Ŀ¼��
2��Spark��װ����
2.1��Spark��װ����
2.1.1��Spark���أ�
2.1.2����װǰ����
2.1.3�����û���������
2.1.4������Spark������
2.1.5������Spark��Ⱥ
2.2��Spark�е�Scale��shell
2.3��Spark���ĸ�����
2.4������Ӧ��
2.4.1����ʼ��SparkContext
2.4.2����������Ӧ��
2��Spark��װ����
2.1��Spark��װ����
2.1.1��Spark���أ�
���ص�ַ��http://spark.apache.org/downloads.html

Ϊ�˷���Ҳ���Խ��뵽��Ŀ¼��ʹ���������أ�
[hadoop@rdb1 ~]$ wget https://d3kbcqa49mib13.cloudfront.net/spark-2.2.0-bin-hadoop2.6.tgz
2.1.2����װǰ����
�ļ���ѹ�������
[hadoop@rdb1 ~]$ tar �Czxvf spark-2.2.0-bin-hadoop2.6.tgz �CC ./spark-2.2.0
2.1.3�����û���������
vi /etc/profile

2.1.4������Spark������
��spark-2.2.0�ļ��У�
[hadoop@rdb1 spark-2.2.0]$ cd spark-2.2.0
�˴���Ҫ���õ��ļ�Ϊ������
spark-env.sh��slaves
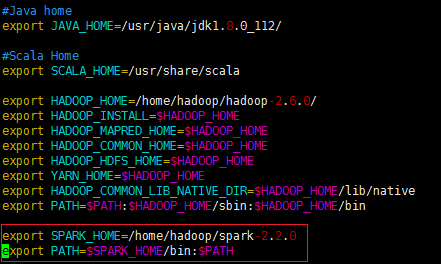
�������ǰѻ�����ļ�spark-env.sh.template��Ϊsparkʶ����ļ�spark-env.sh
[hadoop@rdb1 spark-2.2.0]$ cp conf/spark-env.sh.template conf /spark-env.sh
1����spark-env.sh�ļ���
[hadoop@rdb1 spark-2.2.0]$ vi conf/spark-env.sh
��ĩβ���ϣ�

����˵����
��JAVA_HOME��Java��װĿ¼
��SCALA_HOME��Scale��װĿ¼
��SPARK_MASTER_IP��spark��Ⱥ��Master�ڵ��ip��ַ
��SPARK_WORKER_MEMORY��ÿ��worker�ڵ��ܹ��������exectors���ڴ��С
2����slaves�ļ���
[hadoop@rdb1 spark-2.2.0]$ vi conf/slaves.template
�����ǵ����棬��ֱ����ĩβ����localhost

2.1.5������Spark��Ⱥ
1������Hadoop��HDFS�ļ�ϵͳ��
start-dfs.sh
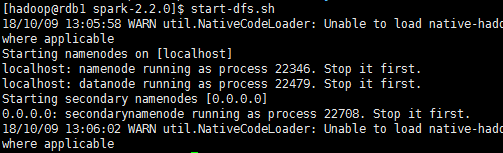
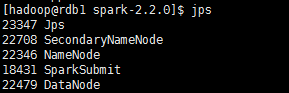
����֮��ʹ��jps������Բ鿴��rdb1�Ѿ�������namenode,˵��Hadoop��HDFS�ļ�ϵͳ�Ѿ������ˡ�
2������Spark��
��Ϊhadoop/sbin�Լ�spark/sbin�����õ���ϵͳ�Ļ����У�����ͬһ���ļ����´���ͬ����start-all.sh�ļ�������Ǵ�spark-2.2.0�����ļ���������ļ���
./sbin/start-all.sh

�ɹ���ʹ��jps��rdb1���ڵ��Ͽ��Բ鿴�¿�����Master��Worker���̡�
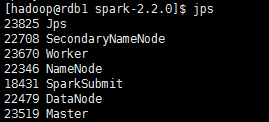
�ɹ���Spark��Ⱥ֮����Խ���Spark��WebUI���棬����ͨ����SparkMaster_IP:8080���ʣ�
�ɼ���һ���������е�Worker�ڵ㡣
http://192.1.101.61:8080/

3����Spark-shell
ʹ��spark-shell��ɴ�Spark��shell��

�ɹ�������Ҳ����ͨ��SparkMaster_IP:4040����WebUI�鿴��ǰִ�е�����
http://192.1.101.61:4040/

