版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/Shrynh/article/details/87898610
问题
解决
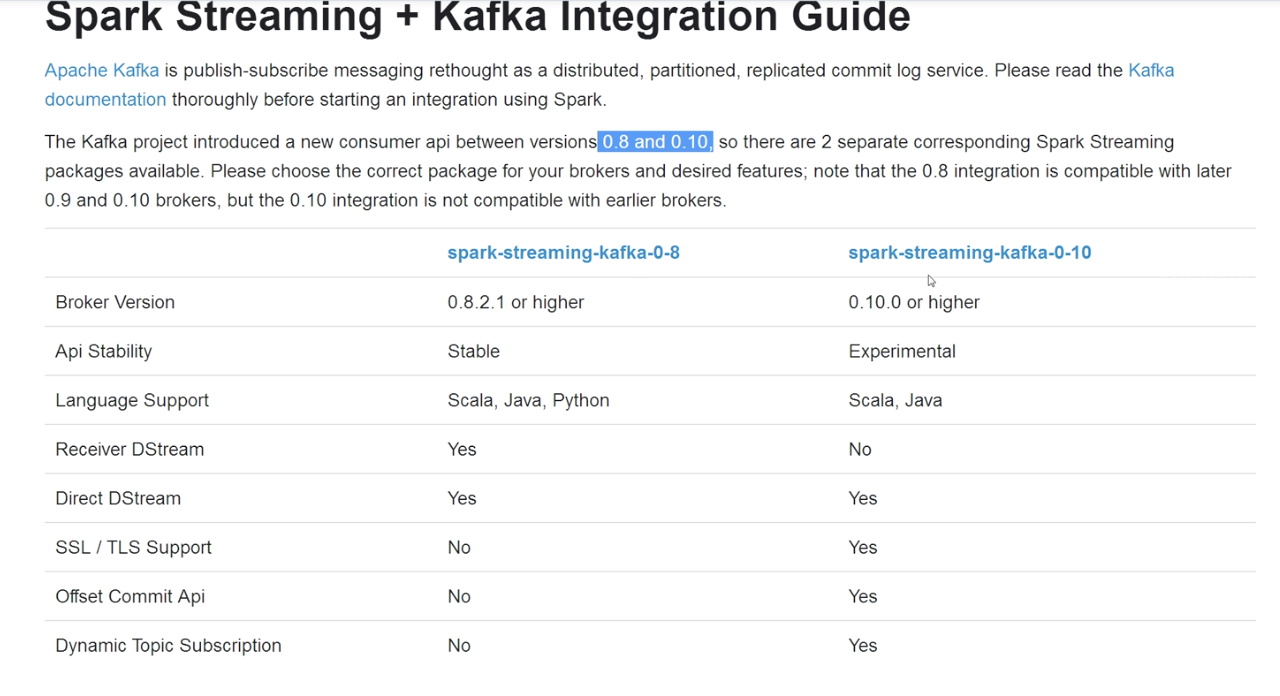
spark streaming 和storm的区别?
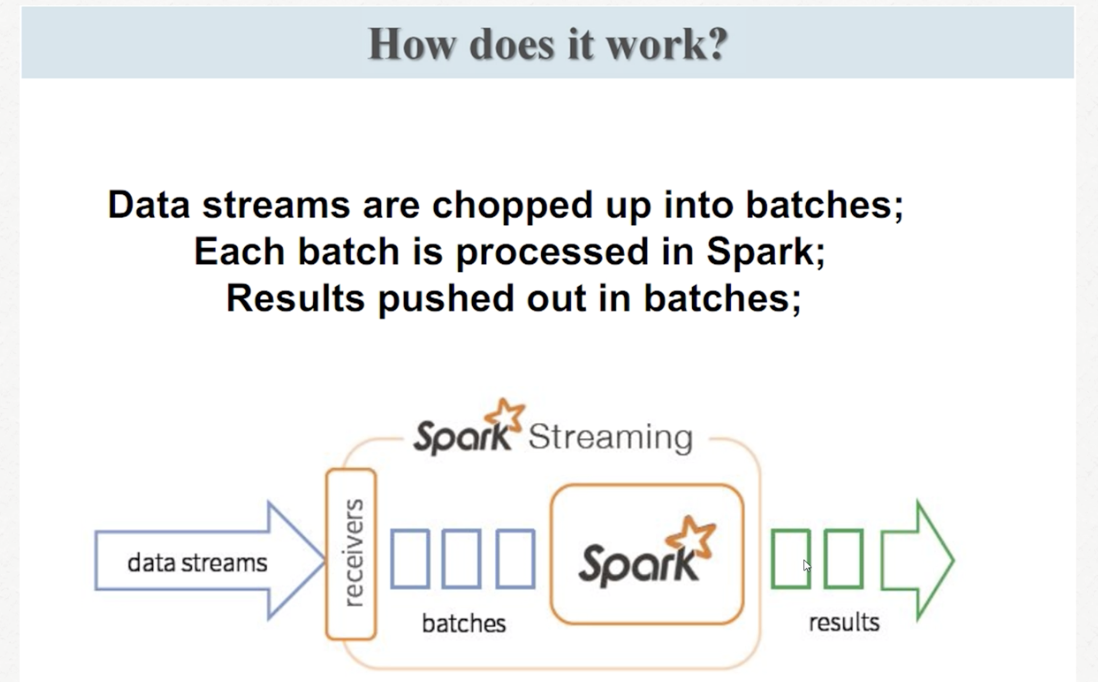
处理实时流,但是spark streaming是小量的“批处理”。就像水龙头的水过来,spark会先用一个小瓶子接着,对瓶子里的水处理之后再流向桶里;但是storm是直接水龙头来一点水就处理一点水直接流向桶里。相比之下,storm对实时流处理的延迟稍微小一点。但是一般情况下,如果对实时性要求不那么高,一般采用spark,因为spark比storm的对外服务的集成更好。
spark-sql和hive对比
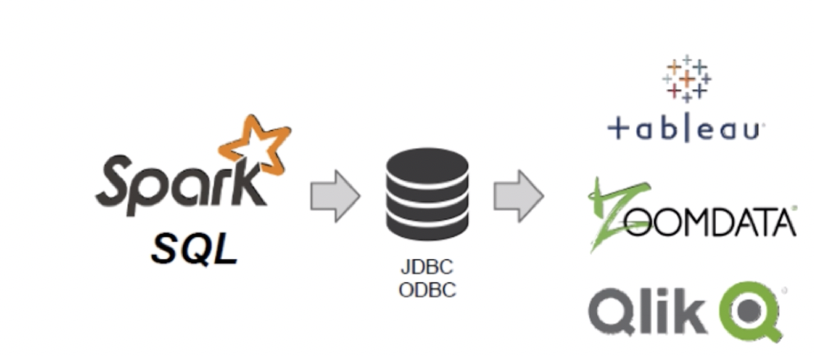
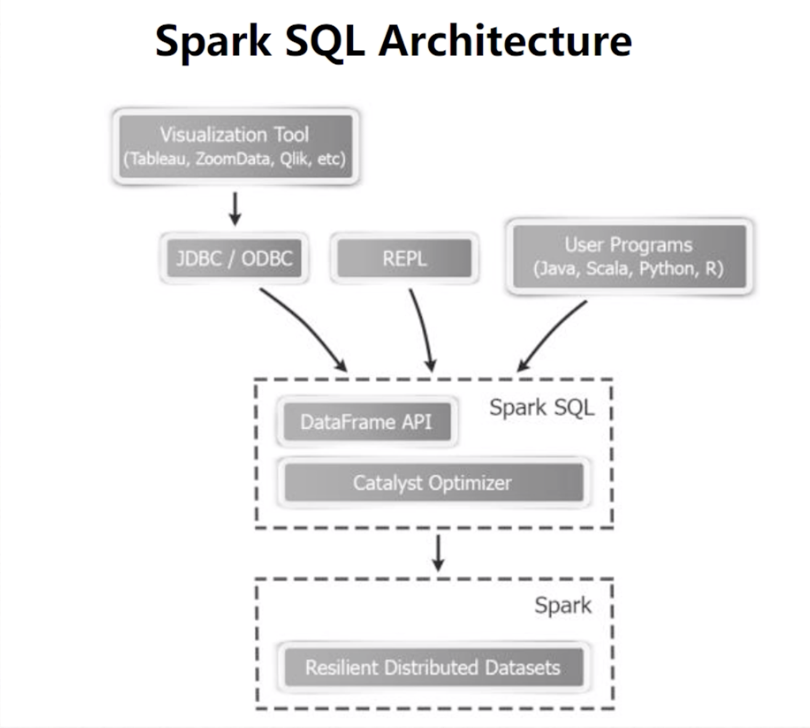
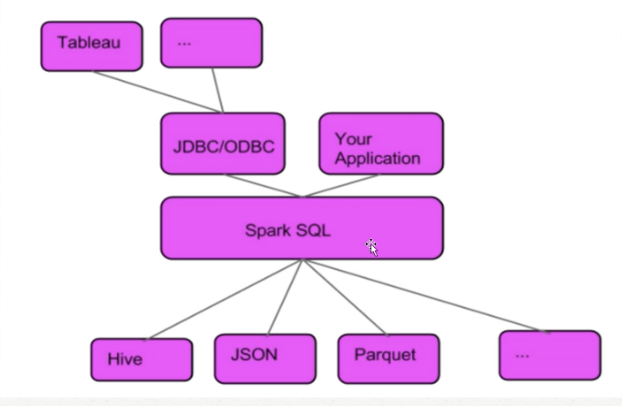
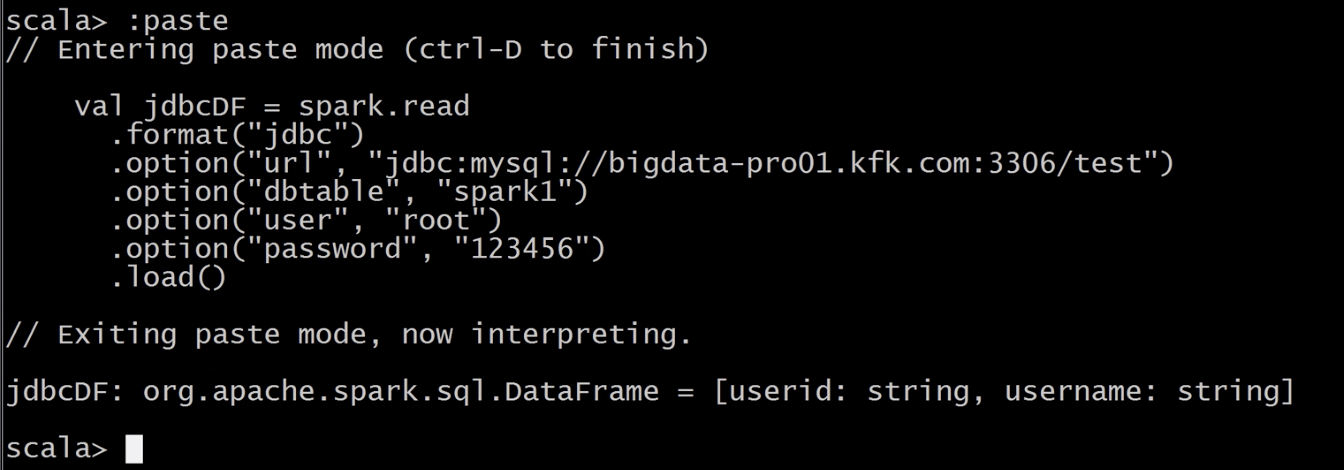
connect existing BI tools to Spark through JDBC
spark-sql binding in python , scala, java and R
spark sql is about more than sql .
