的每一行。
我的问题是:有一个pattern文档,有若干tweet文档,计算pattern文档中的每一个pattern在每一个tweet文档中出现次数。相当于是给定一个word list,统计这个word list中的每个单词的词频。
如果只是统计word list的词频,那比较简单,可以直接用Spark的WordCount例子统计出词频,然后再用Spark提供的filter函数过滤掉不在word list中的单词即可。
但目前并不是简单统计词频,这个任务还有一个正则表达式匹配的过程。最开始的想法是:对pattern文档做一个map操作,得到Pattern RDD,同时生成tweet文档的Tweet RDD,这样得到两个RDD,然后在Pattern RDD的map函数中对tweet的RDD做统计 。像是这样:
上图中,分别生成了两个RDD,但只对Pattern RDD做map和reduce操作,且在Pattern RDD的map中 引用了Tweet RDD. 注意到Saprk中所有的操作都是在抽象数据类型RDD中进行,因此map和reduce其实是RDD的对象(上面的代码中可以看到),因此图中的map操作实际上是在Pattern RDD中引用了Tweet RDD.
听起来好完美,然而并不是。Saprk中RDD不可以嵌套,具体来说就是不可以在map或reduce操作中引用另一个RDD . 因为RDD是不可序列化的(non-serializable)。Spark要将任务分配到不同的节点,需要序列化所有用到的变量,然后再反序列化(其实我并不懂什么是java 的序列化……)。如果这样操作会报『任务未序列化的错误』。
因为对Java不熟,对Spark也不熟,因此我用了很直接的方法:只对Pattern做map操作,在Pattern RDD的reduce操作中遍历每条tweet,统计当前pattern在该tweet文档中出现的次数。即将原来代码中的三个for循环缩减到两个,原来pattern的循环通过Spark的分布式计算来完成,原来对tweet的循环放到了Pattern RDD的里面完成。
但是这样看起来效率仍然很低,只是对其中一个文档进行MapReduce的处理,而且还是pattern文档,通常tweet文档中的tweet数量会远大于pattern数量,这样与原来代码相比循环次数并没有降低多少。不过短时间我想不出其它办法了,当我测试完成后,8个topic已经跑完6个了。
其实可以将tweet文档分成若干份物理文档,然后统计pattern出现的次数,最后再合并。但如果可以自动将文档分割为什么要手动呢?而且我发现实验室的那些人,跑数据的过程正好是休息的过程,开会时可以跟老师说『数据还在跑』,何乐而不为呢?
测试结果
只在本机上做了测试,不知道如果布设多台机器会不会更快一点呢? Spark优化:
pattern数量:88028
topic数量:1(即只有一个tweet文档)
tweet数量:67883
测试环境:
时间:约10个小时
原始代码:
pattern数量:88028
topic数量:1(即只有一个tweet文档)
tweet数量:67883
测试环境:Ubuntu 14.04 64bit 16GB
时间: 38个小时
虽然用了Spark仍然要跑10个小时,但是毕竟缩短了将近20个小时啊!
代码
import org.apache.spark.api.java .JavaSparkContext;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.SparkConf;
import scala.Tuple2;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.logging.Level;
import java.util.logging.Logger;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public static void countPatternsPerTopicMapReduce (String pattPath, String topsPath, String outPath){
SparkConf conf = new SparkConf().setAppName("countPatternsPerEmotion" ).setMaster("local[4]" );
JavaSparkContext sc = new JavaSparkContext(conf);
}
try {
String line = "" ;
int size = 0 ;
BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream(topsPath), "UTF8" ));
ArrayList<String> textList = new ArrayList<>();
while ((line = br.readLine()) != null ){
line = line.toLowerCase().trim();
textList.add(line);
}
int size = textList.size();
class GetPattPair implements PairFunction<String, String, Integer> {
public Tuple2<String, Integer> call (String s) {
int patCount = 0 ;
for (int i = 0 ; i < size; i++){
String text = textList.get(i);
Matcher matcher;
matcher = Pattern.compile(s).matcher(text);
while (matcher.find()) {
patCount++;
}
}
return new Tuple2<String, Integer>(s, patCount);
}
}
JavaRDD<String> patterns = sc.textFile(pattPath);
JavaPairRDD<String, Integer> PattPair = patterns.mapToPair(new GetPattPair());
JavaPairRDD<String, Integer> PattCount = PattPair.reduceByKey(new Function2<Integer, Integer, Integer>() { public Integer call (Integer a, Integer b) { return a + b; }} );
} catch (UnsupportedEncodingException ex) {
Logger.getLogger(CountPatternsPerEmotion.class.getName()).log(Level.SEVERE, null , ex);
} catch (FileNotFoundException ex) {
Logger.getLogger(CountPatternsPerEmotion.class.getName()).log(Level.SEVERE, null , ex);
} catch (IOException ex){
Logger.getLogger(CountPatternsPerEmotion.class.getName()).log(Level.SEVERE, null , ex);
}