��Ȩ����������Ϊ����ԭ�����£�δ��������������ת�ء� https://blog.csdn.net/bingdianone/article/details/84105561
Apache Spark��һ��ͳһ�ķ���������д��ģ���ݴ���
����
����
ͨ��
��������
MapReduce�ľ����ԣ�
���뷱����
ֻ�ܹ�֧��map��reduce������
ִ��Ч�ʵ��£�
���ʺϵ�����Ρ�����ʽ����ʽ�Ĵ�����
��ܶ�������
�����������ߣ���MapReduce��Hive��Pig
��ʽ������ʵʱ���� Storm��JStorm
����ʽ���㣺Impala
http://spark.apache.org/news/index.html
����
����
Spark��̬Ȧ
������
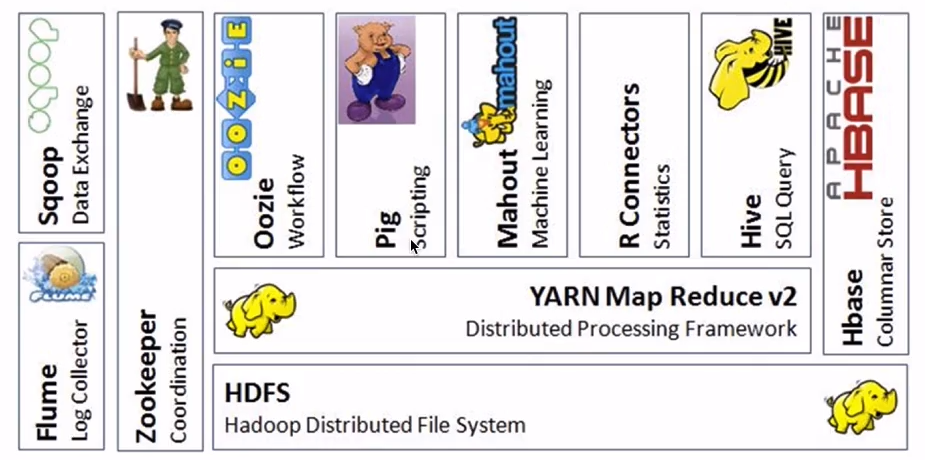
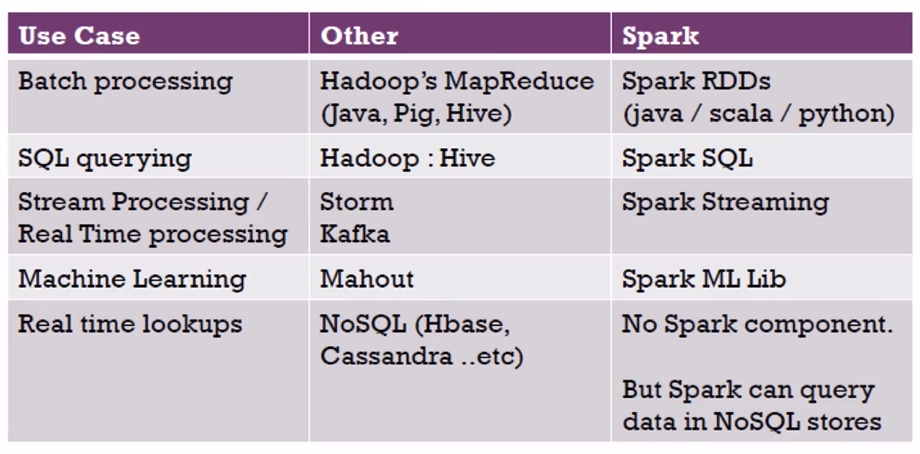
Hadoop�е�MapRdeuce��Java����MR,Pig,Hive��
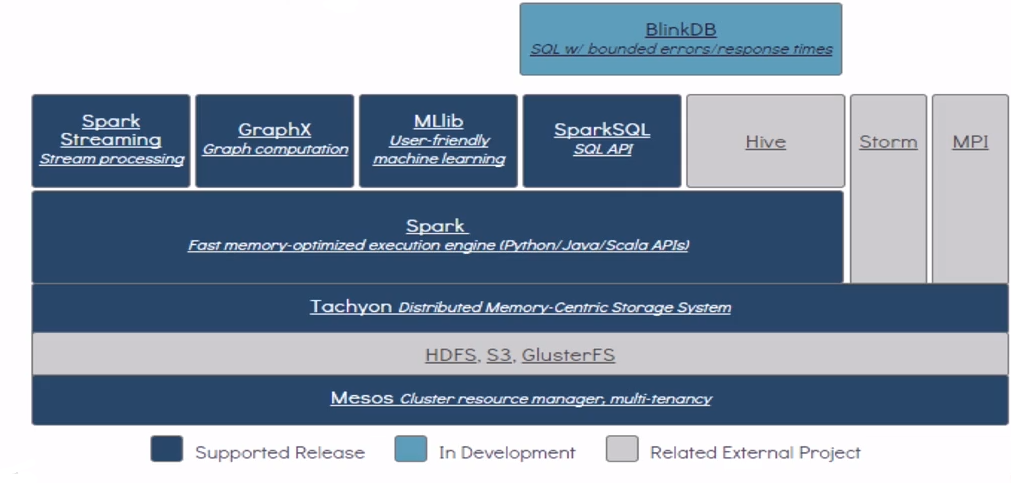
Spark RDDs��java /scala/python �������api���ɣ�
SQL��ѯ
Hadoop�е�Hive
Spark SQL
������/ʵʱ����
Storm��Kafka
Spark Streaming
����ѧϰ
Mahout����ֹͣ���£�
Spark ML Lib
ʵʱ��ѯ
NoSQL��Hbase,Cassandra�ȵȣ�
�����spark���������Spark������NoSQL�洢�в�ѯ���ݣ�api���ü��ɣ�
Hadoop
Spark
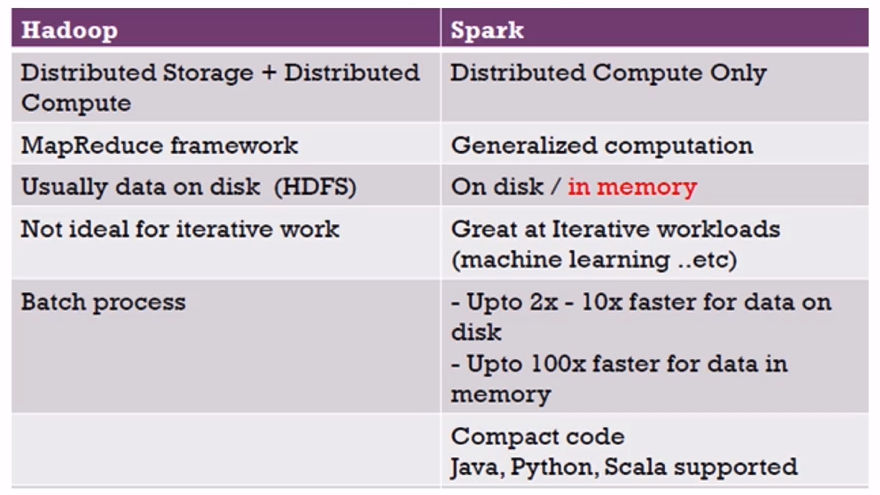
�ֲ�ʽ�洢+�ֲ�ʽ����
ֻ���ķֲ�ʽ����
MapReduce���
����ļ��㣨ͨ�õļ��㣨������-����ѧϰ�ȣ���
ͨ�����ݴ洢�ڴ����ϣ�HDFS��
���洢�ڴ������ִ洢���ڴ��У������ô洢���ԣ�
���ʺϵ�������
�ó���������������ѧϰ��
������
�����������ֿ��������������ϵ������ٶ�Ҫ�쵽2x-10x�����ڴ��ϵ������ٶ�Ҫ�쵽100x
һ��ʹ��java
֧��Java, Python, Scala��R��
iter����ҵ������
��1�������ڴ���㣬���ٵ�Ч�Ĵ��̽�����2����Ч�ĵ����㷨������DAG��3)�ݴ�����Linage���������־���DAG��Lingae
���ݹ�ģ
��ҵ����ƽ̨
Ӧ�÷�Χ
API��֧��python ��scala��java
�ڴ������
�ۺ϶���ӿ�ܽ���ʹ��
�����߶�����mrģ�������в��м���:
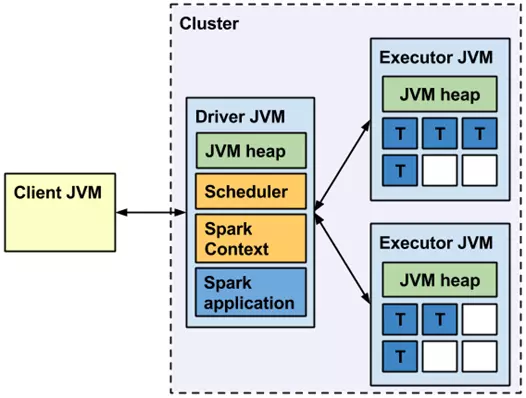
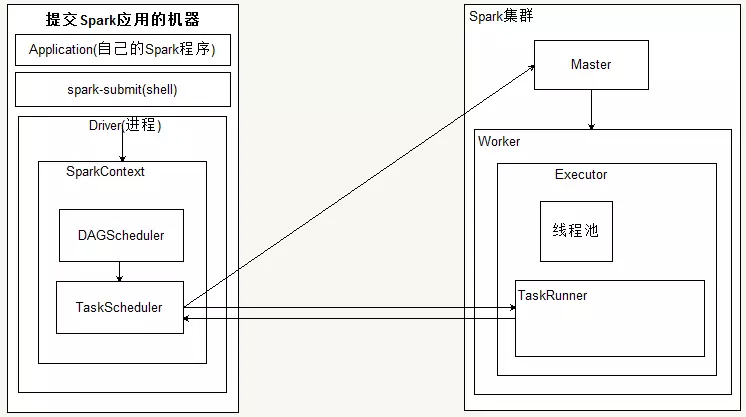
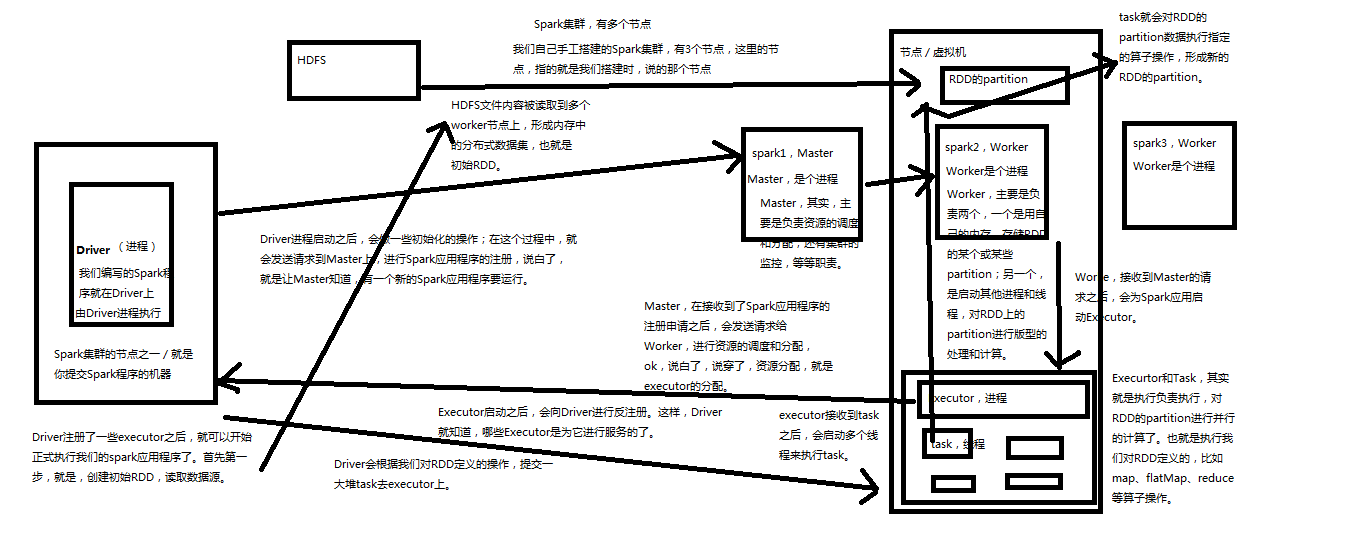
Spark���ͼ���£�Application ���û���д��Ӧ�ó����û��Զ����Spark�����û��ύ��SparkΪApp������Դ������ת����ִ�С�Driver Program ������Application��main()�������Ҵ���SparkContext��SparkContext :���û�����Spark��Ⱥ��Ҫ�Ľ����ӿڣ������Cluster Manager���н�����������Դ�����룬����ķ������أ�SparkContext����Driver��Worker Node ���ӽڵ㣬��Ⱥ�п�������Ӧ�ó���Ľڵ�,������Ƽ���ڵ㣬����Executor��Driver����YARNģʽ��ΪNodeManager���������ڵ�Ŀ��ơ�Executor ��ִ��������ΪijApplication������worker node�ϵ�һ�����̣�����ִ��task���ý��������ͨ���̳߳صķ�ʽ�������������������ݴ����ڴ���ߴ����ϡ�ÿ��Applicationӵ�ж�����һexecutors��RDD DAG ����RDD����Action���ӣ���֮ǰ�����������γ�һ��������ͼ��DAG��������Spark��ת��ΪJob���ύ����Ⱥ����ִ�С�һ��App���������Job��Task ����Executorִ�еĹ�����Ԫ��������Application��С�ĵ�λ�����task��ϳ�һ��stage��Task�ĵ��Ⱥ�����TaskScheduler����һ��������Ӧһ��Task��Taskִ��RDD�ж�ӦStage�������������ӡ�Task����װ�ú����Executor���̳߳���ִ�С�Job ��һ��job�������RDD����������ӦRDD�ϵĸ���Operation��ÿִ��һ��action���ӣ�foreach, count, collect, take, saveAsTextFile���ͻ�����һ�� job���������Task��ɵIJ��м��㡣Stage ��ÿ��Job��Task����ֳɺܶ���Task, ÿ��Task��Ϊһ��TaskSet������ΪStage��һ����ҵjob��Ϊ�����stages��shuffle�����У���һ��stage����һϵ�е�tasks�����У���Stage�ĵ��Ⱥͻ�����DAGScheduler����Stage�ַ�ΪShuffle Map Stage��Result Stage���֡�Stage�ı߽���ڷ���Shuffle�ĵط���RDD ��Spark�Ļ������ݲ���������ͨ��һϵ�����ӽ��в�����RDD��Spark����ĵĶ��������Ա������������л������ɱ䡢���ݴ����ƣ������ܲ��в��������ݼ��ϡ��洢����������ڴ棬Ҳ�����Ǵ��̡�DAG Scheduler ������Job��������Stage��DAG������������ͼ����ʵ�ֽ�Spark��ҵ�ֽ��һ�����Stage��ÿ��Stage����RDD��Partition��������Task�ĸ�����Ȼ��������Ӧ��Task set�ŵ�TaskScheduler�У����ύStage��TaskScheduler��TaskScheduler ����Task�ַ���Executorִ�У���ά��Task������״̬����Stage�ύWorker����Ⱥ�����У�ÿ��Executor����ʲô�ڴ˷��䡣SparkEnv ���̼߳���������ģ��洢����ʱ����Ҫ��������á��������� ��Application���������й����У�������ҪһЩ������ÿ��Task�ж�ʹ�ã�������������ʵ�ָ�Ŀ�ġ�Spark�����ֹ���������һ�ֻ��浽�����ڵ�Ĺ㲥������һ��ֻ֧�ּӷ�������ʵ����͵��ۼӱ����������� �����ΪShuffleDependency, ��������Ҫ��������и�RDD��Ӧ���������ݣ�Ȼ���ڽڵ�֮�����Shuffle��խ���� �����ΪNarrowDependency��ָij��RDD�������partition x��౻����RDD��һ������partion y������խ��������Map������Ҫ����shuffle����ˣ�խ������Taskһ�㶼�ᱻ�ϳ���һ�𣬹���һ��Stage��
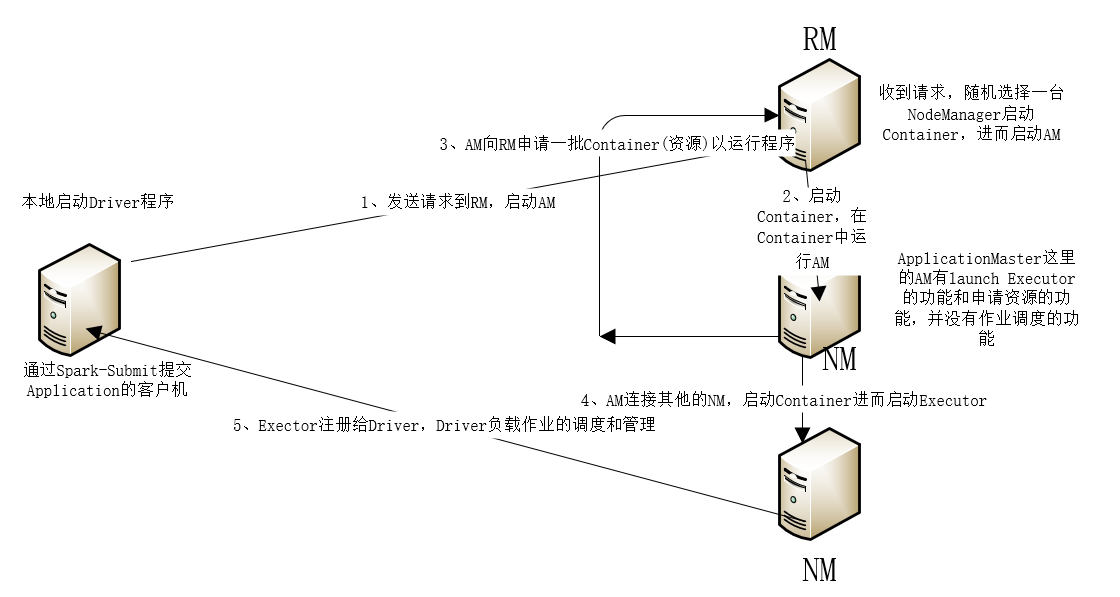
1������ģʽ
1���ڿͻ���ͨ��Spark-submit�ύһ��Application
�ܽApplicationmaster���ã�
client vs cluster
1��clientģʽDriver�ڿͻ������� ����
ע�����
1�� yarn��Ⱥ���ڵĽڵ������spark�İ�װ��
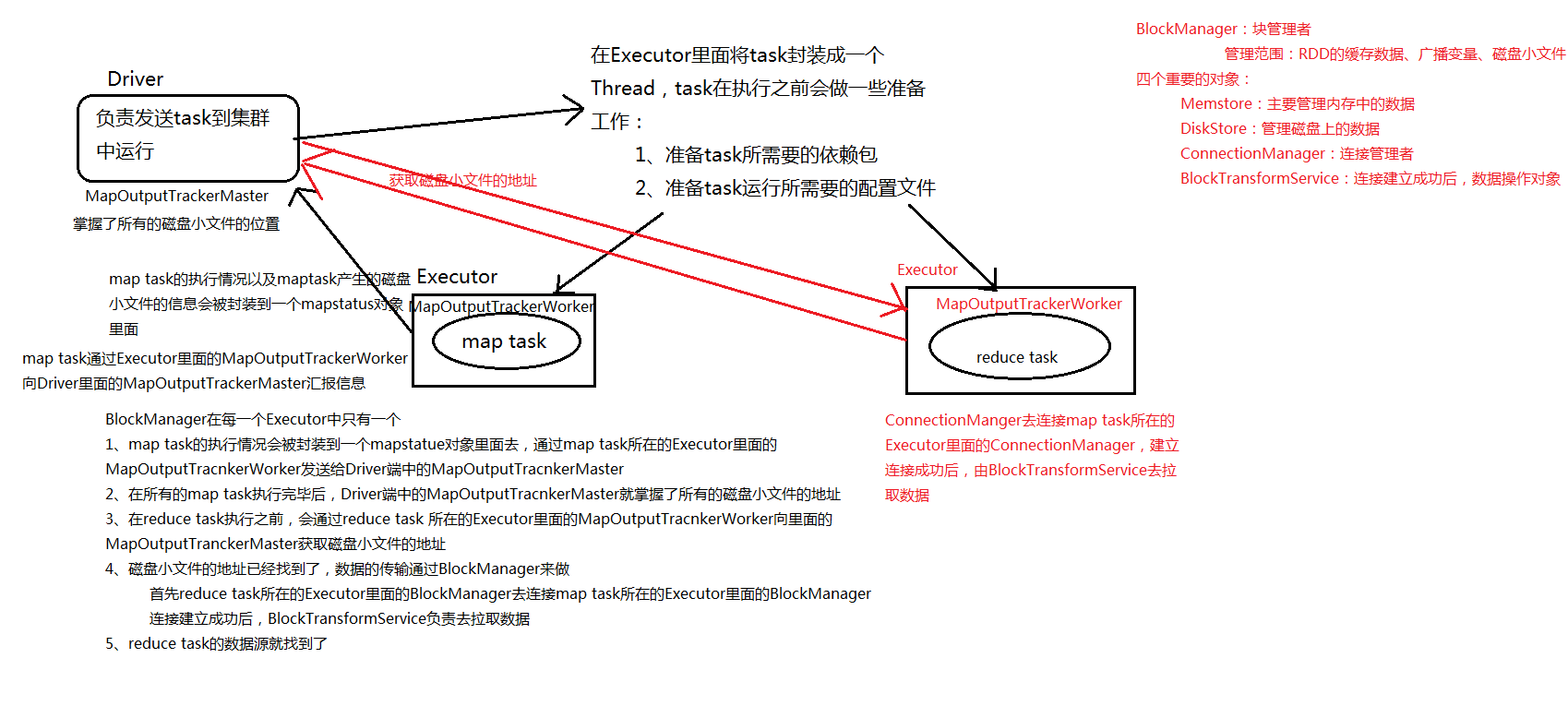
�ŵ� �����Dz������ݼ�ȱ�� ��������һЩ�����(�����������dz�������)����ɴ����ļ�(M*R,����M����Mapper�е����еIJ�������������R����Reducer�����еIJ�����������)�����ݵ��������I/O�����һ��γɴ�����Memory(�������OOM)��
����С�ļ��������ʲô���⣿
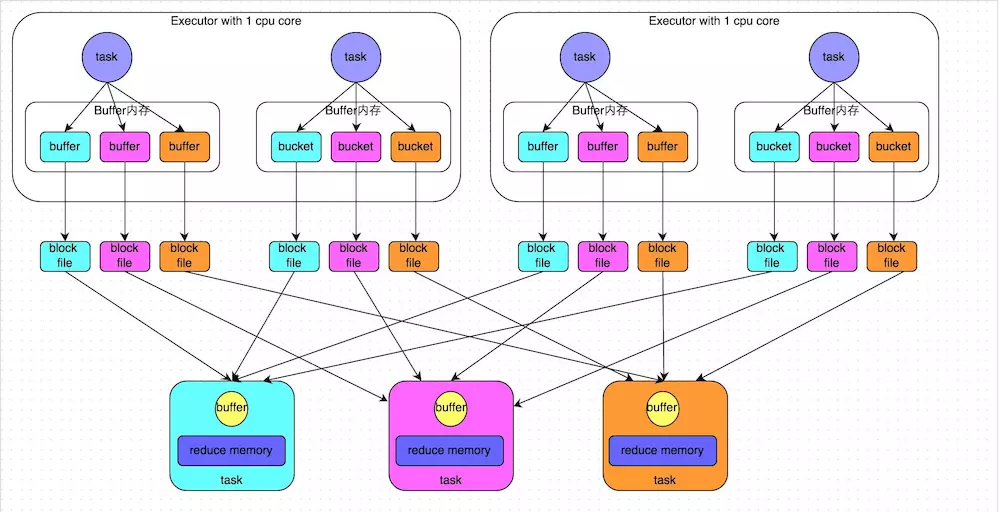
HashShuffleManager����������:
��һ�����ܹ��������ģ������
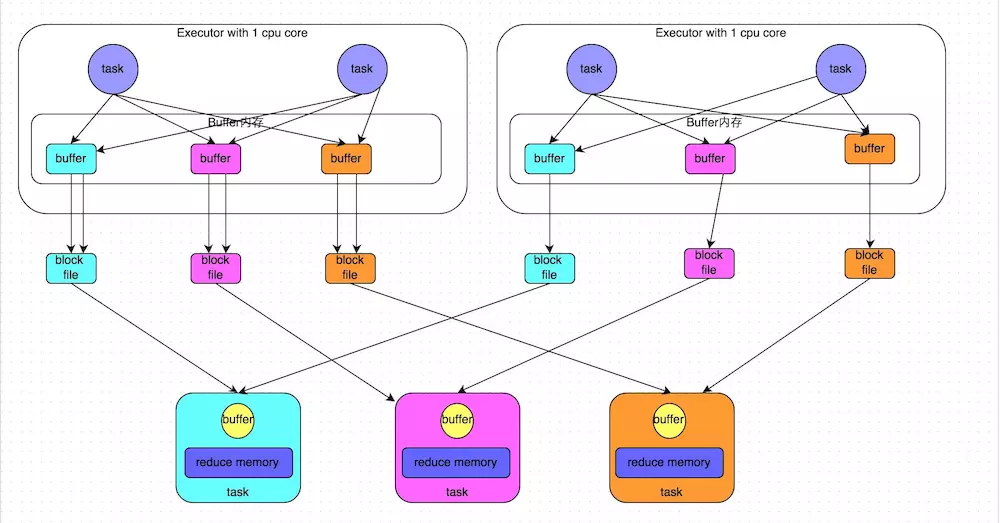