spark sql可以更快地创建和运行spark程序,通过:
写更少的代码
读取更少量的数据
最困难的工作给优化器做
1) BI工具可以通过JDBC连接到spark sql;或者我们创建的应用也可以直接连接到spark sql->底层spark执行的时候支持对多种文件格式操作:Hive表、JSON、parquet格式……
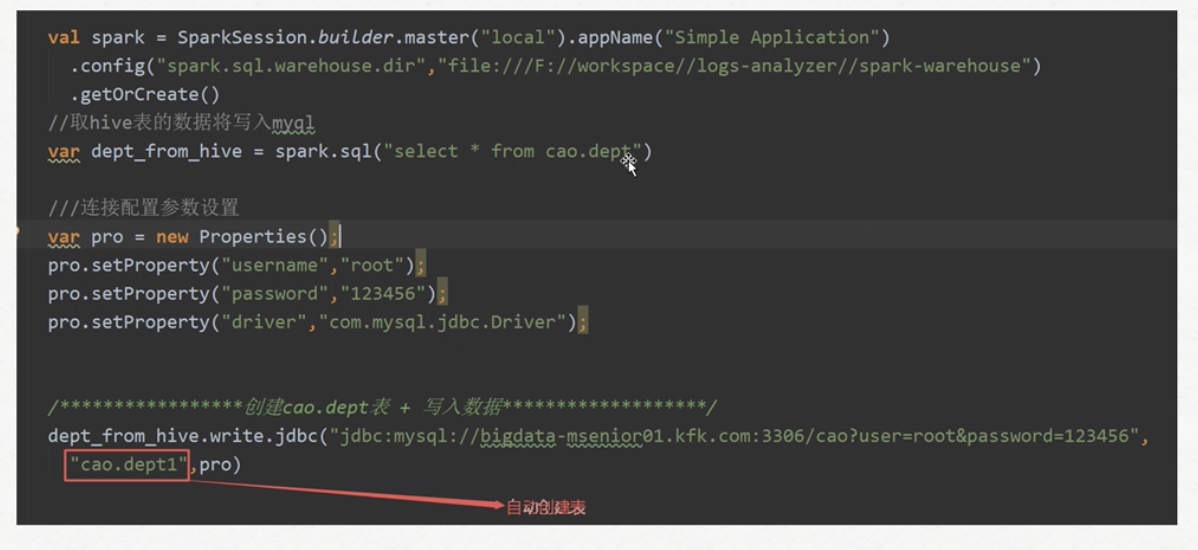
说明: 更多的应用场景是hive与hbase结合之后通过spark-sql进行离线分析:spark sql->(hive+hbase)
步骤 :
1.拷贝hive的配置文件hive-site.xml到spark的conf目录,注意检查hive-site.xml中metastore的url配置。
原因:因为spark要支持对hive的查询,需要引入hive的配置到spark的配置目录下;其次,hive的metastore配置是强制性的。
2.拷贝hive中的mysql的jar包到spark的jars目录
原因:因为spark sql要访问存在mysql上的hive的metastore信息以访问hive表。
3.检查spark-env.sh中的hadoop配置项
原因:因为hbase数据其实还是存放在hdfs上的
4.启动服务
sudo service mysqld start //启动mysql服务
步骤:
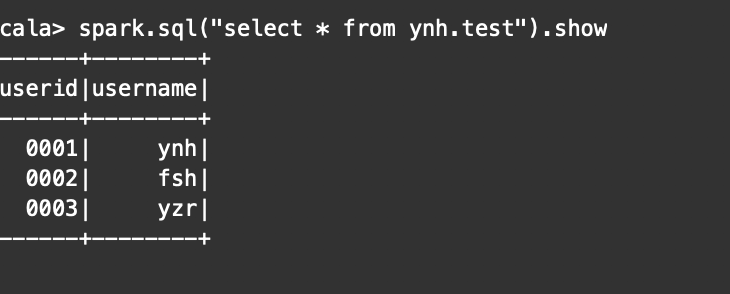
1.创建hive中ynh库下的表
CREATE TABLE IF NOT EXISTS test(
2.启动metastore服务:
bin/hive --service metastore
3.打开bin/spark-shell
备注:
此处beeline是基于thrift server服务进行操作的。通过jdbc对hive进行操作。
thriftserver和spark-shell/spark sql的区别:
每次启动一个spark-shell/spark sql它都是一个spark application,每次都要重新启动申请资源。
用thriftserver,无论启动多少个客户端(beeline),只要是连在一个thriftserver上,它都是一个spark application,后面不用在重新申请资源。能数据共享(上一个beeline做了缓存,下一个beeline能用)
用thriftserver,在UI中能直接看到sql的执行计划,方便优化。
步骤 :(spark安装路径下)
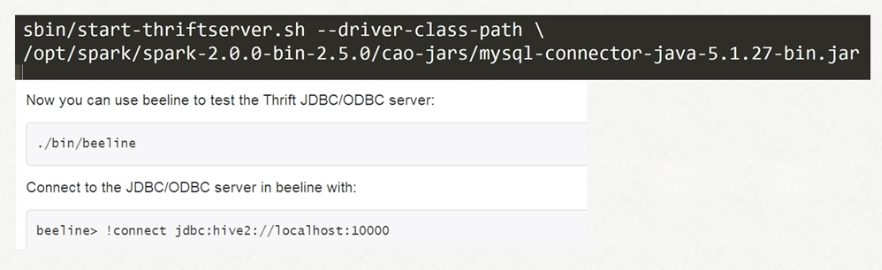
1.启动thriftserver (启动完成后是一个SparkSubmit进程)
sbin/start-thriftserver.sh
2.启动beeline
bin/beeline
