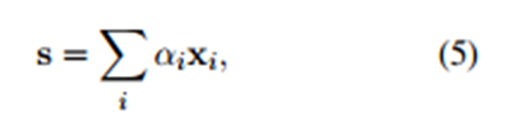һ����ϵ��ȡ���
��Ϣ��ȡ����ҪĿ���ǽ��ǽṹ�����ṹ����������Ȼ�����ı�ת���ɽṹ�����ݣ�Structuring������ϵ��ȡ������Ҫ����������Ҫ������ı���ʶ���ʵ�壨Entities)����ȡʵ��֮��������ϵ��
�磺���ӡ�Bill Gates is the founder of MicrosoftInc.���а���һ��ʵ���(Bill Gates, Microsoft Inc.)��������ʵ���֮��Ĺ�ϵΪFounder��
![]()

Freebase�еĹ�ϵ����
���������Ĺ�ϵ��ȡ������Ϊ�мල��ѧϰ��������ල��ѧϰ�������ල��ѧϰ�������֣�
1���мල��ѧϰ��������ϵ��ȡ�������������⣬����ѵ�����������Ч���������Ӷ�ѧϰ���ַ���ģ�ͣ�Ȼ��ʹ��ѵ���õķ�����Ԥ���ϵ���÷���������������Ҫ�������˹���עѵ�����ϣ������ϱ�ע����ͨ���dz���ʱ������
2����ල��ѧϰ������Ҫ����Bootstrapping���й�ϵ��ȡ������Ҫ��ȡ�Ĺ�ϵ���÷��������ֹ��趨��������ʵ����Ȼ������ش����ݴӳ�ȡ��ϵ��Ӧ�Ĺ�ϵģ������ʵ����
3���ල��ѧϰ��������ӵ����ͬ�����ϵ��ʵ���ӵ�����Ƶ���������Ϣ����˿�������ÿ��ʵ��Զ�Ӧ��������Ϣ��������ʵ��Ե������ϵ����������ʵ��Ե������ϵ���о��ࡣ
���������ַ�����ȣ��мල��ѧϰ�����ܹ���ȡ����Ч����������ȷ�ʺ��ٻ��ʶ����ߡ�����мල��ѧϰ�����ܵ���Խ��Խ��ѧ�ߵĹ�ע��
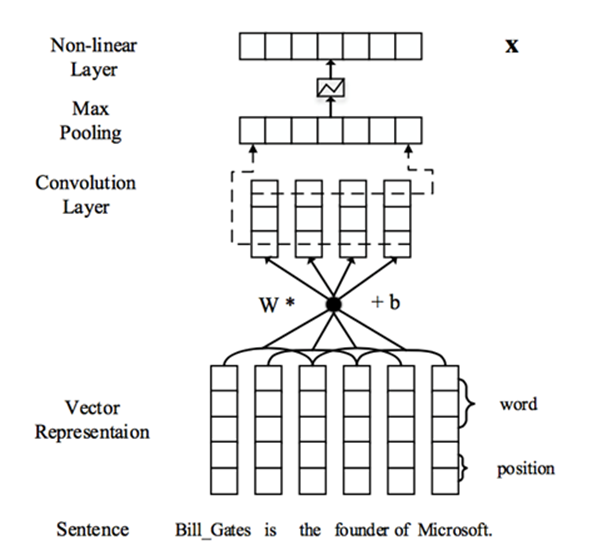
��ΪNLP�еľ��ӳ����Dz�ͬ�ģ�����CNN����������С�Dz�ȷ���ģ���ȡ����m�Ĵ�С�Ƕ��١������㱾�����Ǹ�������ȡ�㣬�����趨������F��ָ���������ٸ�������ȡ����Filter��������ij��Filter��˵������������һ��k*d��С���ƶ����ڴ��������ĵ�һ���ֿ�ʼ���������ƶ�������k��Filterָ���Ĵ��ڴ�С��d��Word Embedding���ȡ�����ij��ʱ�̵Ĵ��ڣ�ͨ��������ķ����Ա任������������ڵ�����ֵת��Ϊij������ֵ�����Ŵ��ڲ��������ƶ������Filter��Ӧ������ֵ���ϲ������γ����Filter����������������Ǿ������ȡ�����Ĺ��̡�ÿ��Filter����˲������γ��˲�ͬ��������ȡ����Pooling
�����Filter���������н�ά�������γ����յ�������һ����Pooling��֮������ȫ���Ӳ������磬�γ����ķ�����̡�
���������ж�
����1��Distant
Supervision for Relation Extraction via Piecewise Convolutional NeuralNetworks
![]()

- ����������һ���ϼ���Ҫ�ж�Bill Gates is the founder of Microsoft��仰��Bill Gates ��Microsoft������֮��Ĺ�ϵ������Ҫ�ҳ��������������ʵľ��Ӽ�{,, �� ,}������Ҫ�ж���Щ�����������ڶ��ϵ�й�ϵr�ĸ��ʡ�
- ���Ǿ��Ӽ���ÿ������m�����ʵľ���x����Ϊ�˱���������ӵ���˼����ÿ������ת��Ϊ��Ӧ��word embedding (ά��)��ͬʱ�ҳ�ÿ���������������ʵ��֮������position embeddings (ά��)��������������������������������(ά��)

![]()
�����
- ��������Ҫ���о��������ˣ���d=|w|, lΪ�������ڳ��ȣ����ԾͿ���ͼһ��������d=6 , l=2 �����ڼ���Ϊw�е�i-l+1��i�й��ɵġ����У������߽�(i<1��i>m)��ֵΪ0��
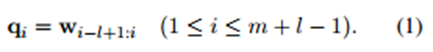
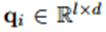
![]()
![]()
��ˣ�������ĵ�i��������������ʽ����õ���
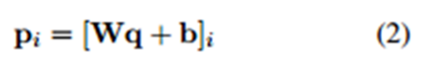
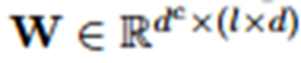
![]()
![]()
�������ػ��õ�һ����
![]()
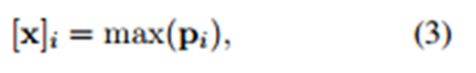
