Spark 是 UC Berkeley AMP lab (加州大学伯克利分校的 AMP 实验室)所开源的类 Hadoop MapReduce 的通用并行计算框架,Spark 拥有Hadoop MapReduce 所具有的优点;但不同于 MapReduce 的是 Job中间输出结果可以保存在内存中,从而不再需要读写 HDFS ,因此 Spark能更好地适用于数据挖掘与机器学习等需要迭代的 MapReduce 的算法。Spark 是 Scala 编写,方便快速编程。
中间结果输出 :基于MapReduce的计算框架通常会将中间结果输出到磁盘上,进行存储和容错。出于任务管道承接的考虑,当一些查询翻译到MapReduce任务时,往往会产生多个Stage,而这些串联的Stage又依赖于底层文件系统(如HDFS)来存储每一个Stage的输出结果。
Spark是MapReduce的替换方案,而且兼容HDFS,Hive,可融入Hadoop的生态系统中,以弥补MapReduce的不足。
处理一些迭代运算,要对HDFS进行频繁的读写,效率较低。
Spark
都是分布式计算框架,Spark基于内存,MR基于HDFS。Spark处理数据的能力一般是MR的10倍以上,Spark中除了基于内存计算外,还有DAG有向无环图来切分任务的执行先后顺序 。
Spark支持Java、Python和Scala的API,还支持超过80种高级算法,使用户可以快速构建不同的应用。而且Spark支持交互式的Python和Scala的shell,可以非常方便地在这些shell中使用Spark集群来验证解决问题的方法。
多用于本地测试,如在eclipse,idea中写程序测试等。
Standalone是Spark自带的一个资源调度框架,它支持完全分布式 ( master, worker )
Hadoop生态圈中的一个资源调度框架,Spark也可以基于Yarn来计算(基于Yarn来进行资源调度,必须实现ApplicationMaster 接口,Spark实现了这个接口)
类似于Yarn的一个资源调度框架
Spark组成(BDAS):全称伯克利数据分析栈,通过大规模集成算法,机器,人之间展现大数据应用的一个平台。也是处理大数据,云计算,通信的技术解决方案。
它主要组件有:
SparkCore 将分布式数据抽象为弹性分布式数据集(RDD),实现了应用任务调度,RPC,序列化和压缩,并给运行在其上的上层组件提供API。
SparkSQL Spark Sql是Spark来操作结构化数据的程序包,可以让我们使用SQL的方式来查询数据。Spark支持 多种数据源,包含Hive表,parquest以及JSON等内容。
SparkStreaming Spark提供的实时数据进行流式计算的组件
MLlib 提供常用机器学习算法的实现库
GraphX 提供一个分布式图计算框架,能高效进行图计算
BlikDB 用于在海量数据上进行交互式SQL的近似查询引擎
Tackyon 以内存为中心高容错的分布式文件系统
概念 :RDD(Resilient Distributed Dateset) 弹性分布式数据集
RDD的五大特性:
RDD是由一系列的partition组成的
函数是作用在partition(spilt)上的
RDD之间有一系列的依赖关系
分区器是作用在K,V格式的RDD上
RDD提供了一系列最佳的计算位置
单词统计RDD理解图:
注意:
-----如果RDD里面存储的数据都是二元组对象,那么这个RDD我们称为K,V格式的RDD.
---- partition数量,大小没有限制,体现了RDD的弹性
---- RDD之间存在依赖关系,可以基于上一个RDD重新计算出RDD
---- 一系列partition组成了RDD,partition分布在不同的节点上
---- RDD提供计算的最佳位置,体现了数据本地化。体现了大数据中的计算向数据靠拢 的理念
以上图中有四个机器节点,Driver和Worker是启动在节点上的进程,运行在JVM中的进程。
Driver和集群节点之间有频繁的通信
Driver负责任务(tasks)的分发和结果的回收,任务的调度。如果task的计算结果非常大就不要回收了,会造成OOM
Worker是Standalone资源调度框架里面资源管理的从节点。也是JVM进程 (Yarn中的NodeManager)
Master是Standalone资源调度框架里面资源管理的主节点。也是JVM进程 (Yarn中的ResourceManager)
创建SparkConf对象(可设置Application name 和运行模式 及资源需求)
创建SparkContext对象(传入sparkConf)
基于Spark的上下文创建一个RDD,对RDD进行处理
应用程序中要有Action类算子触发Transformation算子执行
关闭Spark上下文对象SparkContext
概念 :转换算子延迟执行,也叫做懒加载。
package com.shsxt.spark
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Sp_Transformation {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf()
//设置运行模式和Application名称
sparkConf.setMaster("local").setAppName("test")
//构建上下文对象
val context = new SparkContext(sparkConf)
val lines: RDD[String] = context.textFile("./wc.txt")
//过滤符合条件的记录数,true保存,false舍弃
val word: RDD[String] = lines.filter(x=>{
x.contains("l")
})
// word.foreach(println) //输出结果 wcb wa cool l love you
//将一个RDD中的每个数据项,通过map中的函数映射变为一个新的元素
//特点:输入一条,输出一条
val data: RDD[(String, Int)] = lines.map(x=>(x,1))
// data.foreach(println) //输出结果 (wcb wa cool,1)
// (hehe heihei,1)
// (l love you,1)
// (xixi heihei haha,1)
//先map后flat。和map类似,每个输入项可以映射成0到多个输出项
//特点:输入一条,输出多条
val str: RDD[String] = lines.flatMap(x=>x.split(" "))
//str.foreach(println) //输出结果 wcb
// wa
// cool
// hehe
// heihei ......