3.通过thriftserver连接hive表,可以对hive表进行操作
!connect jdbc:hive2://bigdata-pro03.ynh.com:10000 (此url是thrift server的地址)
背景:过去传统企业没有引入hadoop时,多使用类似oracle、mysql这样的数据库存储数据,但是她们的可扩展性和可用性很差。如果要导入hadoop的话,还需要硬编码和程序去写,需要较大的工作量。
这种关系型数据库适合于实时交易的数据量不大的情况。因为它的事务做的还不错。
hadoop适合于数据量大的。多query、insert的操作。
spark能快速无缝衔接多种数据源:hdfs、hadoop数据仓库、hbase、关系型数据库……
步骤:
spark sql与hbase的集成,其核心就是spark sql通过Hive外部表来获取Hbase的表数据 步骤:
上文的异常解决(数据量大):
在集群模式下跑:standalone或者yarn
standalone模式:
sbin/start-all.sh //启动master和worker
bin/spark-shell spark://bigdata-pro03.ynh.com:7077
法1――使用rpm安装:
sudo rpm -ivh nc-XXX.rpm
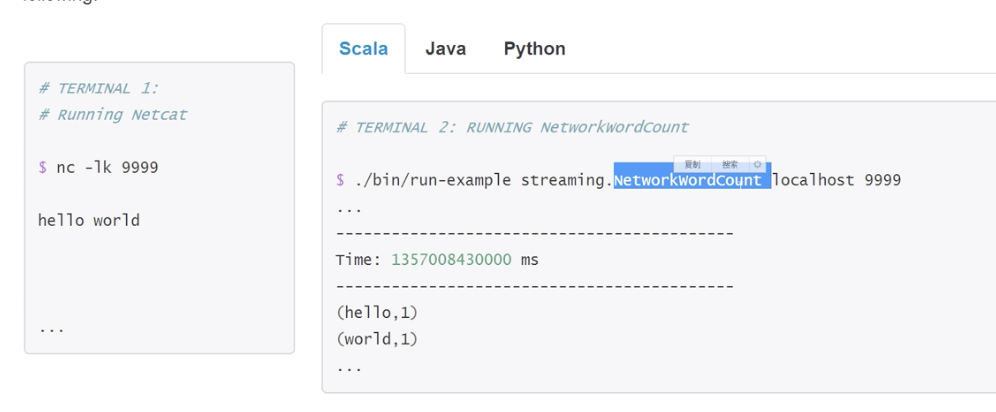
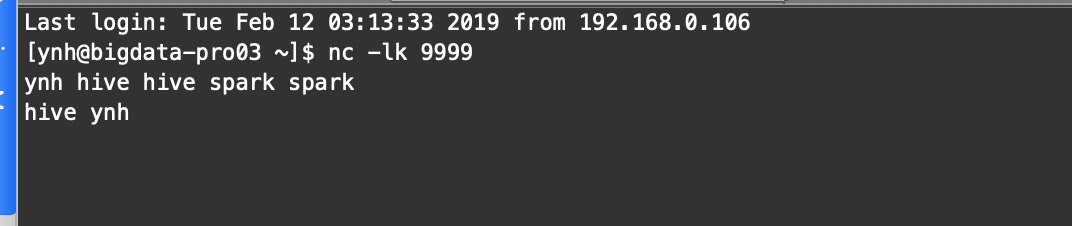
3.打开nc输入流: nc -lk 端口号
nc -lk 9999
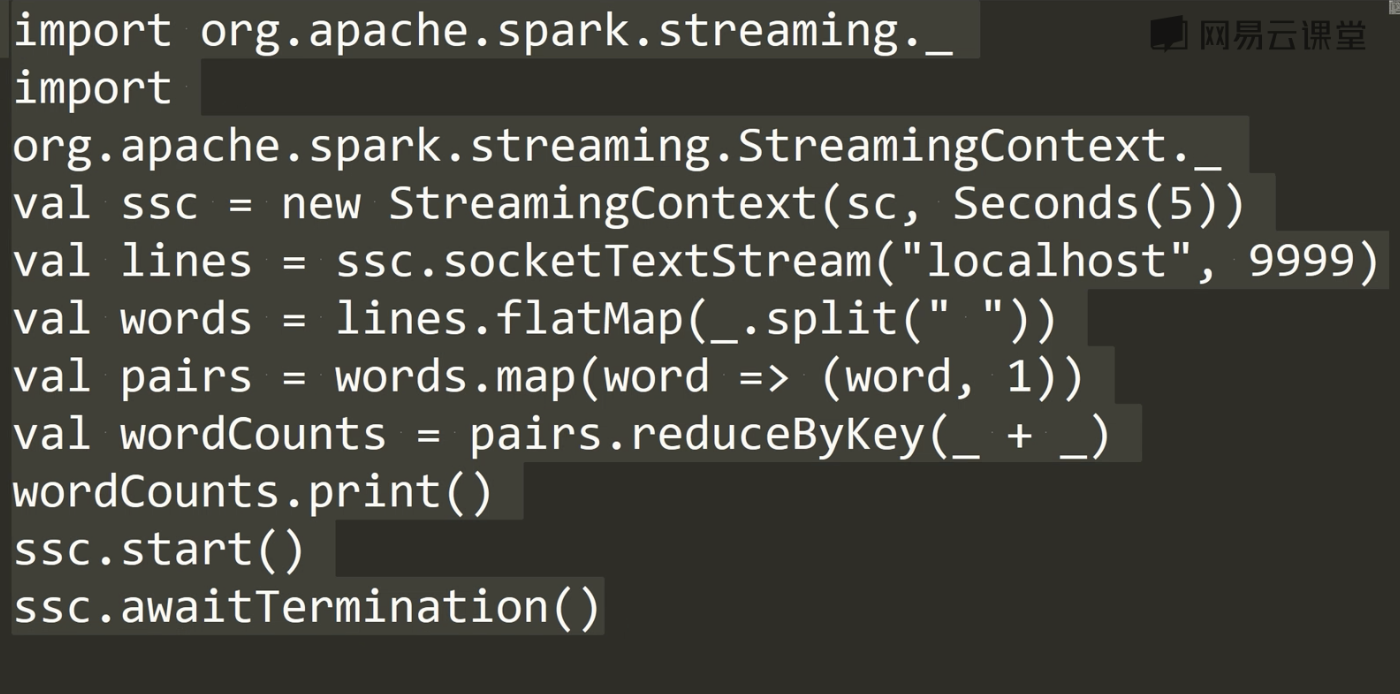
4.测试wordcount示例程序
bin/run-example --master local[2] streaming.NetworkWordCount localhost 9999
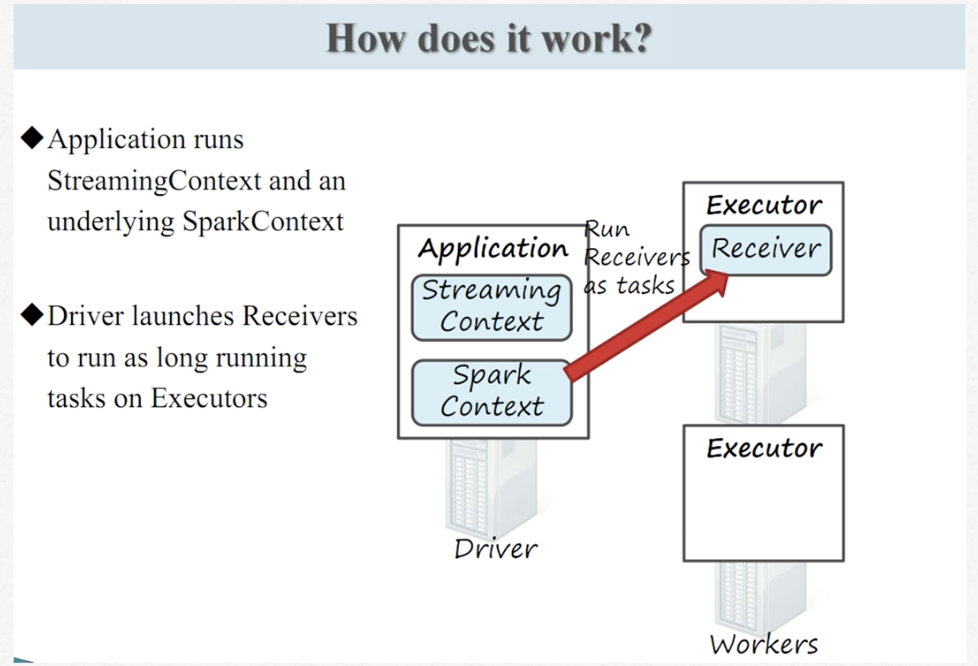
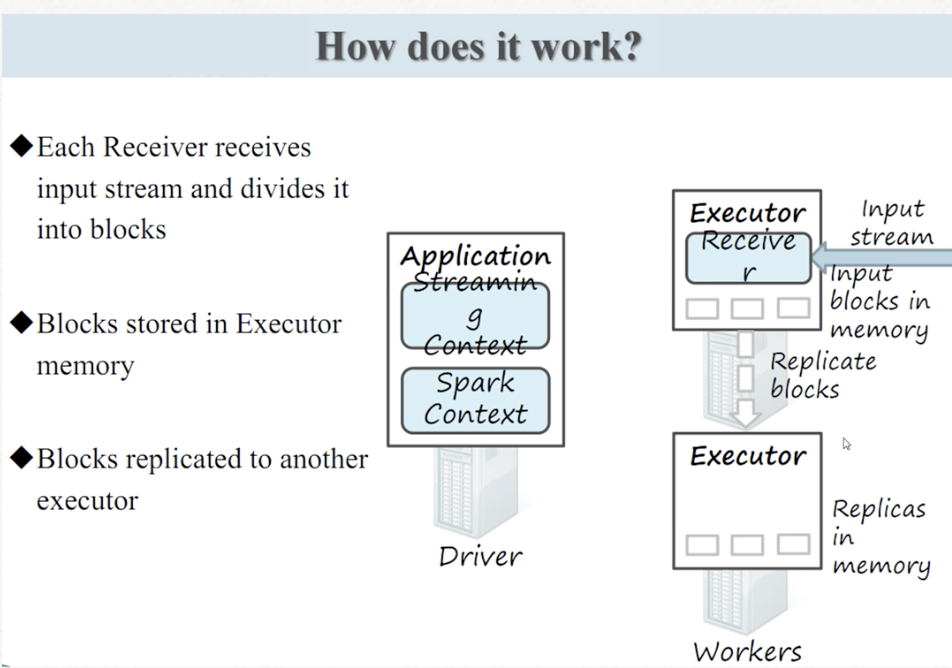
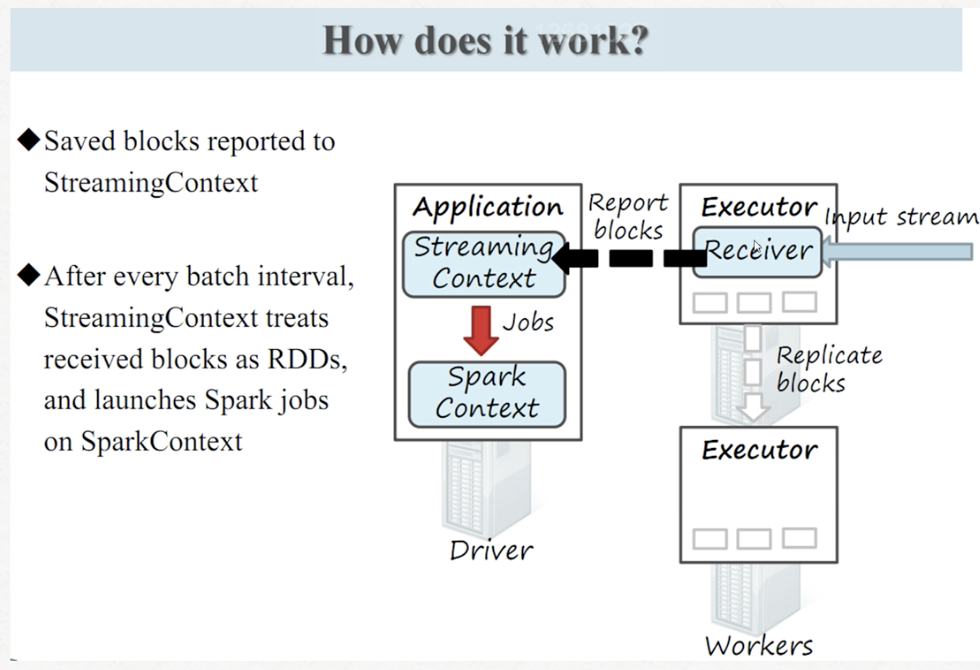
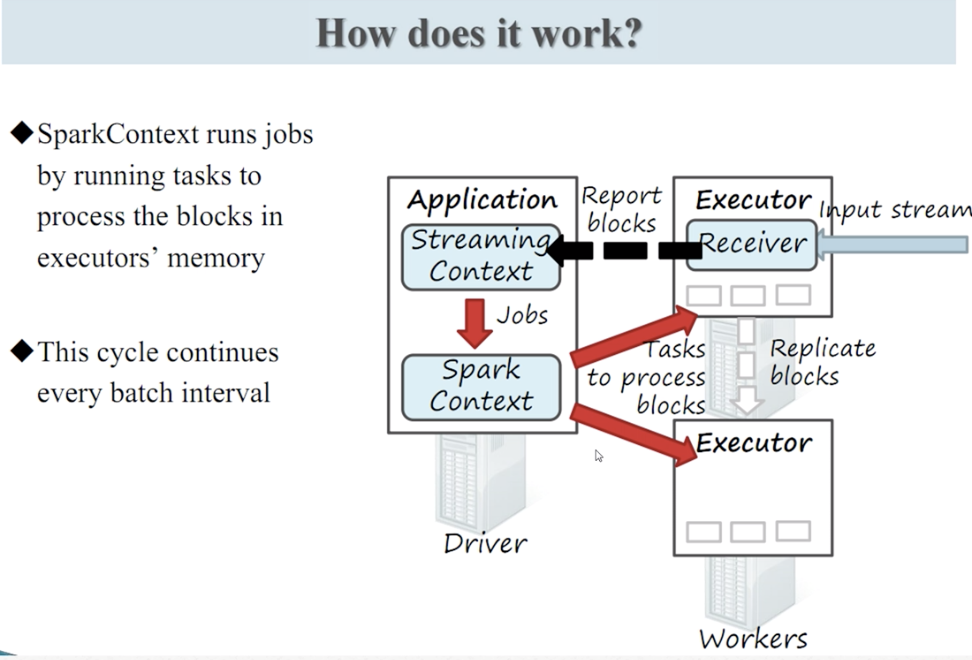
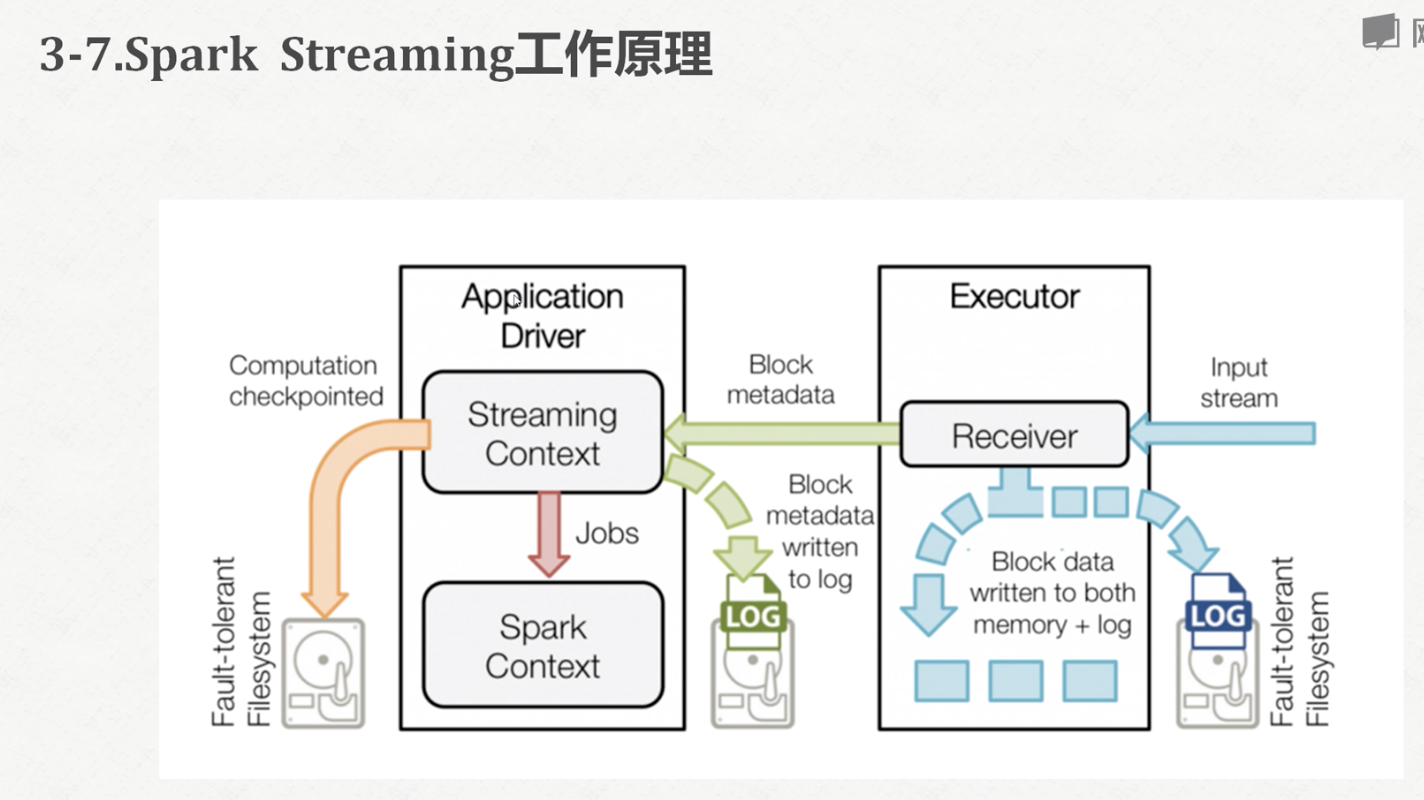
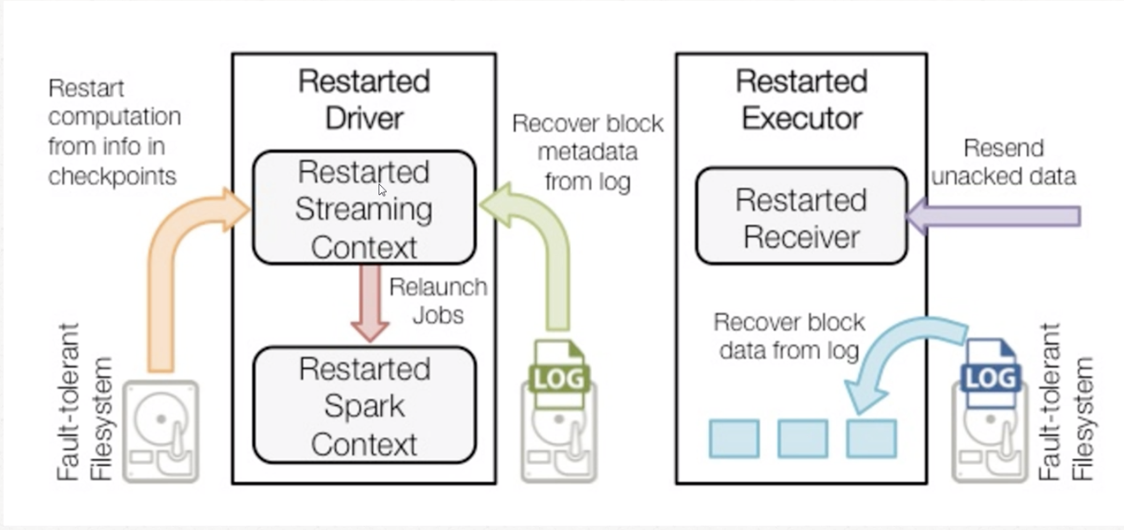
过程:receiver线程-备份-离散化分批-spark处理-result
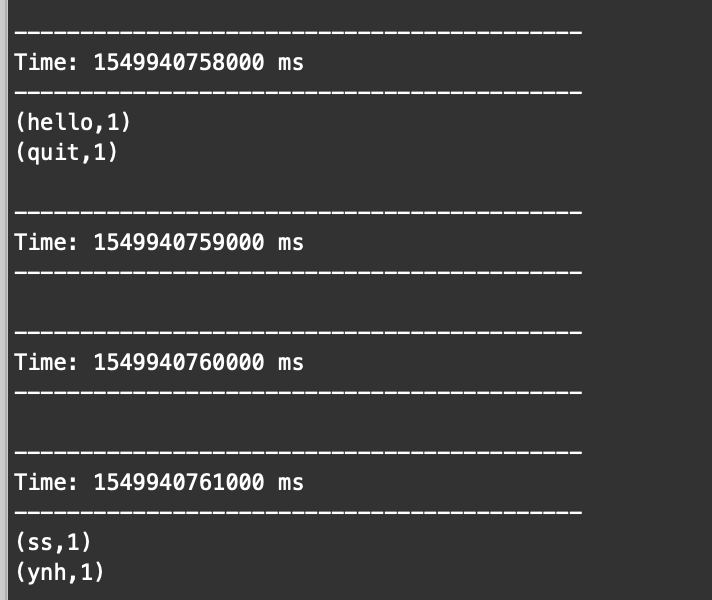
结果展示:
详情请参考spark官网
过程 :receiver线程-备份-离散化分批-spark处理-result
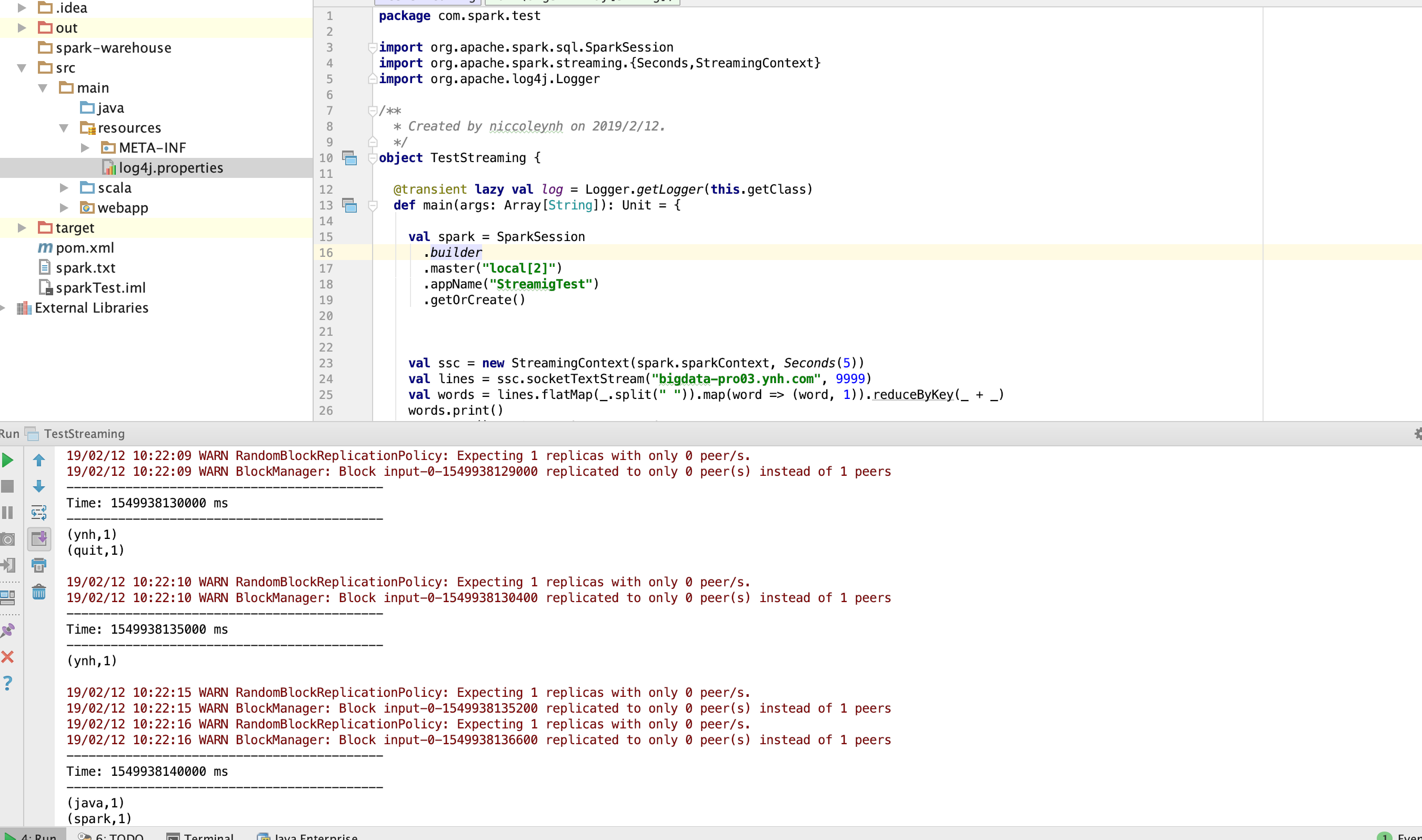