- ��ƪ�����ڳػ���ʱ��ͨ������ʵ��λ�ý� feature map ��Ϊ���ν��гػ�����Ŀ����Ϊ�˸��õIJ�������ʵ���Ľṹ����Ϣ�����ͨ�� softmax ����з��ࡣ
���������ͨ������ʵ���λ�ý����Ϊ���Σ��������ͱ��ֳ�������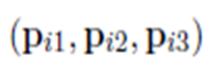
![]()
Ȼ���ٶ�ÿһ�����ػ���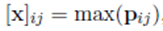
![]()
���Ž�![]()
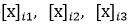 ��β���������õ�
��β���������õ�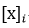
![]()
���ͨ�������Բ�tanh�õ�����
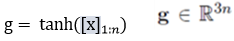
![]()
���һ��ȫ���Ӳ� 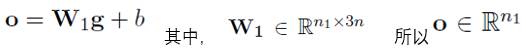
![]()
��n1�����Ĺ�ϵ��������
- ԭʼ���Ӿ���CNN�Ĵ����ͳ�Ϊ��һ�����ж��������������֮��Ϳ����ò�ͬ�ķ���ȥ�����ˡ�
- ��ƪ����ʹ���˶�ʾ��ѧϰ(multi-instance learning)�ķ�����
7.�����������в���Ϊ�ȣ�ѵ������T������
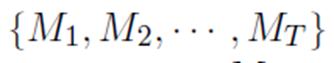
��i������qi��ʾ����
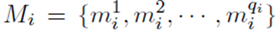
![]()
�㷨�������£�

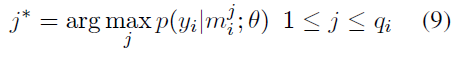
Ŀ�꺯����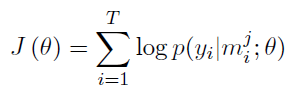
![]()
���Ŀ�꺯����ѧϰ������
����2��Neural Relation Extraction with Selective Attention over Instances (2016)
- ������ǰ�벿�ֵĴ�����ǰһƪ����һ����������������
![]()
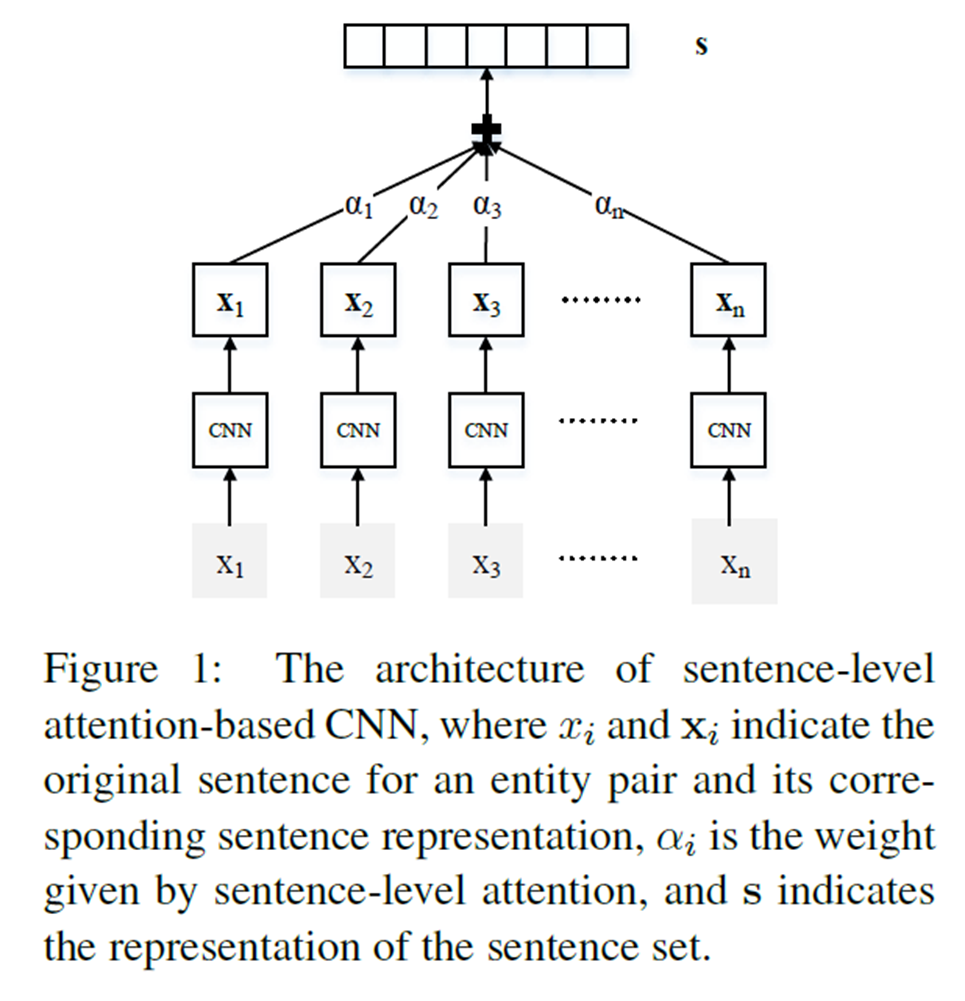
- ����ͼ��ʾ����Ҫ��������ȫ���Ӳ㱾ƪ����ʹ����ѡ���Թ�ע���ơ�
- ���ǰ�������ʵ��ľ��Ӽ���
![]() ������Щʸ����Ȩ��ͣ�
������Щʸ����Ȩ��ͣ�
- ������ѡ����������Ȩֵ�ķ��������£�
(1)ȡƽ��(AVE)�� (2)ѡ���Թ�ע(ATT)��
![]()
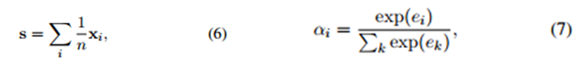
![]()
�÷�����Ҫ��Ϊ�˼��ٴ����ǩ��Ӱ�졣
- ����attention֮���s����ͨ��һ�����磺

![]()
��һ������IJ���M���ִ�����ʵ���ϵ����������ɵľ��������Ĵ�������ѧ�ϵ�����Ҳ�Ǻ�ֱ�۵ģ���ò�������������һ��softmax�㣬��ô��Ҫ��ĵľ��ǵľ��������������ijʵ���ϵ�ĸ��ʣ�
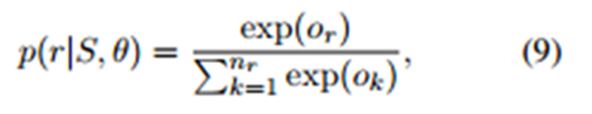
![]()
- ѡȡ�����غ�������������ݶ��½������Ż��������ѧ����������в�����
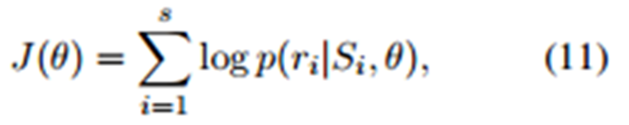
![]()
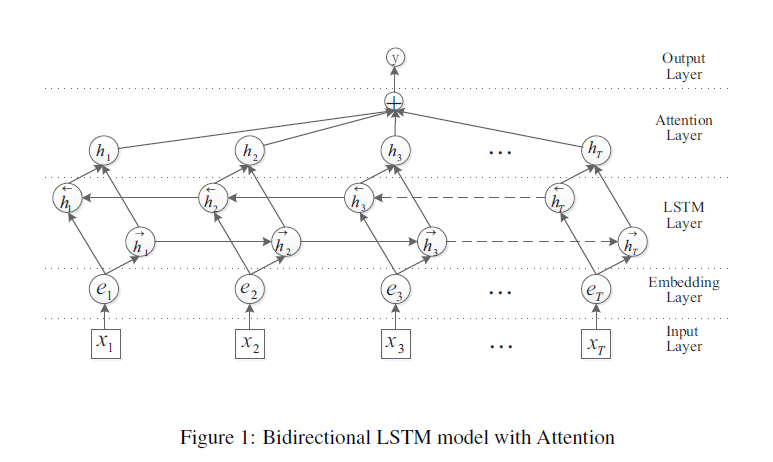
����3��Attention-Based Bidirectional Long Short-Term Memory Networks
for RelationClassification
- ��������ǰ��Ҳ�������ƵĴ�������λ����������������ʹ����LSTM�ķ�����
- ��Ҫ����ͼ���£�
![]()
- ����ֻ��Ҫ����Ĺ��ܣ�
����㣺��ԭʼ��������ò㣻
�����㣺��ÿ������ӳ�䵽һ����ά������
LSTM�㣺����BLSTM������������õ��þ��ӵ�ǿ����
��ע�㣺����һ��Ȩ����������LSTM�е�ÿһ��ʱ��ڵ�ͨ�����Ȩ����������������
����㣺������õ����������õ���ϵ���������ϡ�
����ʵ���������֤��
1��ǰ��ƪ����ʵ�飺
����ʹ�õ�������C++����Ubuntu�����²���
���룺https://github.com/thunlp/NRE
�����������룬�����ļ���Ҫ���Ե��ļ��а���CNN+ONE, PCNN+ONE,CNN+ATT, PCNN+ATT���ն�����make
���У�PCNN+ONE��Ӧ��һƪ���ģ�PCNN+ATT��Ӧ�ڶ�ƪ���ġ�
ѵ�����ݣ� ./train