�Ľ����� ��Consolidate����:R��(C������Mapper�ˣ�ͬʱ�ܹ�ʹ�õ�cores������R����Reducer�����еIJ�����������)�����Ǵ�ʱ���Reducer�˵IJ������ݷ�Ƭ����Ļ���C R�����Ѿ�����ʱ����û�������ļ�����Ķ��ˣ�����Consolidate��û�н��Ͳ��жȣ�ֻ�ǽ�������ʱ�ļ�����������ʱMapper�˵��ڴ����ľͻ���٣�����OOMҲ�ͻή�ͣ�����һ������̵�����Ҳ���ø��á�
ǰ�ÿ��Excutor����1��cores������ڶ���stage��100��task����һ��stage��50��task���ܹ�������10��Executor��ÿ��Executorִ��5��task����ôԭ��ʹ��δ���Ż���HashShuffleManagerʱ��ÿ��Executor�����500�������ļ�������Executor�����5000�������ļ��ġ����Ǵ�ʱ�����Ż�֮��ÿ��Executor�����Ĵ����ļ��������ļ��㹫ʽΪ��CPU core������ * ��һ��stage��task���� ��Ҳ����˵��ÿ��Executor��ʱֻ�ᴴ��100�������ļ�������Executorֻ�ᴴ��1000�������ļ���
��Executor��CPU coreִ����һ��task������ִ����һ��taskʱ����һ��task�ͻḴ��֮ǰ���е�shuffleFileGroup���������еĴ����ļ���Ҳ����˵����ʱtask�Ὣ����д�����еĴ����ļ��У�������д���µĴ����ļ��С���ˣ�consolidate����������ͬ��task����ͬһ�������ļ��������Ϳ�����Ч�����task�Ĵ����ļ�����һ���̶��ϵĺϲ����Ӷ�����ȼ��ٴ����ļ�����������������shuffle write�����ܡ�
��Mapper�е�ÿһ��ShuffleMapTask�в��������ļ���Data�ļ���Index�ļ�������Data�ļ��Ǵ洢��ǰTask��Shuffle����ġ���index�ļ�����洢��Data�ļ��е�����ͨ��Partitioner�ķ�����Ϣ����ʱ��һ���ε�Stage�е�Task���Ǹ������Index�ļ���ȡ�Լ���Ҫץȡ����һ��Stage�е�ShuffleMapTask���������ݵģ�Reducer���Ǹ���index�ļ�����ȡ�����Լ������ݡ�
�漰���⣺Sorted-based Shuffle������� 2*M(M������Mapper���в��е�Partition������������ʵ����ShuffleMapTask��������)��Shuffle��ʱ�ļ���
SortShuffleManager������һ�������ļ�merge�Ĺ��̣���˴��������ļ������������һ��stage��50��task���ܹ���10��Executor��ÿ��Executorִ��5��task�����ڶ���stage��100��task������ÿ��task����ֻ��һ�������ļ�����˴�ʱÿ��Executor��ֻ��5�������ļ�������Executorֻ��50�������ļ�����ͨ����Sort-based Shuffle������ ��
Ĭ��Sort-based Shuffle�ļ���ȱ�� ��bypass���л���
��ͼ˵����bypass SortShuffleManager��ԭ����bypass���л��ƵĴ����������£�
shuffle map task����С��spark.shuffle.sort.bypassMergeThreshold������ֵ��
���Ǿۺ����shuffle���ӣ�����reduceByKey����
�ܽ�
spark.shuffle.file.buffer
Ĭ��ֵ��32k
����˵�����ò�����������shuffle write task��BufferedOutputStream��buffer�����С��������д�������ļ�֮ǰ������д��buffer�����У�������д��֮�Ż���д�����̡�
���Ž��飺�����ҵ���õ��ڴ���Դ��Ϊ����Ļ��������ʵ�������������Ĵ�С������64k�����Ӷ�����shuffle write��������д�����ļ��Ĵ�����Ҳ�Ϳ��Լ��ٴ���IO�����������������ܡ���ʵ���з��֣��������ڸò��������ܻ���1%~5%��������
spark.reducer.maxSizeInFlight
Ĭ��ֵ��48m