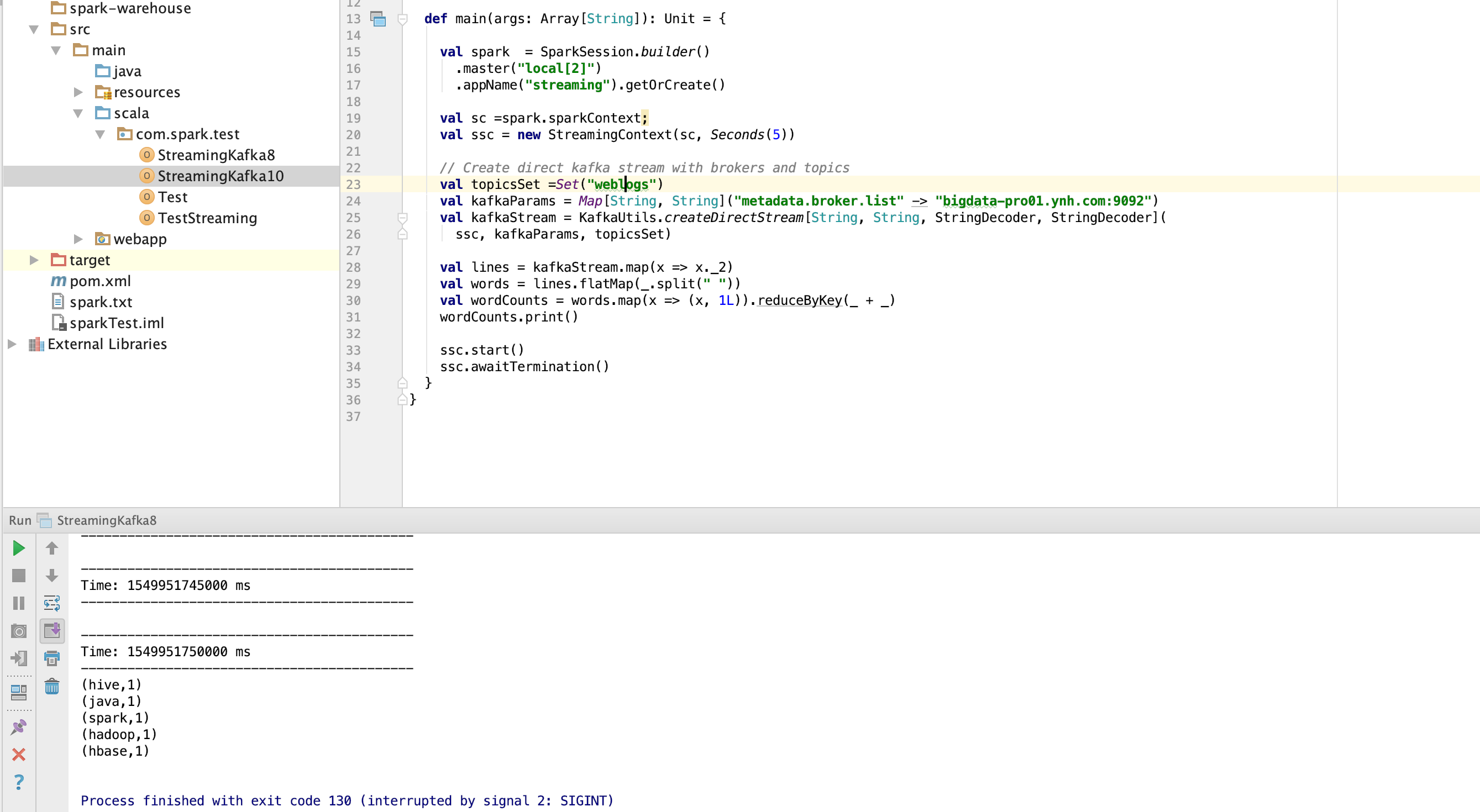
1.启动spark-shell(本地至少两个线程:因为至少要保证一个线程用于执行receiver)
bin/spark-shell --master local[2]
备注:
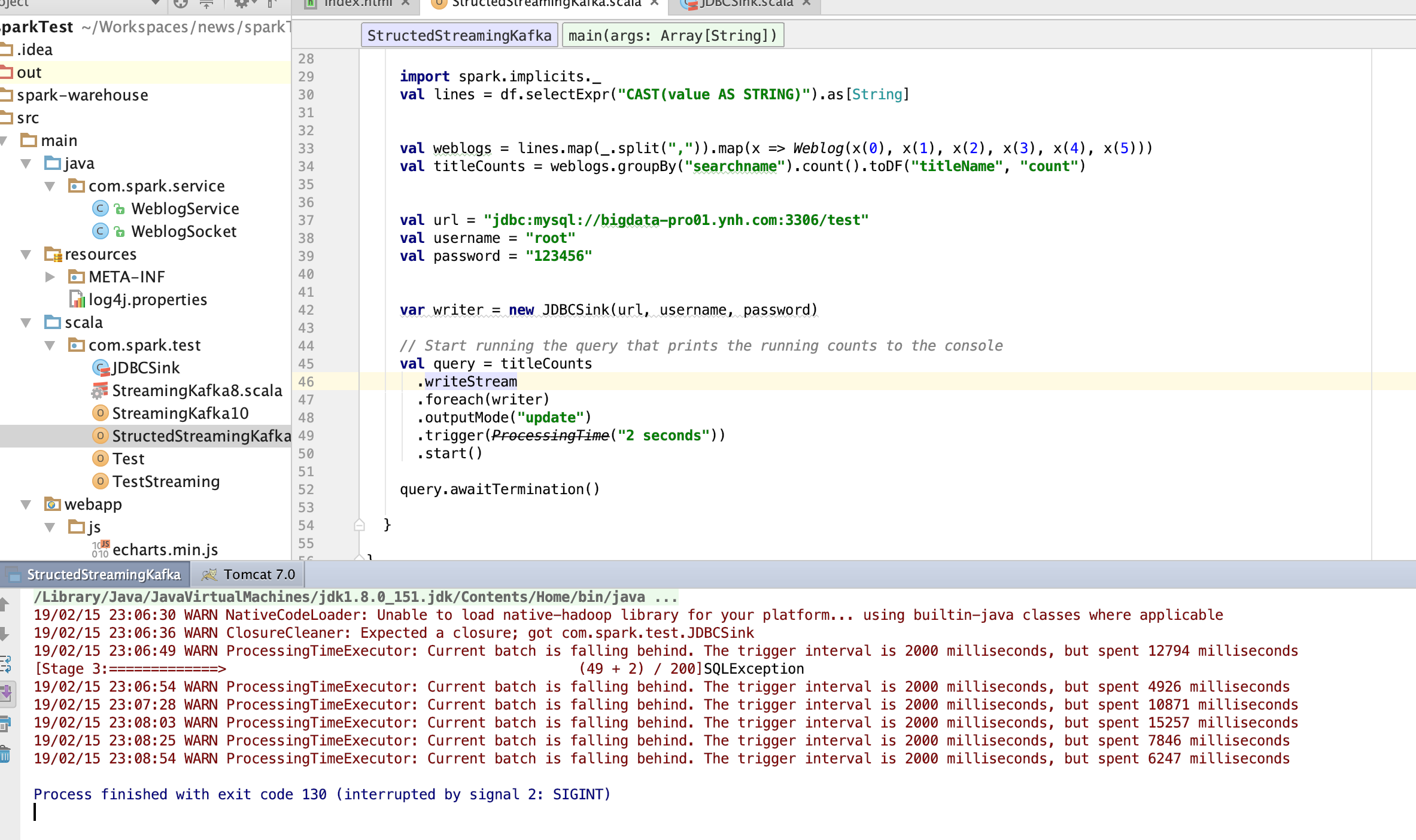
IDEA测试结果:
到关系数据库:
说明:
集成方法一 :Receiver-based Approach。但是receiver自身不会分partition读取,而是合并在一起读取。效率就会低下一点。集成方法二 :Direct Approach(No Receivers)结果:
总结:stream流当中kafka和socket比较常用
streaming集成kafka10
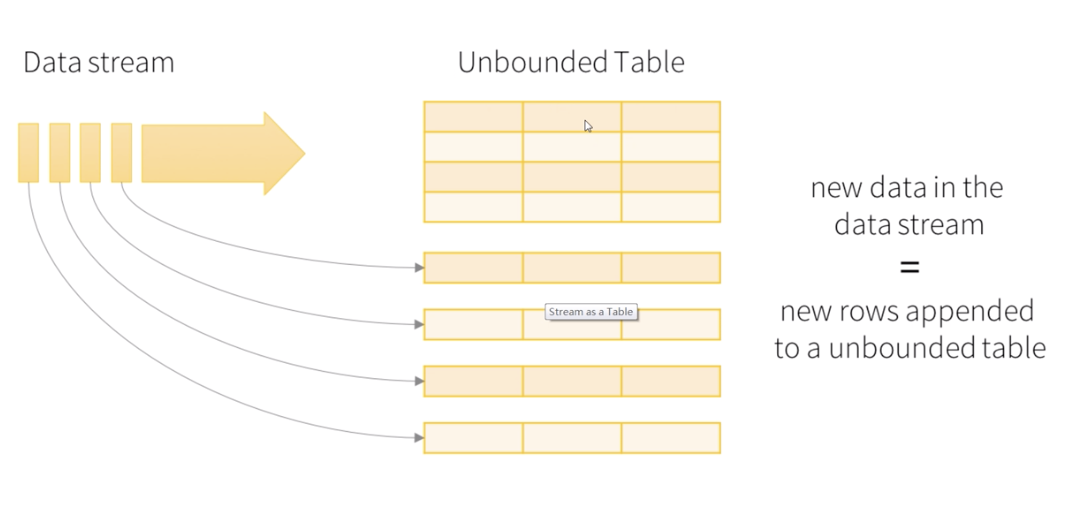
核心思想:将实时的数据流看成不断累加的无边界的table
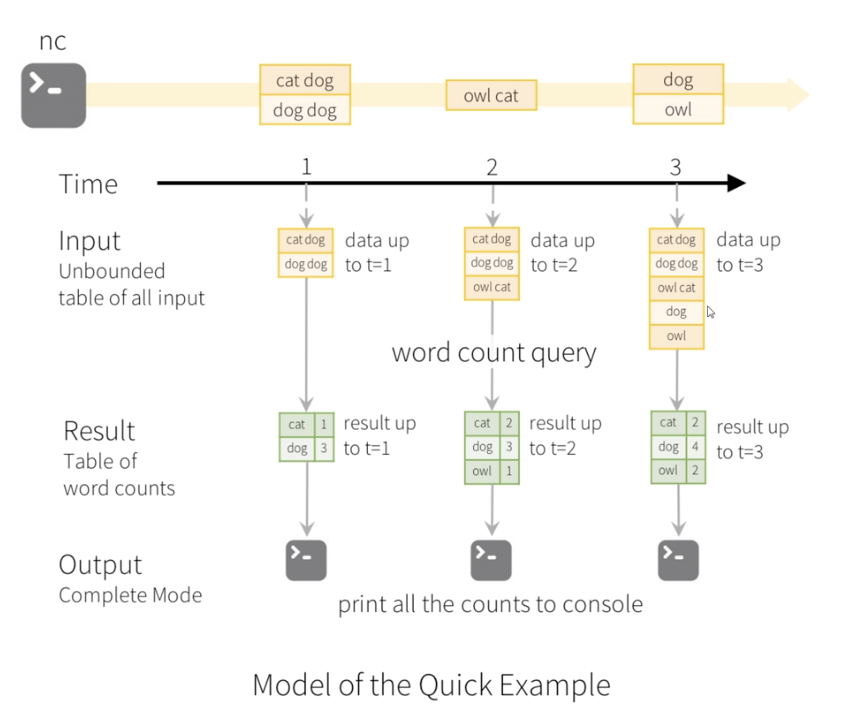
编程模型
结构化流输出模式:Complete Mode、Append Mode、Update Mode
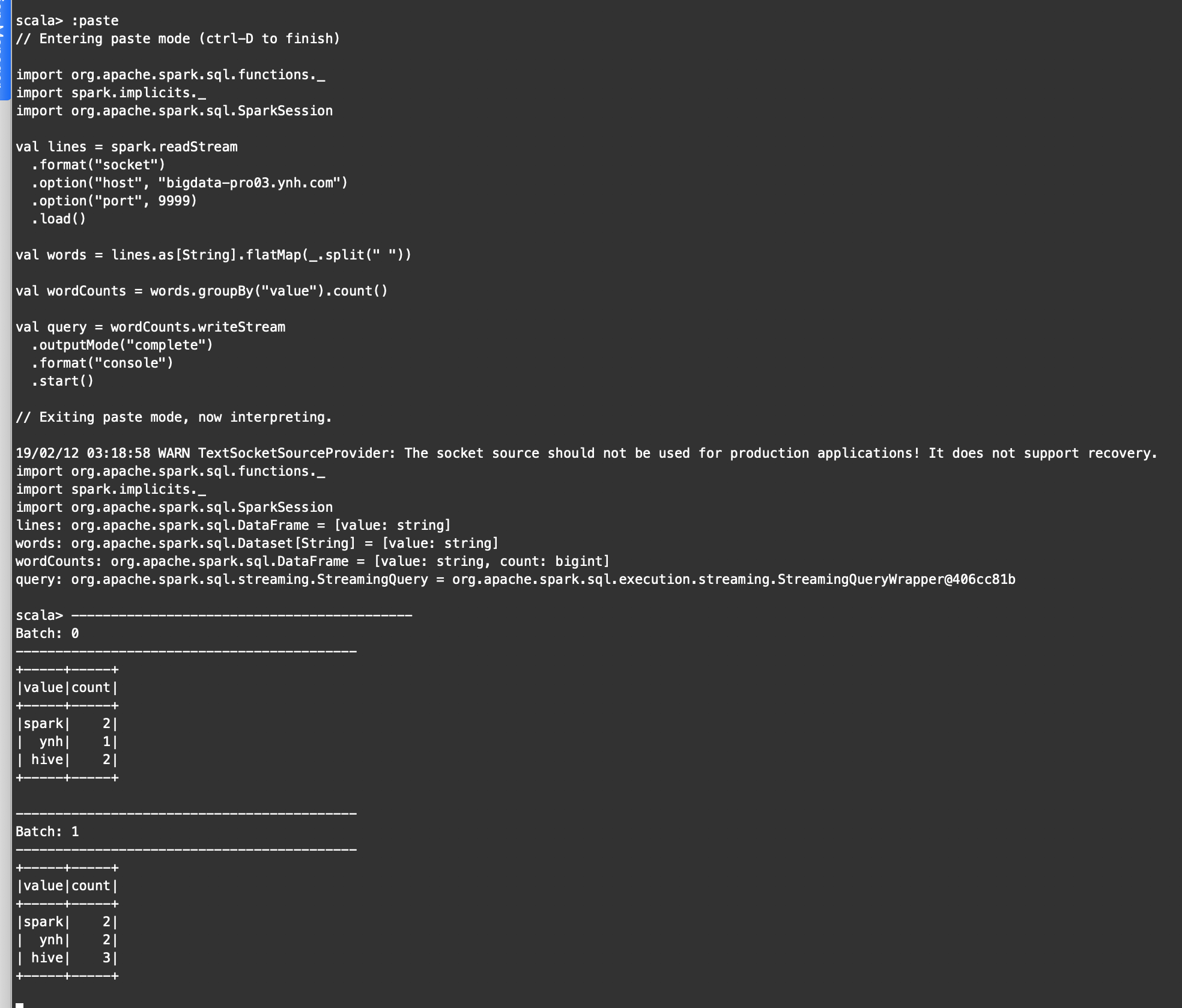
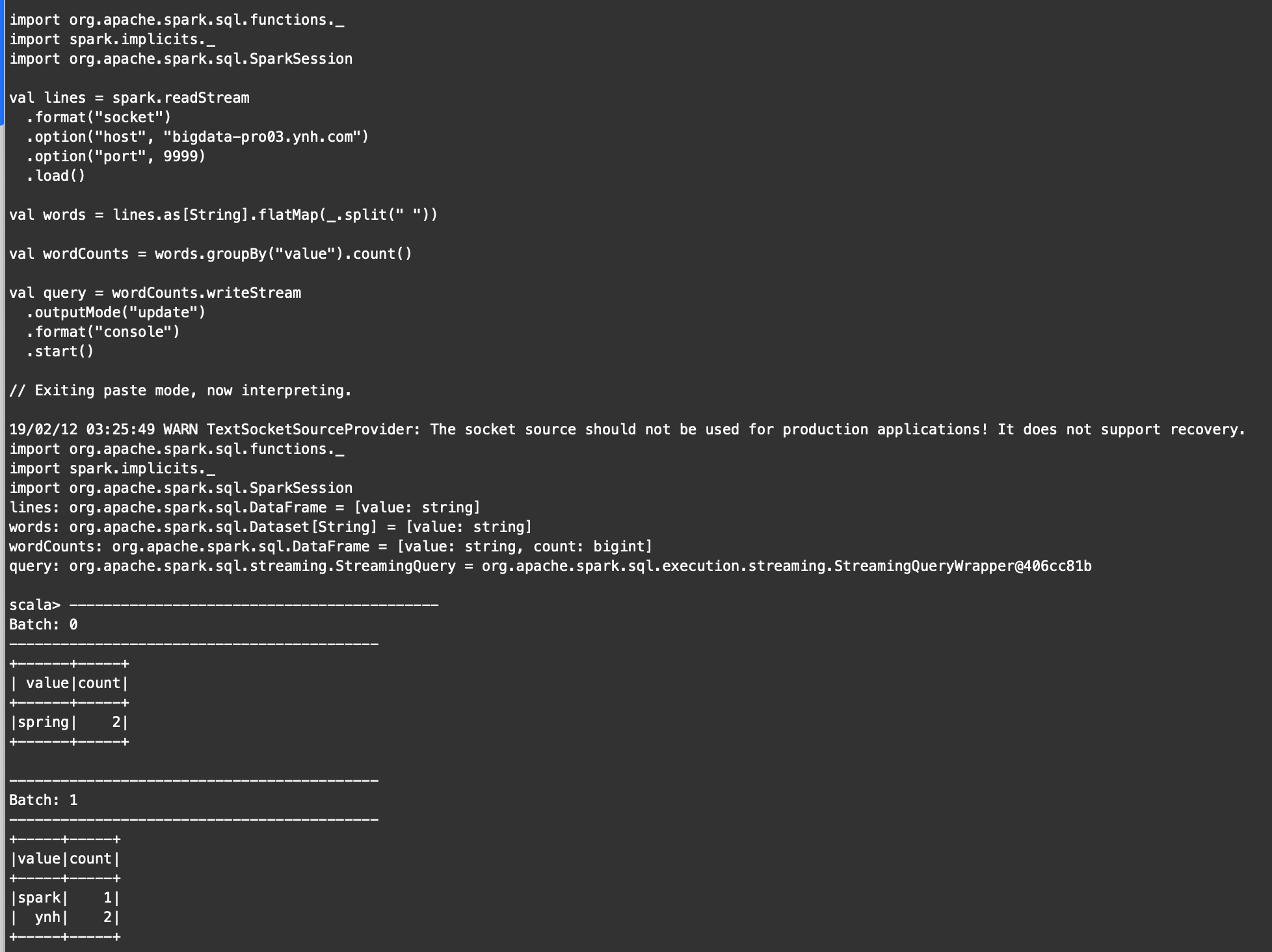
代码:
import org. apache. spark. sql. functions. _
import spark. implicits. _
import org. apache. spark. sql. SparkSession
val lines = spark. readStream
. format ( "socket" )
. option ( "host" , "bigdata-pro03.ynh.com" )
. option ( "port" , 9999 )
. load ( )
val words = lines. as[ String] . flatMap ( _. split ( " " ) )
val wordCounts = words. groupBy ( "value" ) . count ( )
val query = wordCounts. writeStream
. outputMode ( "update" )
. format ( "console" )
. start ( )
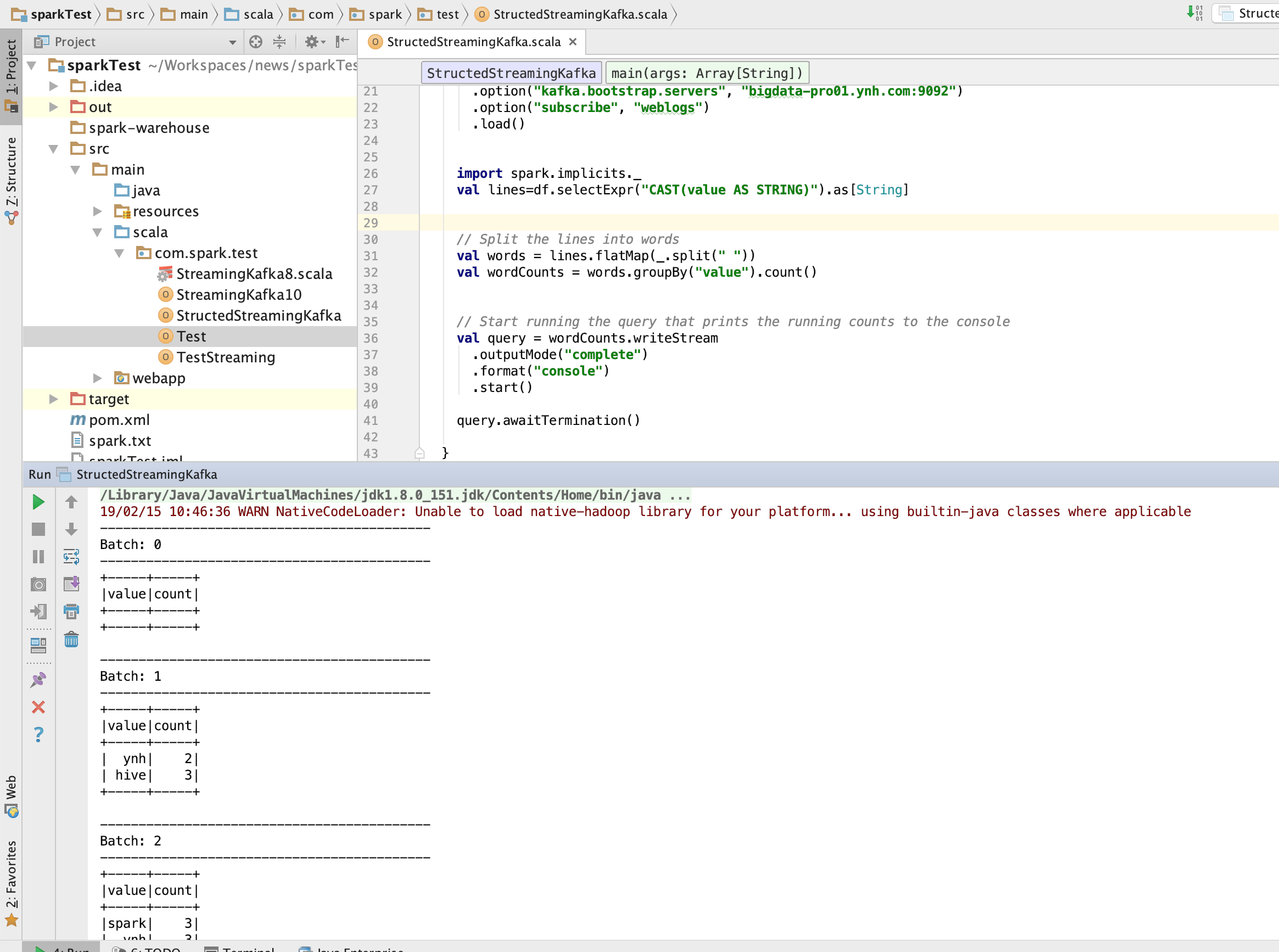
结果:
Structed Streaming要求kafka0.10以上
上面测试移动到spark-shell上测试,需要导入相关kafka的jar包
参考博客:https://databricks.com/blog/2017/04/04/real-time-end-to-end-integration-with-apache-kafka-in-apache-sparks-structured-streaming.html