�������ݣ� ./test
p.s.�����Ѿ�ѵ�������ݲ����ѱ����ģ�ͣ�����ֱ��test������û�б�Ҫÿ��������train��
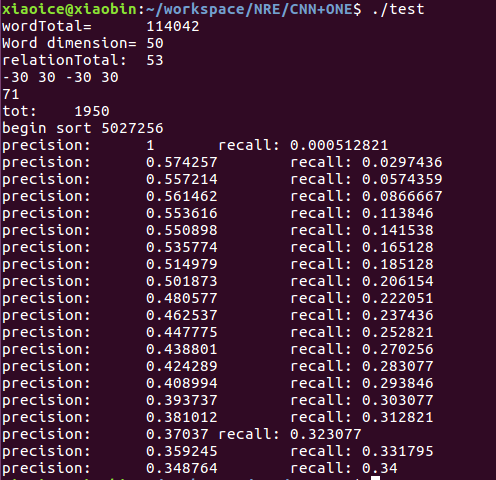
��1��CNN+ONE���
![]()
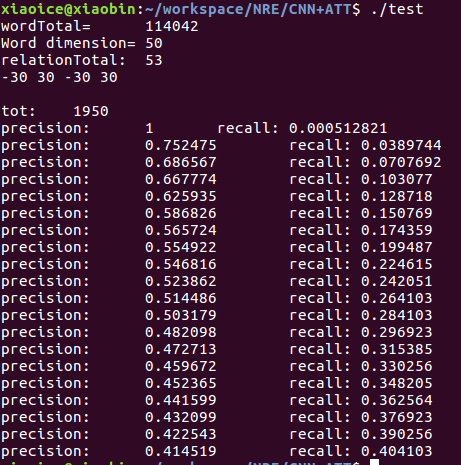
��2��CNN+ATT���
![]()
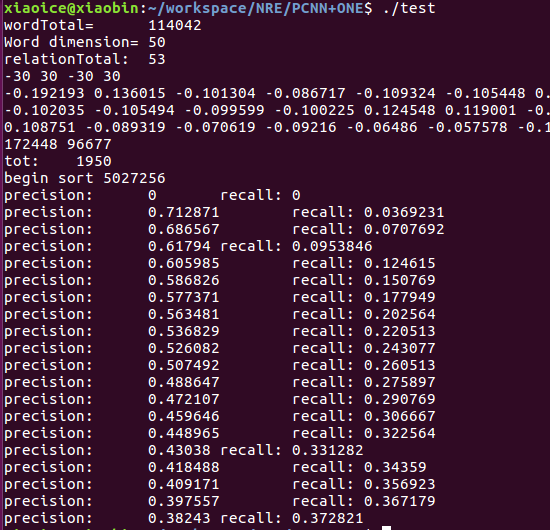
��3��PCNN+ONE���
![]()
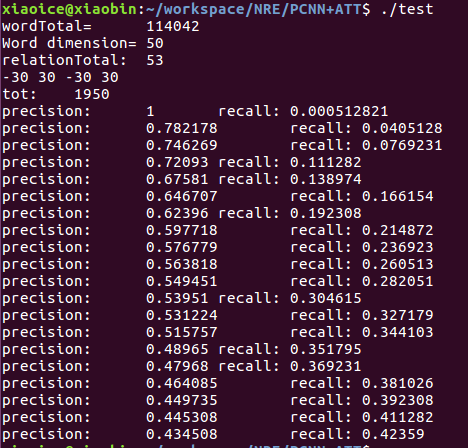
��4��PCNN+ATT���
![]()
![]()
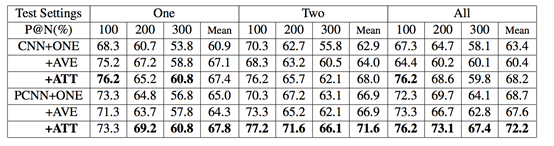
����PCNN > CNN
ATT>ONE
2������ƪ����ʵ�飺
����ƪ����ʵ��ʹ�õ�python3���ԣ���Ubuntu�����²���
�������ش��룺https://github.com/thunlp/TensorFlow-NRE
����ʹ�õ�python�汾��python2��ͬʱtensorflow�İ汾��r0.11
���ҵ����ϵ�python�汾��python3��tensorflow �İ汾��1.1.0
�ֲ������°�װ������ֻ�ܸĶ�Դ���롣
���ȣ�ubuntu��Ĭ�ϰ�װ��python2���и�2to3���ߣ�����ֱ�ӽ�python2�Ĵ���ת��Ϊpython3�Ĵ��롣
�ն����� 2to3 �Cw example.py���ܽ�example.pyת��Ϊpython3��ͬʱ����example.oy.bak�ı����ļ���
�����Ϳ��Խ����е���ش���ת��Ϊ��Ӧ��python3���ԣ��dz����㣬ʡ��һ��һ���ġ�
���ž�Ҫ��tensorflow�ˣ�����tensorflow�汾�ı䶯�Ƚϴ�����Ҫ�ĵĵط���ͦ��ģ�����ҸĶ����������������⣬�������£���ȻһЩû�����ľ�û�������ˡ�
Tensorflow �¾ɰ汾�ĸĶ�
һ��AttributeError:module 'tensorflow.python.ops.nn' has no attribute 'rnn_cell'
tf.nn.rnn_cell ===��
tf.contrib.rnn
����TypeError:Expected int32, got list containing Tensors of type '_Message' instead.