//随机抽样算子,根据传进去的小数按比例进行又放回或者无放回的抽样
val sample: RDD[String] = lines.sample(true,0.5)
//sample.foreach(println) //每次打印结果不一样
//将相同的key根据相应的逻辑进行处理
//str.map(x=>(x,1)).reduceByKey(_+_).foreach(println) //输出结果 (cool,1)
//sortByKey/sortBy 作用在K,V的RDD上,对key进行升序或者降序排序
str.map(x=>(x,1)).reduceByKey(_+_).sortBy(x=>x._2,false).foreach(println)
}
}
Action 类算 子也 是一 类 算子 (函 数)叫 做 行动 算子 , 如foreach,collect,count 等。Transformations 类算子是延迟执行,Action 类算子是触发执行。一个 application 应用程序中有几个 Action 类算子执行,就有几个 job 运行
package com.shsxt.spark
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object Sp_Active {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf()
sparkConf.setMaster("local").setAppName("test")
val context = new SparkContext(sparkConf)
val lines: RDD[String] = context.textFile("./wc.txt")
//返回数据集中的元素数。会在结果计算完成后回收到 Driver 端。
val count = lines.count()
//println(count) //运行结果为 4
//返回一个包含数据集前 n 个元素的集合。
val array: Array[String] = lines.take(2)
//array.foreach(println)
// first=take(1),返回数据集中的第一个元素。
val str = lines.first()
//println(str)
//foreach 遍历 不再介绍
//collect 将计算结果回收到Driver
val array01: Array[String] = lines.collect()
array01.foreach(println)
}
}
控制算子有三种: cache ,persist ,checkpoint ,这些算子都可以将RDD持久化,持久化的单位是partition 。cache和persist都是懒执行的,必须有一个Action算子触发执行。checkpoint算子 不仅能将RDD持久化到磁盘,还能切断RDD之间的依赖关系 。
默认将RDD的数据持久化到内存中,cache是懒执行。
cache() = persist(StorageLevel.Memory_only)
测试代码:
package com.shsxt.spark.scala
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Sp_Cache {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf()
sparkConf.setMaster("local").setAppName("cache")
val context = new SparkContext(sparkConf)
var lines: RDD[String] = context.textFile("./NASA_access_log_Aug95")
//使用cache
lines = lines.cache()
val startTime = System.currentTimeMillis()
//触发算子触发 cache
var n = lines.count()
println(n)
val endTime = System.currentTimeMillis()
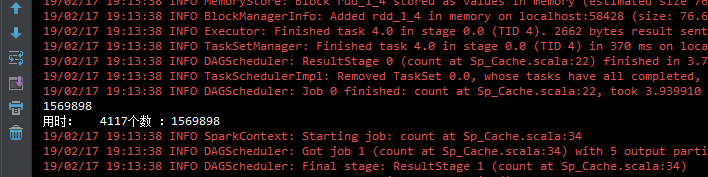
println("用时: "+(endTime-startTime) +"个数 :"+n)
val startTime1 = System.currentTimeMillis()
n = lines.count()
val endTime1 = System.currentTimeMillis()
println("用时: "+(endTime1-startTime1) +"个数 :"+n)
context.stop()
}
}
打印结果:
计算效率提高很明显
java 代码实现:
package com. shsxt. spark. java ;
import org. apache. spark. SparkConf;
import org. apache. spark. api. java. JavaRDD;
import org. apache. spark. api. java. JavaSparkContext;
import org. apache. spark. storage. StorageLevel;
public class Cache {
public static void main ( String args[ ] ) {
SparkConf sparkConf = new SparkConf ( ) ;
sparkConf. setMaster ( "local" ) . setAppName ( "cache" ) ;
JavaSparkContext context = new JavaSparkContext ( sparkConf) ;
JavaRDD< String> = context. textFile ( "./NASA_access_log_Aug95" ) ;
rdd = rdd. cache ( ) ;
rdd. persist ( StorageLevel. DISK_ONLY_2 ( ) ) ;
long startTime = System. currentTimeMillis ( ) ;
long l = rdd. count ( ) ;
long endTime = System. currentTimeMillis ( ) ;
System. out. println ( "总数:" + l+ " " + "用时:" + ( endTime- startTime) ) ;
startTime = System. currentTimeMillis ( ) ;
l = rdd. count ( ) ;
endTime = System. currentTimeMillis ( ) ;
System. out. println ( "总数:" + l+ " " + "用时:" + ( endTime- startTime) ) ;
}
}
可以指定持久化的级别。最常用的是Memory_only和Memory_And_DIsk. "_2"表示有副本数 。
持久化级别列举:
class StorageLevel private (
private var _useDisk: Boolean,
private var _useMemory: Boolean,
private var _useOffHeap: Boolean,
private var _deserialized: Boolean,
private var _replication: Int = 1 ) ##可以自定义
object StorageLevel {
val NONE = new StorageLevel ( false , false , false , false )
val DISK_ONLY = new StorageLevel ( true , false , false , false )
val DISK_ONLY_2 = new StorageLevel ( true , false , false , false , 2 )
val MEMORY_ONLY = new StorageLevel ( false , true , false , true )
val MEMORY_ONLY_2 = new StorageLevel ( false , true , false , true , 2 )
val MEMORY_ONLY_SER = new StorageLevel ( false , true , false , false )
val MEMORY_ONLY_SER_2 = new StorageLevel ( false , true , false , false , 2 )
val MEMORY_AND_DISK = new StorageLevel ( true , true , false , true )
val MEMORY_AND_DISK_2 = new StorageLevel ( true , true , false , true , 2 )
val MEMORY_AND_DISK_SER = new StorageLevel ( true , true , false , false )
val MEMORY_AND_DISK_SER_2 = new StorageLevel ( true , true , false , false , 2 )
val OFF_HEAP = new StorageLevel ( false , false , true , false )
1.cache和persist都是懒执行,必须有一个行动类算子触发执行
2.cache和persist算子的返回值可以赋值给一个变量,在其他job中直接使用这个变量就是使用持久化的数据了,持久化的单位是partition
3.cache和persist算子后不能立即紧跟action算子
例如: rdd.cache().count() 返回的不是持久化的 RDD,而是一个数值了
checkpont将RDD持久化到磁盘,还可以切换RDD之间的依赖关系。
checkpoint的执行原理:
1.当RDD的job执行完毕后,会从finalRDD从后往前回溯
2.当回溯到某个RDD调用了checkpoint方法,会对当前的RDD做一个标记
3.Spark框架会自动启动新的job,重新计算这个RDD的数据,将数据持久化到HDFS上。
RDD执行checkpoint之前,最好对这个RDD进行cache,这样新启动的Job只需要将内存中的数据拷贝到HDFS上即可,省去了重新计算的时间。
package com. shsxt. spark. java;
import org. apache. spark. SparkConf;
import org. apache. spark. api. java. JavaRDD;
import org. apache. spark. api. java. JavaSparkContext;
import java. util. Arrays;
public class CheckPoint {
public static void main ( String args[ ] ) {
SparkConf sparkConf = new SparkConf ( ) ;
sparkConf. setMaster ( "local" ) . setAppName ( "checkPoint" ) ;
JavaSparkContext sc = new JavaSparkContext ( sparkConf) ;
sc. setCheckpointDir ( "./checkPoint" ) ;
JavaRDD< Integer> = sc. parallelize ( Arrays. asList ( 1 , 2 , 3 ) ) ;
javaRDD. cache ( ) ;
javaRDD. checkpoint ( ) ;
javaRDD. count ( ) ;
sc. stop ( ) ;
}
}
分为Spark自带的资源框架standalone和基于Yarn的两种搭建方式
这里三台节点,分配node01为master,node02,node03为Worker节点
1.下载安装包,解压(我这边下载的是spark-1.6,结合hadoop-2.6.x)
下载地址:https://archive.apache.org/dist/spark/spark-1.6.0/
解压命令: tar -zvxf …
2.改名,名字太长麻烦(你随意)
命令:
mv spark-1.6.0-bin-hadoop2.6.tgz spark-1.6.0
3.进入到安装包的conf目录下,修改slaves.template,添加从节点
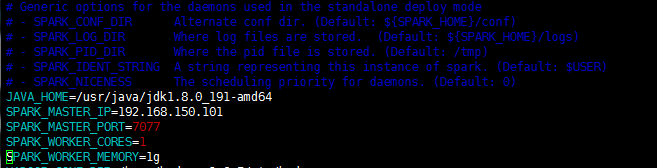
4.修改spark-env.template
mv spark-env.template.sh spark-env.sh
JAVA_HOME:配置 java_home 路径
5.同步到其它节点上
[root@node01 home]# scp -r spark-1.6.0/ node02:`pwd`
[root@node01 home]# scp -r spark-1.6.0/ node03:`pwd`
6.启动集群
进入到sbin目录下,执行当前目录下的 ./start-all.sh
8080是Spark WEBUI 界面的端口,7077是Spark任务提交的端口。
Sbin目录下,编辑 start-master.sh 修改相关端口
7,Standalone提交命令
运行spark给的demo案例(模拟圆周率的生成)
bin目录下
./spark-submit --master spark://node01:7077 --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.6.0.jar 100
后面详情介绍程序提交的方式
在安装目录conf下,spark-env.template中添加 hadoop的安装目录下的相关配置
其他步骤和Standalone一样。
关闭,standalone运行模式
启动HDFS和Yarn
./spark-submit --master yarn --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.6.0.jar 100