����˵�����ò�����������shuffle read task��buffer�����С�������buffer���������ÿ���ܹ���ȡ�������ݡ�
���Ž��飺�����ҵ���õ��ڴ���Դ��Ϊ����Ļ��������ʵ�������������Ĵ�С������96m�����Ӷ�������ȡ���ݵĴ�����Ҳ�Ϳ��Լ������紫��Ĵ����������������ܡ���ʵ���з��֣��������ڸò��������ܻ���1%~5%��������
Reduce taskȥmap�����ݣ�reduce һ��������һ�߾ۺ� reduce����һ��ۺ��ڴ棨executor memory��
���������
spark.shuffle.io.maxRetries
Ĭ��ֵ��3
����˵����shuffle read task��shuffle write task���ڽڵ���ȡ�����Լ�������ʱ�������Ϊ�����쳣������ȡʧ�ܣ��ǻ��Զ��������Եġ��ò����ʹ����˿������Ե��������������ָ������֮����ȡ����û�гɹ����Ϳ��ܻᵼ����ҵִ��ʧ�ܡ�
���Ž��飺������Щ�������ر��ʱ��shuffle��������ҵ��������������������������60�Σ����Ա�������JVM��full gc�������粻�ȶ������ص��µ�������ȡʧ�ܡ���ʵ���з��֣�������Գ�������������ʮ��~�ϰ��ڣ���shuffle���̣����ڸò������Դ���������ȶ��ԡ�
spark.shuffle.io.retryWait
Ĭ��ֵ��5s
����˵�����������ͬ�ϣ��ò���������ÿ��������ȡ���ݵĵȴ������Ĭ����5s��
���Ž��飺����Ӵ���ʱ��������60s����������shuffle�������ȶ��ԡ�
spark.shuffle.memoryFraction
Ĭ��ֵ��0.2
����˵�����ò���������Executor�ڴ��У������shuffle read task���оۺϲ������ڴ������Ĭ����20%��
���Ž��飺����Դ���������н�����������������ڴ���㣬���Һ���ʹ�ó־û�������������������������shuffle read�ľۺϲ��������ڴ棬�Ա��������ڴ治�㵼�¾ۺϹ�����Ƶ����д���̡���ʵ���з��֣��������ڸò������Խ���������10%���ҡ�
spark.shuffle.manager
Ĭ��ֵ��sort
����˵�����ò�����������ShuffleManager�����͡�Spark 1.5�Ժ���������ѡ�hash��sort��tungsten-sort��HashShuffleManager��Spark 1.2��ǰ��Ĭ��ѡ�����Spark 1.2�Լ�֮��İ汾Ĭ�϶���SortShuffleManager�ˡ�tungsten-sort��sort���ƣ�����ʹ����tungsten�ƻ��еĶ����ڴ�������ƣ��ڴ�ʹ��Ч�ʸ��ߡ�
���Ž��飺����SortShuffleManagerĬ�ϻ�����ݽ����������������ҵ��������Ҫ��������ƵĻ�����ʹ��Ĭ�ϵ�SortShuffleManager�Ϳ��ԣ���������ҵ��������Ҫ�����ݽ���������ô����ο�����ļ����������ţ�ͨ��bypass���ƻ��Ż���HashShuffleManager���������������ͬʱ�ṩ�ϺõĴ��̶�д���ܡ�����Ҫע����ǣ�tungsten-sortҪ���ã���Ϊ֮ǰ������һЩ��Ӧ��bug��
spark.shuffle.sort.bypassMergeThreshold
Ĭ��ֵ��200
����˵������ShuffleManagerΪSortShuffleManagerʱ�����shuffle read task������С�������ֵ��Ĭ����200������shuffle write�����в�������������������ֱ�Ӱ���δ���Ż���HashShuffleManager�ķ�ʽȥд���ݣ��������Ὣÿ��task������������ʱ�����ļ����ϲ���һ���ļ������ᴴ�������������ļ���
���Ž��飺����ʹ��SortShuffleManagerʱ�������ȷ����Ҫ�����������ô���齫�����������һЩ������shuffle read task����������ô��ʱ�ͻ��Զ�����bypass���ƣ�map-side�Ͳ�����������ˣ���������������ܿ������������ַ�ʽ�£���Ȼ����������Ĵ����ļ������shuffle write�����д���ߡ�
spark.shuffle.consolidateFiles
Ĭ��ֵ��false
����˵�������ʹ��HashShuffleManager���ò�����Ч���������Ϊtrue����ô�ͻῪ��consolidate���ƣ������Ⱥϲ�shuffle write������ļ�������shuffle read task�����ر�������£����ַ������Լ���ؼ��ٴ���IO�������������ܡ�
���Ž��飺�����ȷ����ҪSortShuffleManager��������ƣ���ô����ʹ��bypass���ƣ������Գ��Խ�spark.shffle.manager�����ֶ�ָ��Ϊhash��ʹ��HashShuffleManager��ͬʱ����consolidate���ơ���ʵ���г��Թ������������ܱȿ�����bypass���Ƶ�SortShuffleManagerҪ�߳�10%~30%��
rdd��һ�����Եķֲ�ʽ���ݼ����������һ�����ݽṹ����spark����ϵ�ͨ�û��ҡ�
RDD���Եķֲ�ʽ���ݼ��������
RDD��һϵ�е�Partition��ɵ�
ÿһ������ʵ������������ÿһ��partition��
rdd֮������������ϵ��
��ѡ��:������������KV��ʽ��RDD��
RDD���ṩһϵ����Ѽ���λ��,˵���˾��DZ�¶ÿһ��partitior��λ���������ݱ��ػ��Ļ���
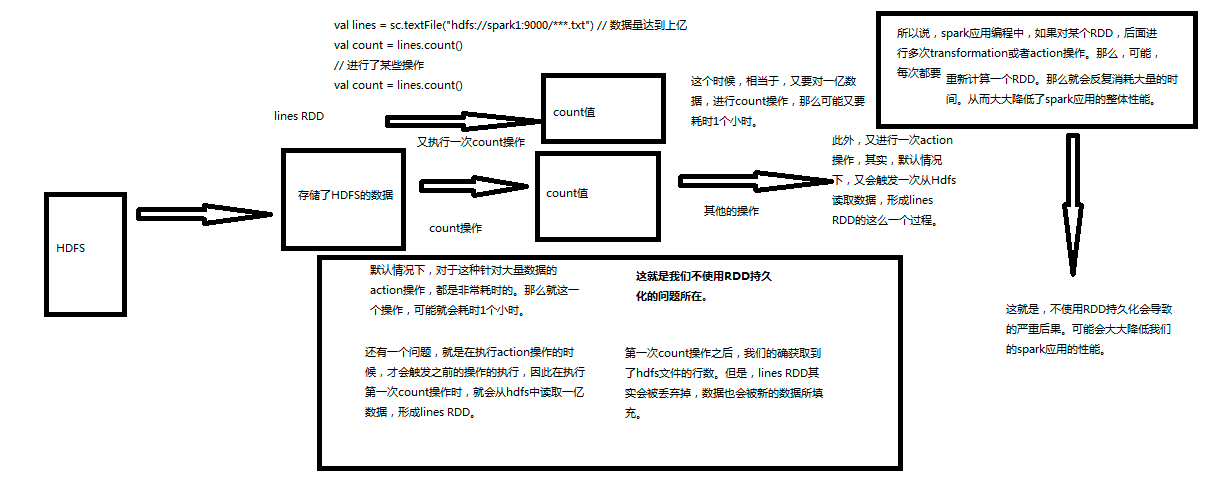
���ԣ��������RDD�ij־û����ƣ����ܶ�����ͬ��RDD�ļ�����Ҫ�ظ���HDFSԴͷ��ȡ���ݽ��м��㣬�������˷Ѻܶ�ʱ��ɱ���
Spark�dz���Ҫ��һ���������Ծ��ǿ��Խ�RDD�־û����ڴ��С�����RDDִ�г־û�����ʱ��ÿ���ڵ㶼�Ὣ�Լ�������RDD��partition�־û����ڴ��У�������֮��Ը�RDD�ķ���ʹ���У�ֱ��ʹ���ڴ滺���partition�������Ļ����������һ��RDD����ִ�ж�������ij�������ֻҪ��RDD����һ�μ��ɣ�����ֱ��ʹ�ø�RDD��������Ҫ���������θ�RDD��
����ʹ��RDD�־û���������ijЩ�����£����Խ�sparkӦ�ó������������10�������ڵ���ʽ�㷨�Ϳ��ٽ���ʽӦ����˵��RDD�־û����Ƿdz���Ҫ�ġ�
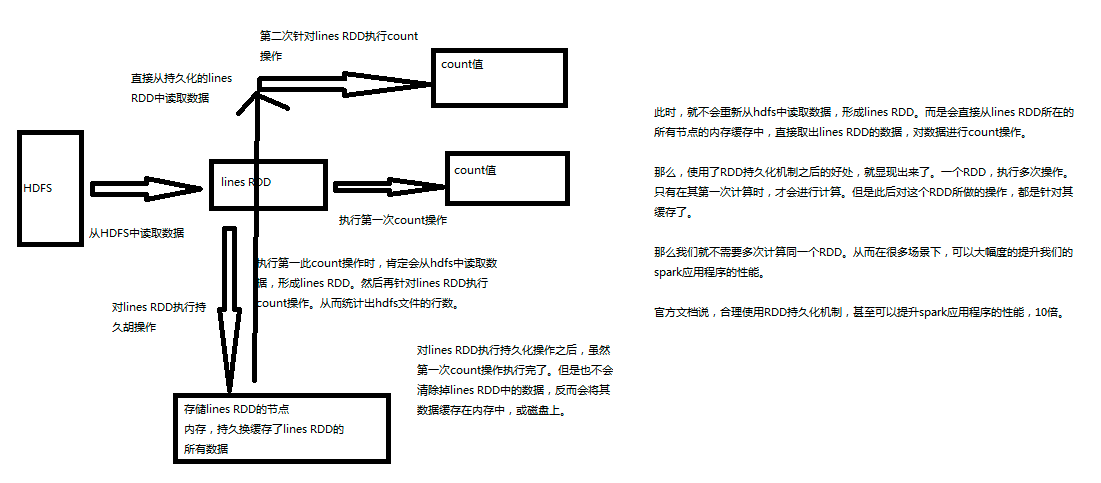
Ҫ�־û�һ��RDD��ֻҪ������cache()����persist()�������ɡ��ڸ�RDD��һ�α��������ʱ���ͻ�ֱ�ӻ�����ÿ���ڵ��С�����Spark�ij־û����ƻ����Զ��ݴ��ģ�����־û���RDD���κ�partition��ʧ�ˣ���ôSpark���Զ�ͨ����ԴRDD��ʹ��transformation�������¼����partition ��
1��cache��persist�������ڽ�һ��RDD���л���ģ�������֮��ʹ�õĹ����оͲ���Ҫ���¼����ˣ����Դ���ʡ��������ʱ�䣻2�� cacheֻ��һ��Ĭ�ϵĻ��漶��MEMORY_ONLY ��cache������persist����persist���Ը���������������Ļ��漶��3��executorִ�е�ʱ��Ĭ��60%��cache��40%��task������persist������ĺ�������ײ�ĺ����������Ҫ���ڴ���������棬��ô����ʹ��unpersist()������
Spark�Լ�Ҳ����shuffle����ʱ���������ݵij־û�������д����̣���Ҫ��Ϊ���ڽڵ�ʧ��ʱ��������Ҫ���¼����������̡�
Spark ��һ������Ҫ�������ǽ����ݳ־û������Ϊ���棩���ڶ�������䶼���Է�����Щ�־û������ݡ����־û�һ�� RDD ʱ��ÿ���ڵ����������������ʹ�� RDD ���ڴ��н��м��㣬�ڸ������ϵ����� action ������ֱ��ʹ���ڴ��е����ݡ����������Ժ�� action ���������ٶȼӿ죨ͨ�������ٶȻ���� 10�����������ǵ����㷨�Ϳ��ٵĽ���ʽʹ�õ���Ҫ���ߡ�
RDD ����ʹ��persist() ������ cache() �������г־û������ݽ����ڵ�һ�� action ����ʱ���м��㣬�������ڽڵ���ڴ��� ��Spark �Ļ�������ݴ����ƣ����һ������� RDD ��ij��������ʧ�ˣ�Spark ������ԭ���ļ�����̣��Զ����¼��㲢���л��档
���⣬ÿ���־û��� RDD ����ʹ�ò�ͬ�Ĵ洢������л��棬���磬�־û������̡������л��� Java ������ʽ�־û����ڴ棨���Խ�ʡ�ռ䣩����ڵ�临�ơ��� off-heap �ķ�ʽ�洢�� Tachyon����Щ�洢����ͨ������һ�� **StorageLevel ����Scala��Java��Python���� persist() �����������á�cache()**������ʹ��Ĭ�ϴ洢����Ŀ�����÷�����Ĭ�ϵĴ洢������ StorageLevel.MEMORY_ONLY ���������л��Ķ���洢���ڴ��У�����ϸ�Ĵ洢����������� :
MEMORY_ONLY : �� RDD �Է����л� Java �������ʽ�洢�� JVM �С�����ڴ�ռ䲻�����������ݷ��������ٻ��棬��ÿ����Ҫ�õ���Щ����ʱ���½��м��㡣����Ĭ�ϵļ���MEMORY_AND_DISK : �� RDD �Է����л� Java �������ʽ�洢�� JVM �С�����ڴ�ռ䲻������δ��������ݷ����洢�����̣�����Ҫʹ����Щ����ʱ�Ӵ��̶�ȡ��MEMORY_ONLY_SER : �� RDD �����л��� Java �������ʽ���д洢��ÿ������Ϊһ�� byte ���飩�����ַ�ʽ��û�����л�����ķ�ʽ��ʡ�ܶ�ռ䣬��������ʹ�� fast serializerʱ���ʡ����Ŀռ䣬�����ڶ�ȡʱ������ CPU �ļ��㸺����MEMORY_AND_DISK_SER : ������ MEMORY_ONLY_SER ����������ķ�����洢�����̣����������õ�����ʱ���¼��㡣DISK_ONLY : ֻ�ڴ����ϻ��� RDD��MEMORY_ONLY_2 ��MEMORY_AND_DISK_2���ȵ� : ������ļ�������ͬ��ֻ����ÿ�������ڼ�Ⱥ�������ڵ��Ͻ���������OFF_HEAP ��ʵ���У�: ������ MEMORY_ONLY_SER �����ǽ����ݴ洢�� off-heap memory������Ҫ���� off-heap �ڴ档
ע�⣬�� Python �У�����Ķ�������ʹ�� Pickle �������л��������� Python �в�������ѡ�������һ�����л�����python �еĴ洢������� MEMORY_ONLY��MEMORY_ONLY_2��MEMORY_AND_DISK��MEMORY_AND_DISK_2��DISK_ONLY�� DISK_ONLY_2 ��reduceByKey �����������û�û�е��� persist ������Spark Ҳ���Զ����沿���м����ݡ���ô����Ŀ���ǣ��� shuffle �Ĺ�����ij���ڵ�����ʧ��ʱ������Ҫ���¼������е��������ݡ�����û�����ʹ��ij�� RDD��ǿ���Ƽ��ڸ� RDD �ϵ��� persist ������
���ѡ��洢����
Spark �Ĵ洢�����ѡ�������������ڴ�ʹ���ʺ� CPU Ч��֮�����Ȩ�⡣���鰴����Ĺ��̽��д洢�����ѡ�� :
���ʹ��Ĭ�ϵĴ洢����MEMORY_ONLY �����洢���ڴ��е� RDD û�з����������ô��ѡ��Ĭ�ϵĴ洢����Ĭ�ϴ洢����������̶ȵ���� CPU ��Ч��,����ʹ�� RDD �ϵIJ����������ٶ����С�
����ڴ治��ȫ���洢 RDD����ôʹ�� MEMORY_ONLY_SER ������ѡһ���������л��⽫�������л����Խ�ʡ�ڴ�ռ䡣ʹ�����ִ洢���𣬼����ٶ���Ȼ�ܿ졣
�����ڼ�������ݼ��Ĵ����ر�ߣ���������Ҫ���˴������ݵ�����£�������Ҫ����������ݴ洢�����̡���Ϊ�����¼���������ݷ����ĺ�ʱ��Ӵ��̶�ȡ��Щ���ݵĺ�ʱ��ࡣ