tf.concat����������λ�ã����ַ��ں���
����AttributeError:module 'tensorflow' has no attribute 'batch_matmul'
batch_matmul ===��
matmul
�ġ�AttributeError:module 'tensorflow' has no attribute 'mul'
mul ===>
multiply
�塢ValueError:Only call `softmax_cross_entropy_with_logits` with named arguments (labels=...,logits=..., ��)
ע���ĸ���labels���ĸ���logits
����AttributeError:module 'tensorflow' has no attribute 'scalar_summary'
tf.audio_summary ===�� tf.summary.audio
tf.contrib.deprecated.histogram_summary===�� tf.summary.histogram
tf.contrib.deprecated.scalar_summary===�� tf.summary.scalar
tf.histogram_summary===�� tf.summary.histogram
tf.image_summary===�� tf.summary.image
tf.merge_all_summaries===�� tf.summary.merge_all
tf.merge_summary===�� tf.summary.merge
tf.scalar_summary===�� tf.summary.scalar
tf.train.SummaryWriter===�� to tf.summary.FileWriter
�ߡ�WARNING:initialize_all_variables(from tensorflow.python.ops.variables) is deprecated and will be removed after2017-03-02.
Instructions forupdating:
Use`tf.global_variables_initializer` instead.
�������Ϳ��������ˡ�
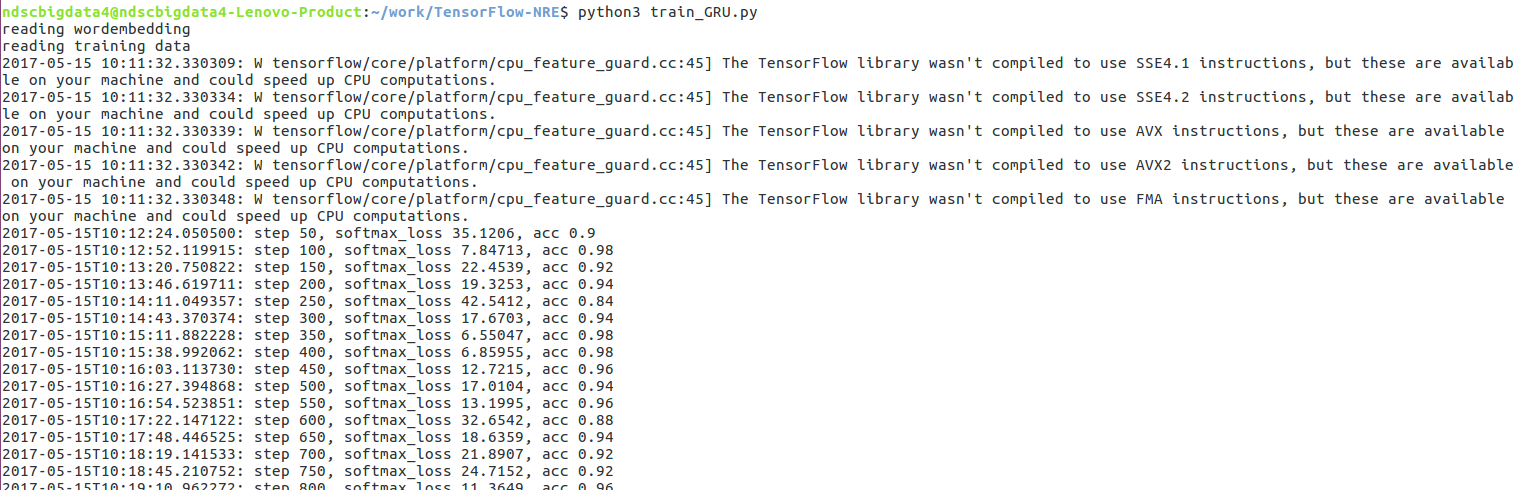
Python3 train_GRU.py
![]()
![]()
���ݱ����ģ����test.py�е�testlist��

![]()
���������
Python3test_GRU.py
���ڶ������������ҵ��ıȽϺõĽ����iter16000���������
eva luating P@Nfor iter 16000
eva luating P@Nfor one
P@100:
0.71
P@200:
0.65
P@300:
0.5866666666666667
eva luating P@Nfor two
P@100:
0.72
P@200:
0.64
P@300:
0.62
eva luating P@Nfor all
P@100:
0.74
P@200:
0.705
P@300:
0.6533333333333333
2017-05-15T16:12:42.613068
eva luating alltest data and save data for PR curve
saving all testresult...
PR curvearea:0.309841978919
2017-05-15T16:15:40.915434
P@N for all testdata:
P@100:
0.7
P@200:
0.665
P@300:
0.65
�������ҵ��ĽϺõĽ����iter10900��PR���� ���ɼ���Ч������õġ�
![]()
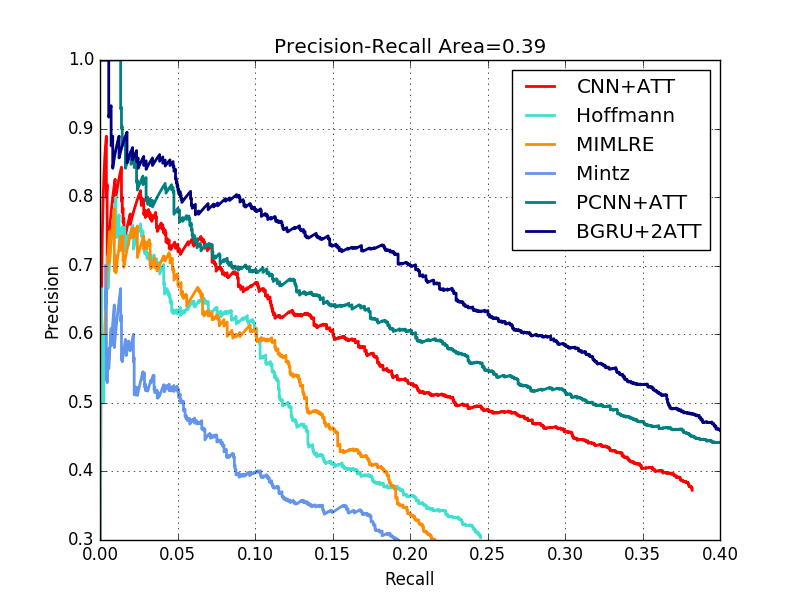
���ҵõ���PR�������£�Ч����CNN+ATT���
![]()
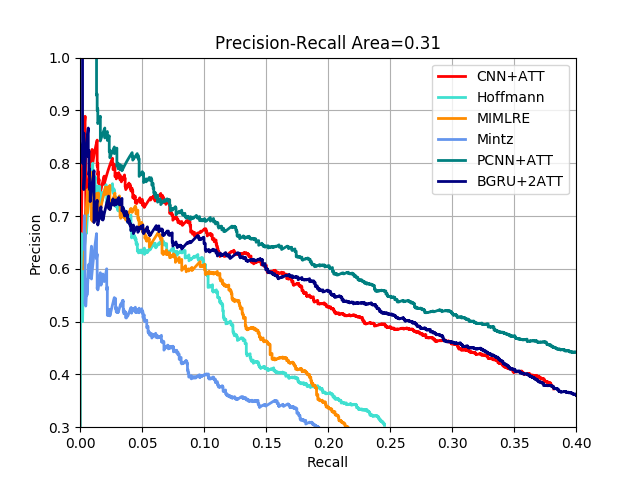
�ο����ϣ�
����1
����2
����3
http://it.sohu.com/20170402/n486130957.shtml