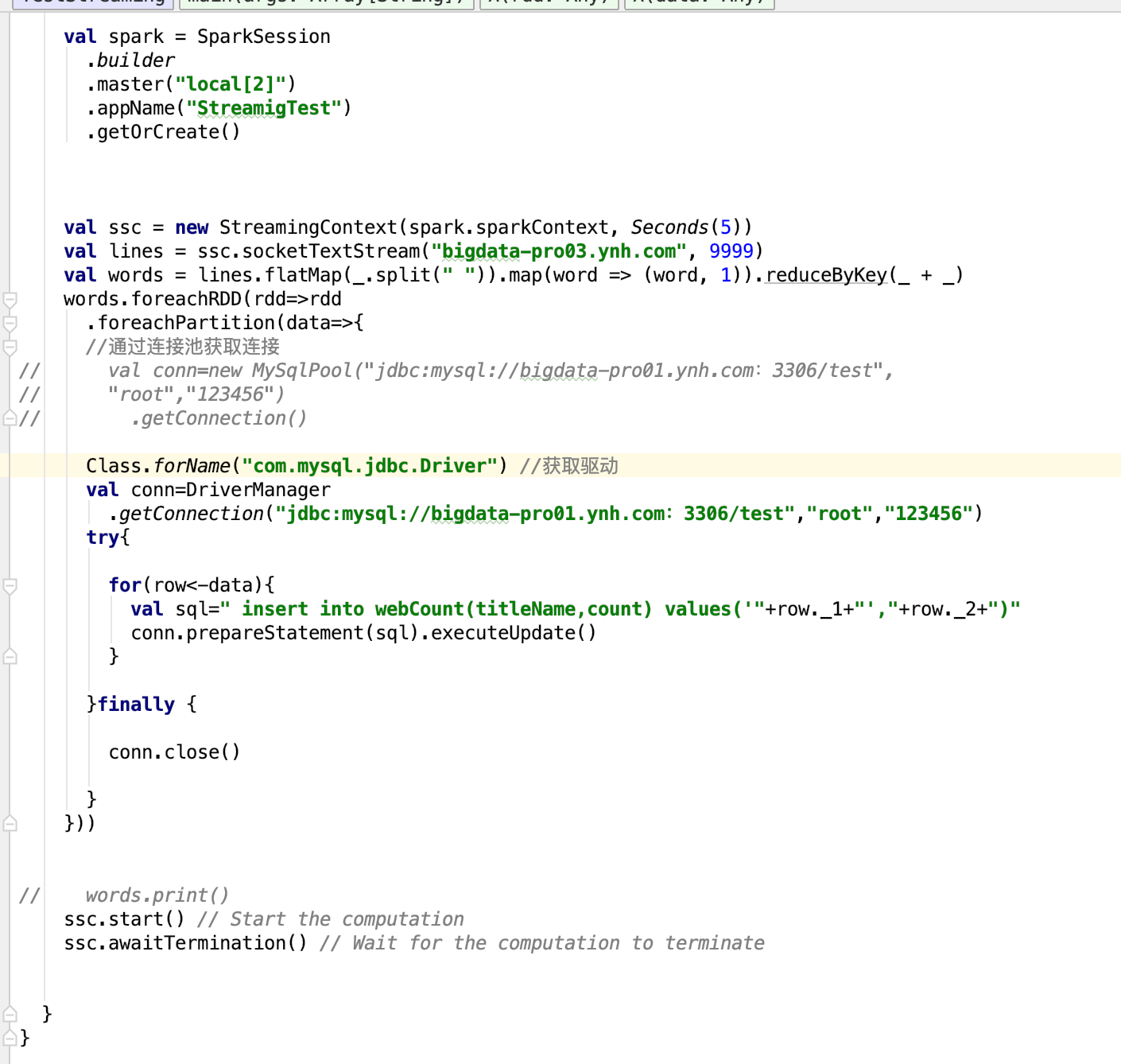
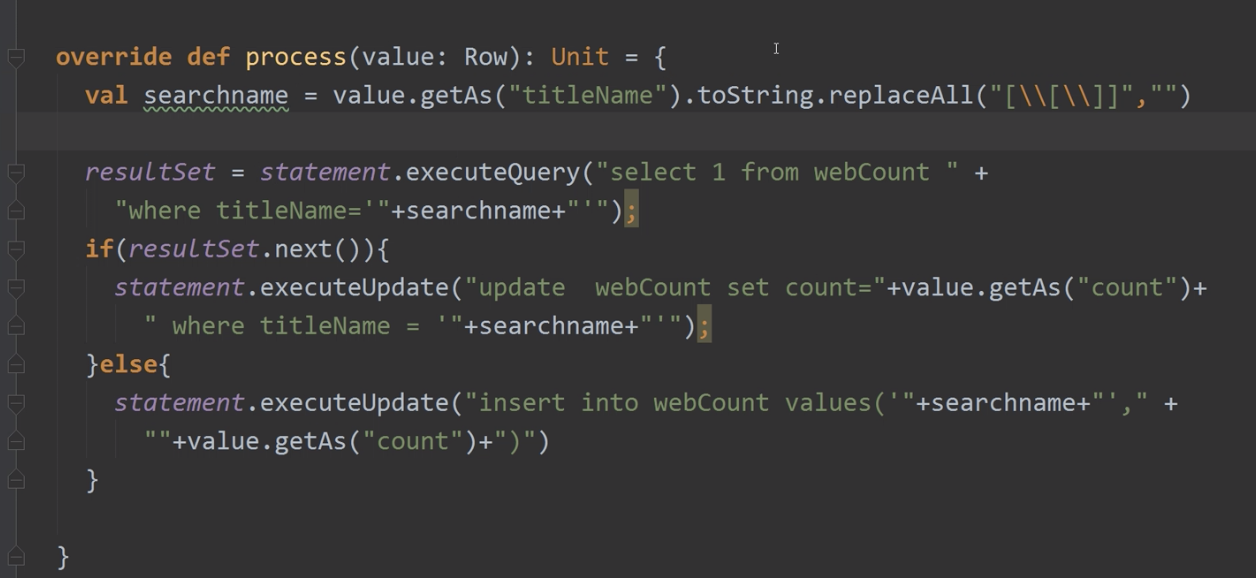
新建JDBCSink
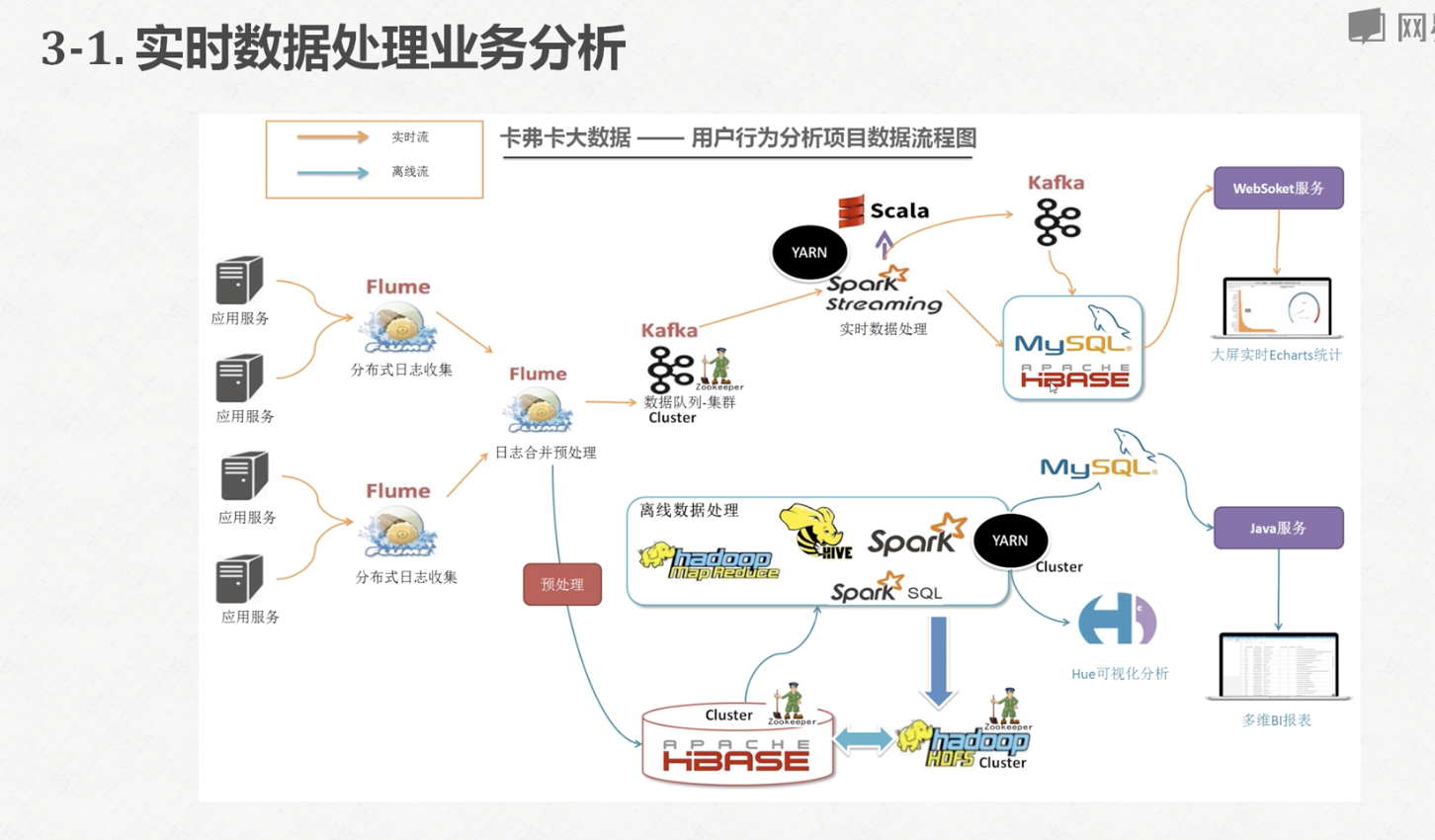
捋一下项目需求:
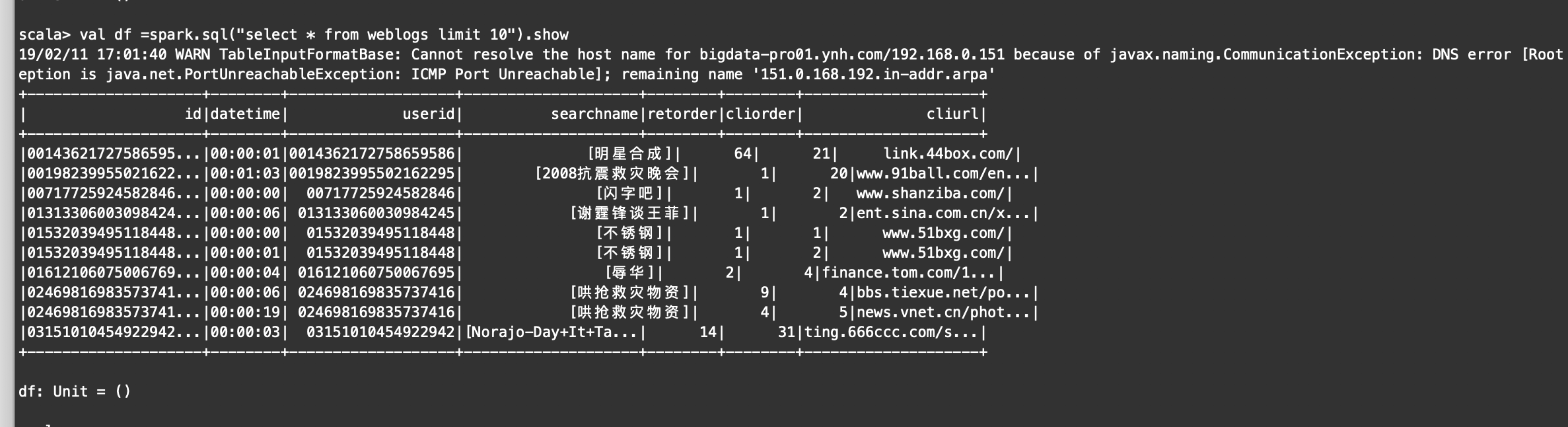
数据源:kafka->业务流数据 [weblogs]
结构化流处理kafka的数据
处理结果写入MySql数据库[test.webCount]
CREATE TABLE `webCount`(
输出:titleName,count
过滤:desc count limit 20
web系统
关于Structed Streaming中文乱码解决方案:
梳理:
数据库->JAVA数据服务层->webSocket服务层->前端页面 (说明,此处是为了简单快速展示数据,如果涉及到一个完整的企业级应用什么的,可能才采用像spring这样的框架)。此案例是数据源很大,但是数据结果并不大。所以现实当中应该尽可能考虑技术、公司规模、迭代周期等因素,合理地选用技术框架。
此案例下载的是tomcat 7.07.92
package com. spark. service;
import org. apache. commons. collections. iterators. ObjectArrayIterator;
import org. apache. commons. collections. map. HashedMap;
import java . sql. Connection;
import java. sql. DriverManager;
import java. sql. PreparedStatement;
import java. sql. ResultSet;
import java. util. HashMap;
import java. util. Map;
public class WeblogService {
static String url = "jdbc:mysql://bigdata-pro01.ynh.com:3306/test" ;
static String username= "root" ;
static String password= "123456" ;
public Map< String, Object> queryWeblogs ( ) {
Connection conn = null;
PreparedStatement pst = null;
String[ ] titleNames = new String [ 20 ] ;