2.2��Spark�е�Scale��shell
Spark���н���ʽ��shell����������ʱ���ݷ�����Spark shell��������shell���߲�һ�����ǣ�������shell��������ֻ��ʹ�õ�����Ӳ�̺��ڴ����������ݣ���Spark shell��������ֲ�ʽ�洢������������ڴ����Ӳ���ϵ����ݽ��н��������Ҵ������̵ķַ���Spark�Զ�������ɡ�
���� Spark �ܹ��ڹ����ڵ��ϰ����ݶ�ȡ���ڴ��У���������ֲ�ʽ���㶼�����ڼ�����֮����ɣ�������������ʮ�����ڵ��ϴ��� TB ��������ݵļ��㡣���ʹ��һ����Ҫ��shell ����ɵ���Щ����ʽ�ļ�ʱ̽���Է�����÷dz��ʺ� Spark��Spark �ṩ Python �Լ�Scala ����ǿ�� shell��֧���뼯Ⱥ�����ӡ�
��Scale�汾��shell��bin/spark-shell��
�� Spark �У�����ͨ���Էֲ�ʽ���ݼ��IJ������������ǵļ�����ͼ����Щ������Զ����ڼ�Ⱥ�ϲ��н��С����������ݼ�����Ϊ���Էֲ�ʽ���ݼ���resilient distributed dataset������� RDD��RDD �� Spark �Էֲ�ʽ���ݺͼ���Ļ�������
����ʹ��shell�ӱ����ļ��д���һ��RDD����һЩ�ļ�ʱͳ�ơ�
//Scale����ͳ��
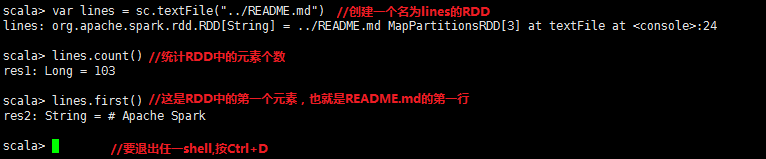
2.3��Spark���ĸ�����
���ϲ�������ÿ��SparkӦ�ö���һ������������driver program��������Ⱥ�ϵIJ��в������������������Ӧ�õ�main���������Ҷ����˼�Ⱥ�ϵķֲ�ʽ���ݼ���������Щ���ݼ�Ӧ������ز�������ǰ��������ʵ�ʵ��������������Spark shell��������ֻ��Ҫ������Ҫ���еIJ����Ϳ����ˡ�
����������ͬһ��SparkContext����������Spark�������������Լ��㼯Ⱥ�����ӡ�shell����ʱ�Ѿ��Զ�������һ��SparkContext������һ������sc�ı�����
�鿴����sc��

һ������SparkContext���Ϳ�������������RDD������sc.textFile()������һ�������ļ��и����ı���RDD�����ǿ�������Щ���Ͻ��и��ֲ���������count()��
Ҫִ����Щ����������������һ��Ҫ�������ִ����(executor)�ڵ㡣���磬����Ҫ�ڼ�Ⱥ������count()������Ҫô��ͬ�Ľڵ��ͳ���ļ��IJ�ͬ���ֵ��������������Ǹղ����ڱ���ģʽ������Spark shell��������еĹ������ڵ��ڵ���ִ�У�������Խ����shell���ӵ���Ⱥ�������в��е����ݷ�����
spark����ڼ�Ⱥ�����У�

��������кܶ��������ݺ�����API�����Խ���Ӧ���������ڼ�Ⱥ�ϡ����磬������չ���ǵ�READMEʾ����ɸѡ���ļ��а���ij���ض����ʵ��С��ԡ�Python���������Ϊ����Scale�汾��������:

Spark API������ĵط���������filter�������ں����IJ���Ҳ���ڼ�Ⱥ�ϲ���ִ�С�Ҳ����˵��Spark���Զ�������������line.contains(��Python��)����������ִ�����ڵ��ϡ������Ϳ����ڵ�һ�������������б�̣����Ҵ����Զ������ڶ���ڵ��ϡ�
2.4������Ӧ��
����shell��ʹ�õ�����������Ҫ���г�ʼ��SparkContext��
����Spark�����ڸ������в���һ������Java��Scale�У�ֻ��Ҫ�����Ӧ������һ������spark-core��maven������
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-mllib_2.10 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.10</artifactId>
<version>2.2.0</version>
<scope>provided</scope>
</dependency>
2.4.1����ʼ��SparkContext
һ�������Ӧ����Spark�����ӣ�����������Ҫ����ij����е���Spark�����Ҵ���SparkContext�������ͨ���ȴ���һ��SparkConf�������������Ӧ�á�Ȼ��������SparkConf����һ��SparkContext����
��Java�г�ʼ��Spark��
SparkConf conf = new SparkConf().setMaster(��local��).setAppName(��My App��);
JavaSparkContext sc = new JavaSparkContext(conf);
����SparkContextֻ��Ҫ��������������
��ȺURL������Spark������ӵ���Ⱥ�ϡ�
Ӧ�����������ӵ���Ⱥʱ�����ֵ�����������ڼ�Ⱥ���������û��������ҵ����ǵ�Ӧ�á�
�ڳ�ʼ��SparkContext֮����ʹ������ǰ��չʾ�����з���(���������ı��ļ�)������RDD���������ǡ�
��ر�Spark���Ե���SparkContext��stop()����������ֱ���˳�Ӧ��(����System.exit(0))��
2.4.2����������Ӧ��
Java�汾������ͳ��Ӧ�ã�
