ת��https://www.jianshu.com/p/a27f5f5f14e5�� https://blog.csdn.net/feloxx/article/details/72819964
һ����� Spark SQL��Spark�д����ṹ�����ݵ�ģ�顣�������Spark RDD API��ͬ��Spark SQL�Ľӿ��ṩ�˸���������ݵĽṹ��Ϣ�ͼ������������ʱ��Ϣ����Spark�ڲ���Spark SQL���ܹ��������Ż�����Ϣ��RDD API����һЩ��Spark SQL����������ֲ�ͬ��API��SQL��䡢DataFrame API�����µ�Dataset API�������������м����ʱ��������ʹ������API�����ԣ�Spark SQLʹ�õ�ִ�����涼��ͬһ�������ֵײ��ͳһ��ʹ�����߿����ڲ�ͬ��API֮�������л��������ѡ��һ������Ȼ�ķ�ʽ���������������
�������� 1. SQL�� Spark SQL��һ���÷���ֱ��ִ��SQL��ѯ��䣬���ʹ���������SQL���Ҳ����ѡ��HiveQL���Spark SQL���Դ����е�Hive�ж�ȡ���ݡ�����ϸ����ο�Hive Tables ��һ�ڡ���������������������SQL��Spark SQL����DataFrame ���ؽ�����㻹����ͨ��������command-line ���� JDBC/ODBC ʹ��Spark SQL��
2. DataFrame�� ��һ�ֲַ�ʽ���ݼ��ϣ�ÿһ�����ݶ��ɼ��������ֶ���ɡ���������˵������ϵ�����ݿ�ı� ���� R��Python�е�data frame�ȼۣ�ֻ�����ڵײ㣬DataFrame�����˸����Ż���DataFrame���ԴӺܶ�����Դ��sources ���������ݲ�����õ����磺�ṹ�������ļ���Hive�еı����ⲿ���ݿ⣬�������е�RDD��Scala , Java , Python , and R ��
3. Datasets�� ��Spark-1.6������һ��API��Ŀǰ����ʵ���Եġ�Dataset��Ҫ��RDD�����ƣ�ǿ���ͣ�����ʹ��lambda����ʽ��������Spark SQL���Ż�ִ����������ƽ�ϵ�һ��Dataset������JVM������constructed ���õ�������Dataset�Ͽ���ʹ�ø���transformation���ӣ�map��flatMap��filter �ȣ���Scala ��Java ��֧�ֽӿ���һ�µģ���Ŀǰ����֧��Python������Python�����������Զ�̬�������ƣ����磬�����ʹ���ֶ������������ݣ�row.columnName������Python������֧����δ���İ汾�����ӽ�����
��������������DataFrame SparkӦ�ÿ�����SparkContext����DataFrame�������������Դ���������е�RDD��existing RDD ��������Hive����������������Դ��data sources .��������һ����JSON�ļ�����������DataFrame��С���ӣ�
val sc: SparkContext
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
val df = sqlContext.read.json("examples/src/main/resources/people.json" )
df.show()
df.printSchema()
df.select("name" ).show()
df.select(df("name" ), df("age" ) + 1 ).show()
df.filter(df("age" ) > 21 ).show()
df.groupBy("age" ).count().show()
SQLContext.sql����ִ��һ��SQL��ѯ��������DataFrame�����
val sqlContext = ...
val df = sqlContext.sql("SELECT * FROM table" )
����spark SQL��RDD������ Spark SQL�����ַ�����RDDתΪDataFrame���ֱ�Ϊ������� ����̷�ʽ ��
1. ���÷����Ƶ�schema��#### Spark SQL��Scala�ӿ�֧���Զ�������case class�����RDDתΪDataFrame����Ӧ��case class�����˱���schema��case class�IJ�����ͨ�����䣬ӳ��Ϊ�����ֶ�����case class������Ƕ��һЩ�������ͣ���Seq��Array��RDD��ʽת����DataFrame���Խ�һ��ע��ɱ��������Ϳ��ԶԱ�������ʹ�� SQL����ѯ�ˡ�
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
import sqlContext.implicits._
case class Person(name: String, age: Int)
val people = sc.textFile("examples/src/main/resources/people.txt" ).map (_.split("," )).map (p => Person(p(0 ), p(1 ).trim.toInt)).toDF()
people.registerTempTable("people" )
val teenagers = sqlContext.sql("SELECT name, age FROM people WHERE age >= 13 AND age <= 19" )
teenagers.map (t => "Name: " + t(0 )).collect().foreach(println)
teenagers.map (t => "Name: " + t.getAs[String]("name" )).collect().foreach(println)
teenagers.map (_.getValuesMap[Any](List("name" , "age" ))).collect().foreach(println)
2. ��̷�ʽ����Schema��#### �����������ͨ��case class����schema�����磬��¼���ֶνṹ�DZ�����һ���ַ��������������ı����ݼ��У���Ҫ�Ƚ������ֻ����ֶζԲ�ͬ�û�������ͬ������ô�������Ҫ�������������裬�Ա�̷�ʽ�Ĵ���һ��DataFrame��
�����е�RDD����һ������Row�����RDD����StructType����һ��schema���Ͳ���1�д�����RDD�Ľṹ��ƥ�䣬�ѵõ���schemaӦ���ڰ���Row�����RDD���������������ʵ����һ����SQLContext.createDataFrame
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
val people = sc.textFile("examples/src/main/resources/people.txt" )
val schemaString = "name age"
import org.apache.spark.sql.Row;
import org.apache.spark.sql.types.{StructType,StructField,StringType};
val schema =
StructType(
schemaString.split(" " ).map(fieldName =>true )))
