����һ��Spark�й��ڲ������漰�ļ�������File��Block��Split��Task��Partition��RDD�Լ��ڵ�����Executor����core��Ŀ�Ĺ�ϵ��
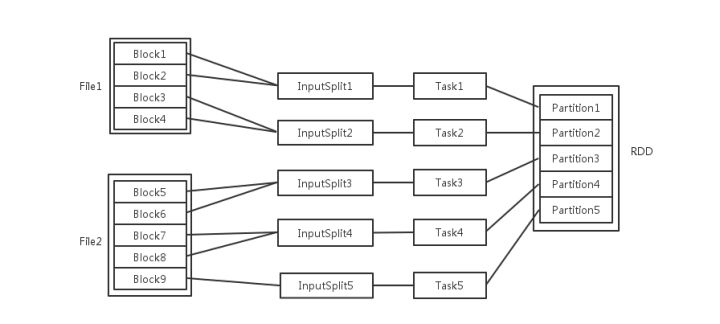
��������Զ���ļ�����ʽ�洢�� HDFS �ϣ�ÿ�� File �������˺ܶ�飬��Ϊ Block���� Spark ��ȡ��Щ�ļ���Ϊ����ʱ������ݾ������ݸ�ʽ��Ӧ�� InputFormat ���н�����һ���ǽ����ɸ� Block �ϲ���һ�������Ƭ����Ϊ InputSplit��ע�� InputSplit ���ܿ�Խ�ļ������Ϊ��Щ�����Ƭ���ɾ���� Task��InputSplit �� Task��һһ��Ӧ�Ĺ�ϵ�������Щ����� Task ÿ�����ᱻ���䵽��Ⱥ�ϵ�ij���ڵ��ij�� Executor ȥִ�С�
- ÿ���ڵ������һ������ Executor��
- ÿ�� Executor ������ core ��ɣ�ÿ�� Executor ��ÿ�� core һ��ֻ��ִ��һ�� Task ��
- ÿ�� Task ִ�еĽ������������Ŀ�� RDD ��һ�� partiton��
ע��: ����� core ������� core �����ǻ��������� CPU �ˣ���������Ϊ���� Executor ��һ�������̡߳�
�� Task ��ִ�еIJ����� = Executor ��Ŀ * ÿ�� Executor ������
���� partition ����Ŀ��
- �������ݶ���Σ����� sc.textFile�������ļ�������Ϊ���� InputSplit �ͻ���Ҫ���ٳ�ʼ Task��
- �� Map �� partition ��Ŀ���ֲ��䡣
- �� Reduce �Σ�RDD �ľۺϻᴥ�� shuffle �������ۺϺ�� RDD �� partition ��Ŀ����������йأ����� repartition ������ۺϳ�ָ��������������һЩ�����ǿ����õġ�
���ߣ����D��
���ӣ�https://www.zhihu.com/question/33270495/answer/93424104
��Դ��֪��