�������ٻ�ԭ���ϣ�����ʹ�öั���洢�������磬ʹ�� Spark ��Ϊ web Ӧ�õĺ�̨�����ڷ��������ʱ��Ҫ���ٻָ��ij����£������еĴ洢����ͨ�����¼��㶪ʧ�����ݵķ�ʽ���ṩ����ȫ�ݴ����ơ����Ƕั�������ڷ������ݶ�ʧʱ������Ҫ���¼����Ӧ�����ݿ⣬����������������С�
ɾ��RDD
Spark �Զ���ظ����ڵ��ϵĻ���ʹ���ʣ������������ʹ�õķ�ʽ��LRU���������ݿ��Ƴ��ڴ档������ֶ��Ƴ�һ�� RDD�������ǵȴ��� RDD �� Spark�Զ��Ƴ�������ʹ�� RDD.unpersist()������
һ��StreamingӦ�ó���Ҫ��7��24Сʱ��������У���˱�����Ӧ���ֵ���Ӧ�ó���ʧ�ܵij�����Spark Streaming�ļ�������ݴ����ƣ����㹻����Ϣ�ܹ�֧�ֹ��ϻָ���֧�������������͵ļ��㣺Ԫ���ݼ�������ݼ��㡣
��1��Ԫ���ݼ��㣬������HDFS���ݴ��洢�ϣ�����Streaming������Ϣ�����ּ��������ָ�����StreamingӦ�ó���ʧ�ܵ�Driver���̡�
��2�����ݼ��㣬�ڽ��п�Խ������κϲ����ݵ���״̬����ʱ������Ҫ��������ת����������£�����ǰһ���ε�RDD�����µ�RDD������ʱ�䲻�����ӣ�RDD�������ij���Ҳ�����ӣ�Ϊ�˱��������������ӻָ�ʱ��������ͨ�����ڼ�齫ת��RDD���м�״̬���пɿ��洢�������ж��������ӵ�������ʹ����״̬��ת�������updateStateByKey����reduceByKeyAndWindow��Ӧ�ó�����ʹ�ã���ô��Ҫ�ṩ����·������RDD���������Լ�顣
Ԫ���ݼ�����Ҫ�����ָ�ʧ�ܵ�Driver���̣������ݼ�����Ҫ�����ָ���״̬��ת��������������Driverʧ�ܣ�����Workerʧ�ܣ����ּ�����ƶ��ܿ��ٻָ�������Spark Streaming����ʹ�ü��㷽ʽ�����Ǽ�StreamingӦ�ó�������״̬ת�������������м��㣻��Driver��������лָ����ܻ����һЩ�յ�û�д��������ݶ�ʧ��
Ϊ����һ��Spark Streaming�����ܹ����ָ�����Ҫ���ü��㣬��������һ���ݴ��ġ��ɿ����ļ�ϵͳ����HDFS��S3�ȣ�·�����������Ϣ��ͬʱ����ʱ������
streamingContext.checkpoint(checkpointDirectory)//checkpointDirectory
def functionToCreateContext ( ) : StreamingContext = {
val ssc = new StreamingContext ( . . . )
val DsSream = ssc. socketTextStream ( . . . )
. . .
ssc. checkpoint ( checkpointDirectory)
ssc
}
val context = StreamingContext. getOrCreate ( checkpointDirectory, functionToCreate- Context_)
context. . . .
context. start ( )
context. awaitTermination ( )
ͨ��ʹ��getOrCreate����StreamingContext��
���ǣ�Streaming��Ҫ�����м����ݵ��ݴ��洢ϵͳ��������Ի�����洢�������������ܻᵼ����Ӧ��������ʱ��䳤����ˣ������ʱ������Ҫ�������á���ȡС����ʱ��ÿ���μ�������������ٲ��������������෴������̫�ٿ��ܻᵼ��ÿ���������С�����ӡ�����RDD�������״̬ת���������������Ĭ�����ó�DStream�Ļ��������5~10����
���ϻָ�����ʹ��Spark��Standaloneģʽ�Զ���ɣ���ģʽ�����κ�SparkӦ�ó����Driver�ڼ�Ⱥ������������ʧ��ʱ������������YARN��Mesos�����IJ����������ͨ�������Ļ�������Driver��
1.�־û�ֻ�ǽ����ݱ�����BlockManager�У���RDD��lineage�Dz���ġ�����checkpointִ�����RDD�Ѿ�û��֮ǰ��ν������RDD�ˣ���ֻ��һ��ǿ��Ϊ�����õ�checkpointRDD��RDD��lineage�ı��ˡ�
2.�־û������ݶ�ʧ�����Ը����̡��ڴ涼���ܻ�������ݶ�ʧ�����������checkpoint������ͨ���Ǵ洢����HDFS���ݴ����߿��õ��ļ�ϵͳ�����ݶ�ʧ�����Խ�С��
ע��Ĭ������£����ij��RDDû�г־û�������������checkpoint����������⣬�������job��ִ�н����ˣ����������м�RDDû�г־û���checkpoint job��Ҫ��RDD������д���ⲿ�ļ�ϵͳ�Ļ�����Ҫȫ�����¼���һ�Σ��ٽ����������RDD����checkpoint���ⲿ�ļ�ϵͳ�����ԣ������checkpoint()��RDDʹ��persist(StorageLevel.DISK_ONLY)����RDD����֮��ֱ�ӳ־û��������ϡ��������checkpoint����ʱ�Ϳ���ֱ�ӴӴ����϶�ȡRDD�����ݣ���checkpoint���ⲿ�ļ�ϵͳ��
1���Զ��Ľ����ڴ�ʹ��̵Ĵ洢�л���
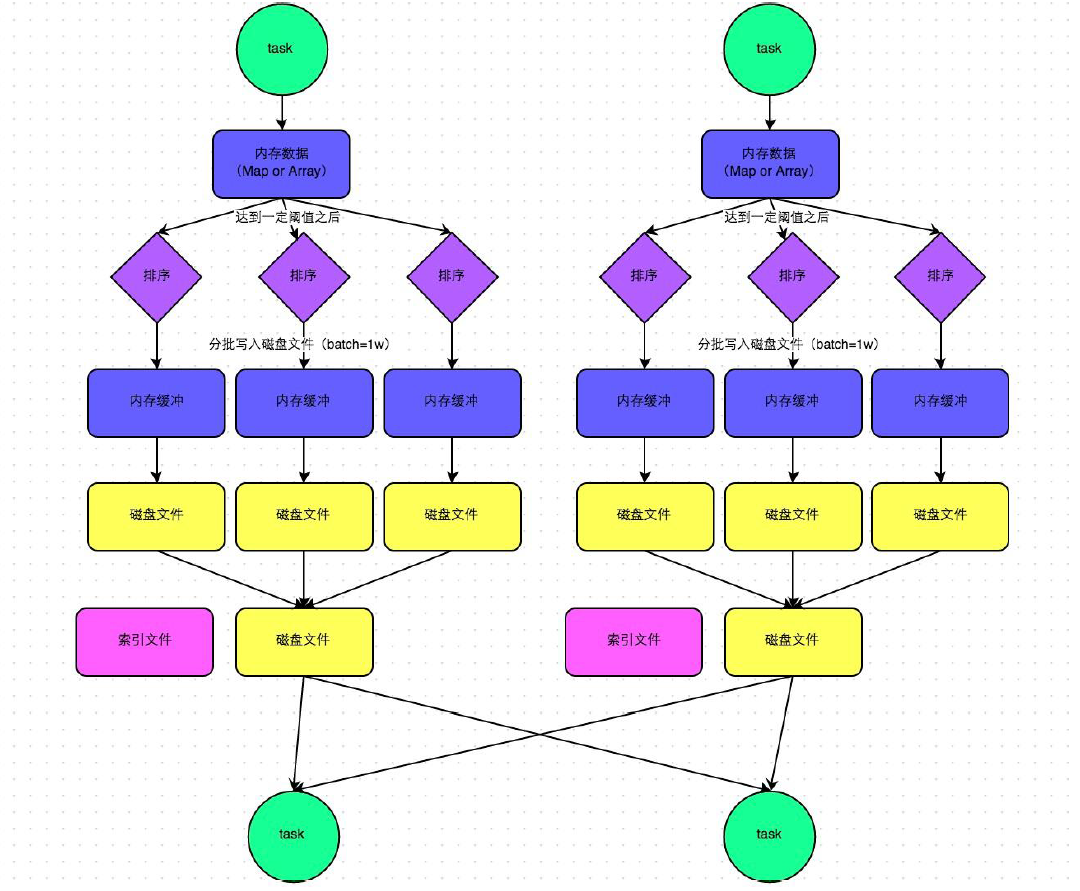
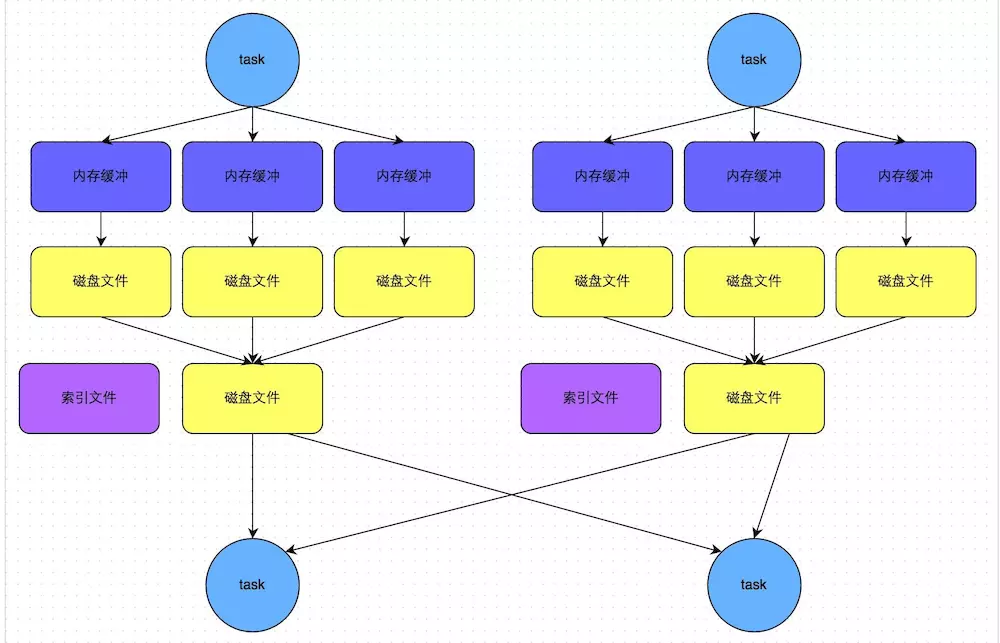
1����֧��ϸ���ȵ�д���²��������������棩��sparkд�����Ǵ����ȵ�
1).ʹ�ó����еļ��ϴ���rdd
1��lazy��¼�����ݵ���Դ��RDD�Dz��ɱ�ģ�����lazy����ģ���rDD֮�乹����������lazy�ǵ��ԵĻ�ʯ������RDD���ɱ䣬����ÿ�β����Ͳ����µ�rdd��������ȫ���ĵ����⣬�����Ѷ��½��������м������������Ӽ��������洢�����������ʱ��Ӻ���ǰ����900������һ��stage�Ľ�����Ҫô��checkpoint
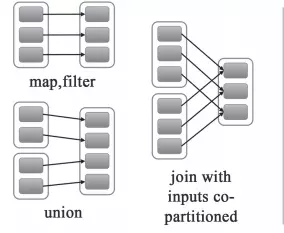
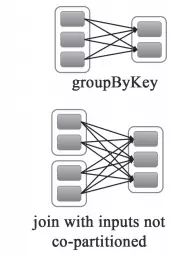
Spark��RDD�ĸ�Ч��DAG��������ͼ���кܴ�Ĺ�ϵ����DAG��������Ҫ�Լ���Ĺ��̻���Stage�����ֵ����ݾ���RDD֮���������ϵ��RDD֮���������ϵ��Ϊ���֣�������(wide dependency/shuffle dependency)��խ������narrow dependency��1.խ����
һ����һ��һ����������OneToOneDependency
����һ���Ƿ�Χ����������RangeDependency����������org.apache.spark.rdd.UnionRDDʹ�á�UnionRDD�ǰѶ��RDD�ϳ�һ��RDD����ЩRDD�DZ�ƴ�Ӷ��ɣ���ÿ��parent RDD��Partition�����˳��䣬ֻ����ÿ��parent RDD��UnionRDD�е�Partition����ʼλ�ò�ͬ
2.������ 3.խ������խ�����Ƚ�
������������Ӧ��shuffle��������Ҫ�����еĹ����н�ͬһ��RDD�������뵽��ͬ��RDD�����У��м�����漰������ڵ�֮�����ݵĴ��䣬��խ������ÿ����RDD����ͨ��ֻ�ᴫ�뵽��һ����RDD������ͨ����һ���ڵ�����ɡ�
��RDD������ʧʱ������խ������˵�����ڸ�RDD��һ������ֻ��Ӧһ����RDD����������ֻ��Ҫ���¼�������RDD������Ӧ�ĸ�RDD�������С������������ݵ�������100%��
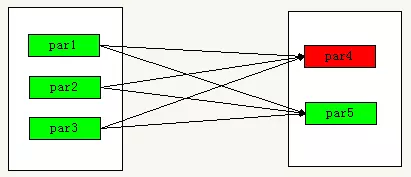
��RDD������ʧʱ�����ڿ�������˵������ĸ�RDD����ֻ��һ���������Ƕ�Ӧ��ʧ����RDD�����ģ���һ���־�����˶���ļ��㡣�������е���RDD����ͨ�����Զ����RDD��������������£����и�RDD���п������¼��㡣����ͼ��par4��ʧ������Ҫ���¼���par1,par2,par3,��������������par5
������ʧͼ4.��������խ��������
խ�����ĺ����У�
�������ĺ����У�
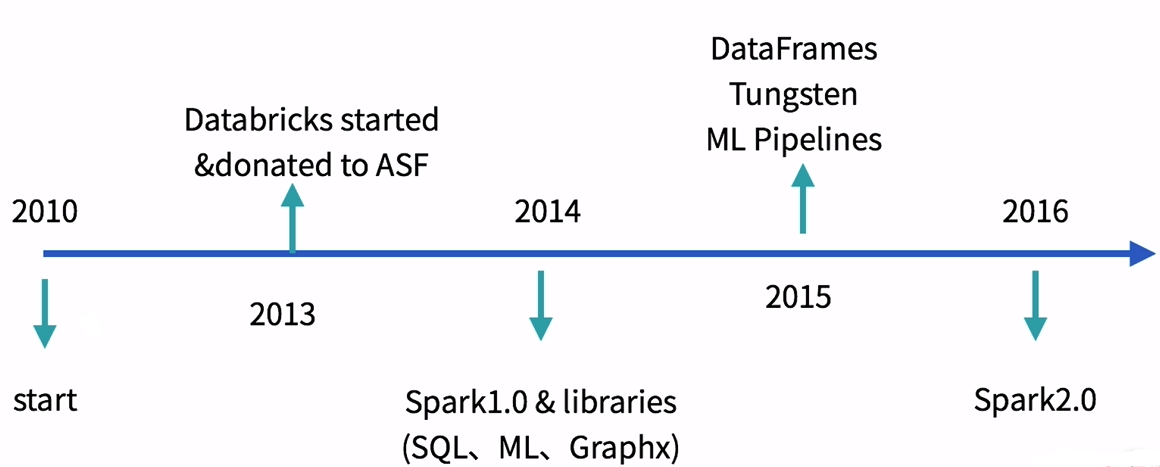
 ��������
��������