String[ ] titleCounts = new String [ 20 ] ;
Map< String, Object> = new HashMap < String, Object> ( ) ;
try {
Class. forName ( "com.mysql.jdbc.Driver" ) ;
conn = DriverManager. getConnection ( url, username, password) ;
String query_sql = "select titleName,count from webCount where 1=1 order by count desc limit 20" ;
pst = conn. prepareStatement ( query_sql) ;
ResultSet rs = pst. executeQuery ( ) ;
int i = 0 ;
while ( rs. next ( ) ) {
String titleName = rs. getString ( "titleName" ) ;
String titleCount = rs. getString ( "count" ) ;
titleNames[ i] = titleName;
titleCounts[ i] = titleCount;
++ i;
}
retMap. put ( "titleName" , titleNames) ;
retMap. put ( "titleCount" , titleCounts) ;
} catch ( Exception e) {
e. printStackTrace ( ) ;
} finally {
try {
if ( pst != null) {
pst. close ( ) ;
}
if ( conn != null) {
conn. close ( ) ;
}
} catch ( Exception e) {
e. printStackTrace ( ) ;
}
}
return retMap;
}
public String[ ] titleCount ( ) {
Connection conn = null;
PreparedStatement pst = null;
String[ ] titleSums = new String [ 1 ] ;
try {
Class. forName ( "com.mysql.jdbc.Driver" ) ;
conn = DriverManager. getConnection ( url, username, password) ;
String query_sql = "select count(1) titleSum from webCount" ;
pst = conn. prepareStatement ( query_sql) ;
ResultSet rs = pst. executeQuery ( ) ;
if ( rs. next ( ) ) {
String titleSum = rs. getString ( "titleSum" ) ;
titleSums[ 0 ] = titleSum;
}
} catch ( Exception e) {
e. printStackTrace ( ) ;
} finally {
try {
if ( pst != null) {
pst. close ( ) ;
}
if ( conn != null) {
conn. close ( ) ;
}
} catch ( Exception e) {
e. printStackTrace ( ) ;
}
}
return titleSums;
}
}
package com. spark. service;
import com. alibaba. fastjson. JSON;
import javax. websocket. OnClose;
import javax. websocket. OnMessage;
import javax. websocket. OnOpen;
import javax. websocket. Session;
import javax. websocket. server. ServerEndpoint;
import java. io. IOException;
import java. util. HashMap;
import java. util. Map;
@ServerEndpoint ( "/websocket" )
public class WeblogSocket {
WeblogService weblogService = new WeblogService ( ) ;
@OnMessage
public void onMessage ( String message, Session session)
throws IOException, InterruptedException {
while ( true ) {
Map< String, Object> = new HashMap < String, Object> ( ) ;
map. put ( "titleName" , weblogService. queryWeblogs ( ) . get ( "titleName" ) ) ;
map. put ( "titleCount" , weblogService. queryWeblogs ( ) . get ( "titleCount" ) ) ;
map. put ( "titleSum" , weblogService. titleCount ( ) ) ;
session. getBasicRemote ( ) .
sendText ( JSON. toJSONString ( map) ) ;
Thread. sleep ( 2000 ) ;
map. clear ( ) ;
}
}
@OnOpen
public void onOpen ( ) {
System. out. println ( "Client connected" ) ;
}
@OnClose
public void onClose ( ) {
System. out. println ( "Connection closed" ) ;
}
}
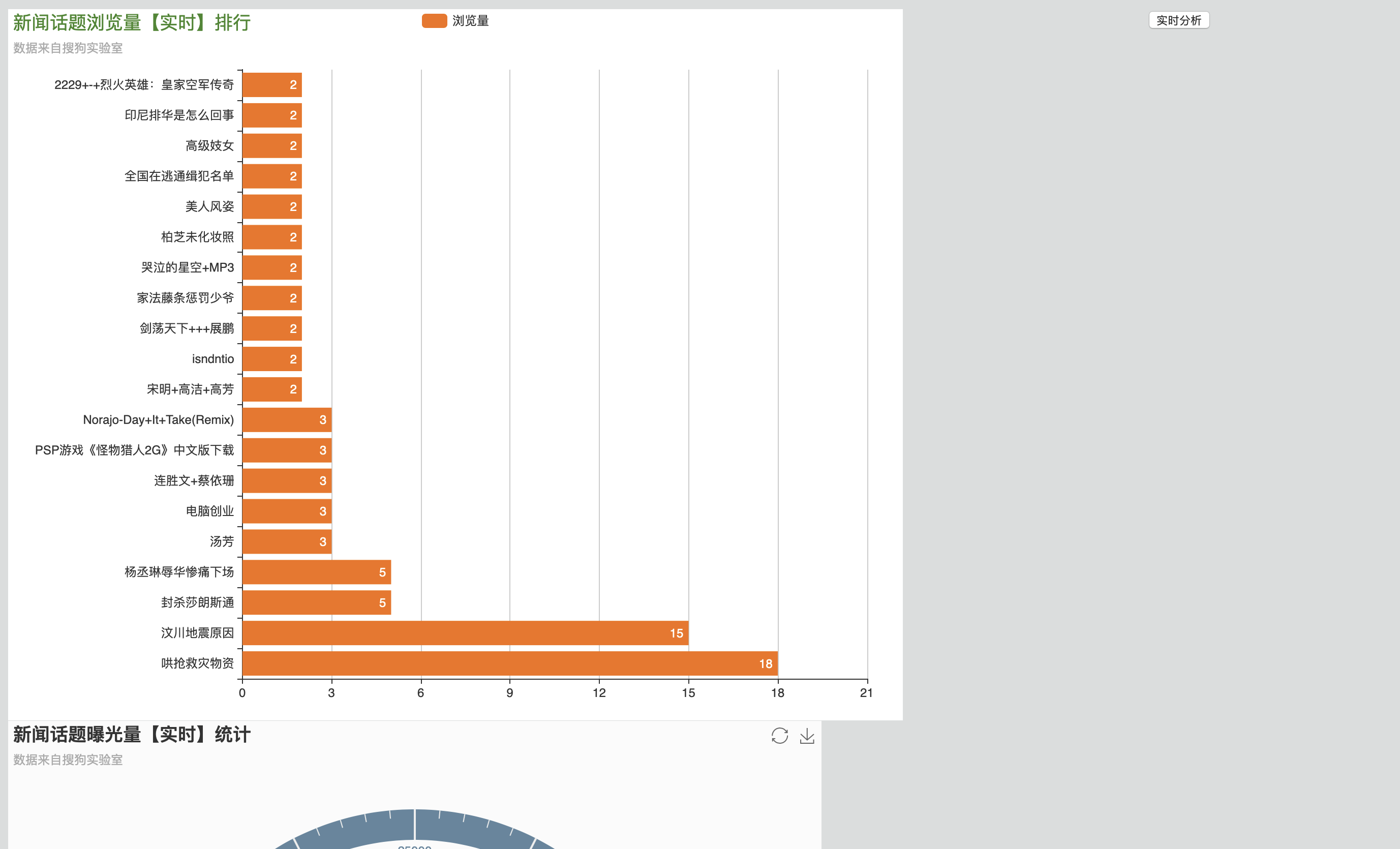
使用框架:Echarts(页面渲染)+JQuery(通信)
1.导入相关js包
2.html页面
< ! DOCTYPE html>
< html lang= "en" >
< head> < meta charset= "UTF-8" >
< title> < / title>
< script src= "js/echarts.min.js" > < / script>
< script src= "js/jquery-3.2.1.js" > < / script>
< style> {
text- align: center;
background- color: #dbdddd;
}
. div{ margin: 0 auto; width: 1000 px; height: 800 px; border: 1 px solid #F00}
< / style>
< / head>
< body> < h1> < / h1>
< div> < div id= "main" style= "width:880px;height: 700px;float:left;" > 第一个< / div>
< div id= "sum" style= "width:800px;height: 700px;float:left;" > 第二个< / div>
< / div>
< div> < input type= "submit" value= "实时分析" onclick= "start()" / >
< / div>
< div id= "messages" > < / div>
< script type= "text/java script" >
var webSocket = new WebSocket ( 'ws://localhost:8080/websocket' ) ;
var myChart = echarts. init ( document. getElementById ( 'main' ) ) ;
var myChart_sum = echarts. init ( document. getElementById ( 'sum' ) ) ;
webSocket. onerror = function ( event) {
onError ( event)
} ;
webSocket. onopen = function ( event) {
onOpen ( event)
} ;
webSocket. onmessage = function ( event) {
onMessage ( event)
} ;
function onMessage ( event) {
var sd = JSON. parse ( event. data) ;
processingData ( sd) ;
titleSum ( sd. titleSum) ;
}
function onOpen ( event) {
}
function onError ( event) {
alert ( event. data) ;
}
function start ( ) {
webSocket. send ( 'hello' ) ;
return false ;
}
function processingData ( json) {
var option = {
backgroundColor: '#ffffff' ,
title: {
text: '新闻话题浏览量【实时】排行' ,
subtext: '数据来自搜狗实验室' ,
textStyle: {
fontWeight: 'normal' ,
color: '#408829'
} ,
} ,
tooltip: {
trigger: 'axis' ,
axisPointer: {
type: 'shadow'
}
} ,
legend: {
data: [ '浏览量' ]
} ,
grid: {
left: '3%' ,
right: '4%' ,
bottom: '3%' ,
containLabel: true
} ,
xAxis: {
type: 'value' ,
boundaryGap: [ 0 , 0.01 ]
} ,
yAxis: {
type: 'category' ,
data: json. titleName
} ,
series: [
{
name: '浏览量' ,
type: 'bar' ,
label: {
normal: {
show: true ,
position: 'insideRight'
}
} ,
itemStyle: { normal: { color: '#f47209' } } ,
data: json. titleCount
}
]
} ;
myChart. setOption ( option) ;
}
function titleSum ( data) {
var option = {
backgroundColor: '#fbfbfb' ,
title: {
text: '新闻话题曝光量【实时】统计' ,
subtext: '数据来自搜狗实验室'
} ,
tooltip : {
formatter: "{a} <br/>{b} : {c}%"
} ,
toolbox: {
feature: {
restore: { } ,
saveAsImage: { }
}
} ,
series: [
{
name: '业务指标' ,
type: 'gauge' ,
max: 50000 ,
detail: { formatter: '{value}个话题' } ,
data: [ { value: 50 , name: '话题曝光量' } ]
}
]
} ;
option. series[ 0 ] . data[ 0 ] . value = data;
myChart_sum. setOption ( option, true ) ;
}
< / script>
< / body>
< / html>
1.多读官方文档
说明:

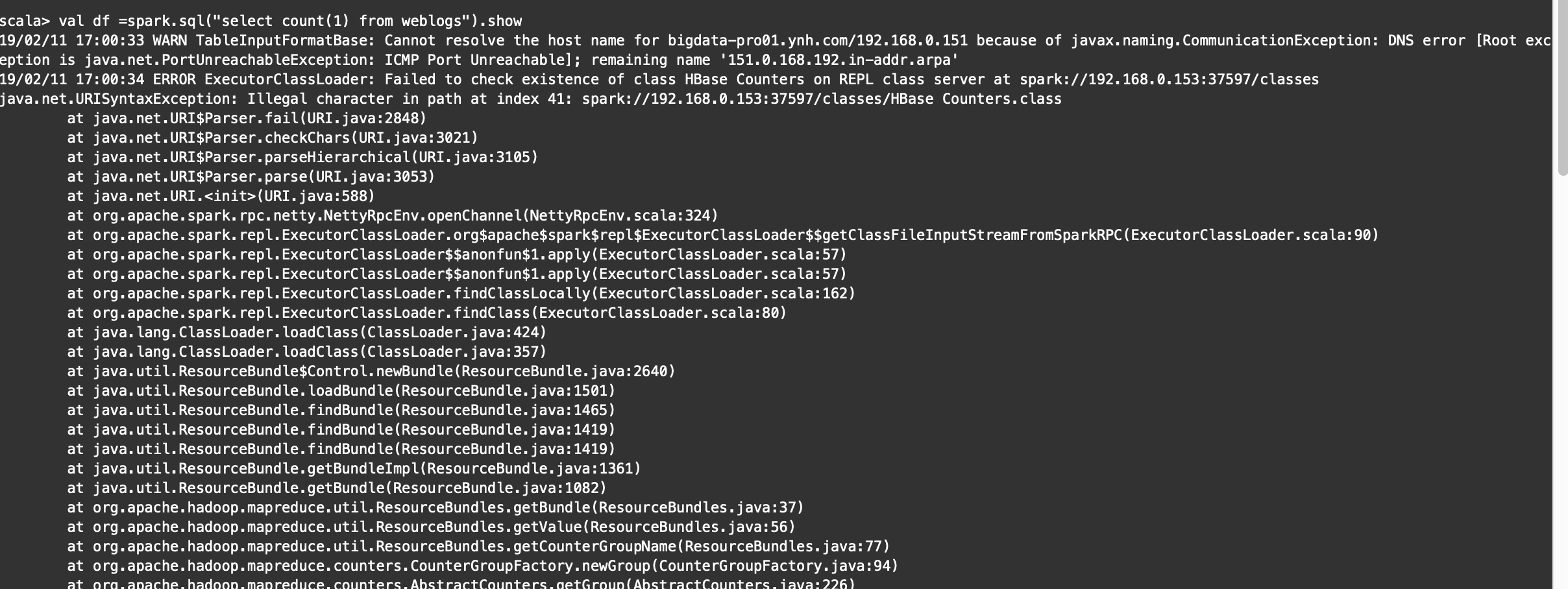
 没有这个错误了
没有这个错误了