val rowRDD = people.map(_.split("," )).map(p =>0 ), p(1 ).trim))
val peopleDataFrame = sqlContext.createDataFrame(rowRDD, schema)
peopleDataFrame.registerTempTable("people" )
val results = sqlContext.sql("SELECT name FROM people" )
results.map(t =>"Name: " + t(0 )).collect().foreach(println)
�ġ�spark SQL����������Դ����������� Spark SQL֧�ֻ���DataFrame����һϵ�в�ͬ������Դ��DataFrame�ȿ��Ե���һ����ͨRDD��������Ҳ���Խ���ע���һ����ʱ������ѯ���� DataFrameע��Ϊtable֮����Ϳ��Ի������tableִ��SQL����ˡ����ڽ��������غͱ������ݵ�һЩͨ�÷����������˲�ͬ�� Spark����Դ��Ȼ���������һ���ڽ�����Դ����ѡ�Ĭ������ ����Դ���������ݣ�Ĭ����Parquet����������spark.sql.sources.default ���ã���
val df = sqlContext.read.load("examples/src/main/resources/users.parquet" )
df.select("name" , "favorite_color" ).write.save("namesAndFavColors.parquet" )
��Ҳ�����ֶ�ָ������Դ ��������һЩ�����ѡ�����������Դ������ȫ��ָ�����磬org.apache.spark.sql.parquet������ �����ڽ�֧�ֵ�����Դ������ʹ�ü�д����json, parquet, jdbc����������������Դ������DataFrame�����������������ת�������������ݸ�ʽ��
val df = sqlContext.read.format("json" ).load("examples/src/main/resources/people.json" )
df.select("name" , "age" ).write.format("parquet" ).save("namesAndAges.parquet" )
Spark SQL��֧��ֱ�Ӷ��ļ�ʹ��SQL��ѯ������Ҫ��read�������ļ����ؽ�����
val df = sqlContext.sql("SELECT * FROM parquet.`examples/src/main/resources/users.parquet`" )
1. ����JSON���ݼ�#### Spark SQL�ڼ���JSON���ݵ�ʱ�����Զ��Ƶ���schema������DataFrame����SQLContext.read.json��ȡһ������String��RDD����JSON�ļ�������ʵ����һת����
ע�⣬ͨ����˵��json�ļ�ֻ�ǰ���һЩjson���ݵ��ļ�����������������Ҫ��JSON��ʽ�ļ���JSON��ʽ�ļ�����ÿһ����һ�������������ĵ�JSON������ˣ�һ������Ķ���json�ļ����������ʧ�ܡ�
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
val path = "examples/src/main/resources/people.json"
val people = sqlContext.read.json(path)
people.printSchema()
people.registerTempTable("people" )
val teenagers = sqlContext.sql("SELECT name FROM people WHERE age >= 13 AND age <= 19" )
val anotherPeopleRDD = sc.parallelize(
"" "{" name":" Yin"," address":{" city":" Columbus"," state":" Ohio"}}" "" :: Nil)
val anotherPeople = sqlContext.read.json(anotherPeopleRDD)
2. ����Hive�� Spark SQL֧�ִ�Apache Hive �� д���ݡ�Ȼ����Hive������̫�࣬����û�а�Hive������Ĭ�ϵ�Spark�������Ҫ֧��Hive����Ҫ�ڱ���spark��ʱ������-Phive�� -Phive-thriftserver��־��������������ʱ���HiveҲ����������ע�⣬hive��jar��Ҳ������������е�worker�� ���ϣ�����Hive����ʱ����õ����磺ʹ��hive�����л��ͷ����л�SerDesʱ����
val sqlContext = new org.apache.spark.sql.hive.HiveContext(sc)
sqlContext.sql("CREATE TABLE IF NOT EXISTS src (key INT, value STRING)" )
sqlContext.sql("LOAD DATA LOCAL INPATH 'examples/src/main/resources/kv1.txt' INTO TABLE src" )
sqlContext.sql("FROM src SELECT key, value" ).collect().foreach (println)
3. ��JDBC�����������ݿ�#### Spark SQLҲ������JDBC�����������ݿ⡣��һ����Ӧ��������ʹ��JdbcRDD����Ϊ������һ��DataFrame����DataFrame��Spark SQL�в��������Ҹ�����������������Դ�����ݽ��н���������JDBC����Դ��java ��python ��������Ҳ�ܼ�����Ҫ�û��ṩ����� ClassTag����ע�⣬����Spark SQL JDBC server��ͬ��Spark SQL JDBC server��������Ӧ��ִ��Spark SQL��ѯ��
val jdbcDF = sqlContext.read.format("jdbc" ).options(
Map ("url" -> "jdbc:postgresql:dbserver" ,
"dbtable" -> "schema.tablename" )).load()
ע�⣺
JDBC driver class����������client session����executor�ϣ���java ��ԭ��classloader�ɼ���������ΪJava��DriverManager�ڴ�һ������֮ ǰ��������ȫ��飬���������ж�ԭ��classloader���ɼ���driver�����һ�ַ���������������worker�ڵ����� compute_classpath.sh���������������driver jar���� һЩ���ݿ⣬��H2��������е�����ת��д��������Щ���ݿ⣬��Spark SQL�б���Ҳʹ�ô�д�� �塢 spark SQLʾ�� 1����Ҫ�������ű������ĸ��ı��ļ����ŷָ�
2��Ϊ�����ű�������schema����ע��ɱ�
3��ʱ�䴦����С���ָĶ�
�������ű�
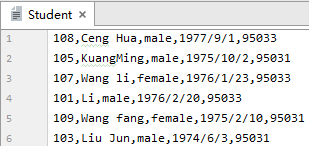
����һ��Student (ѧ����)
�ֶ���
��������
�ɷ�Ϊ��
�� ��
Sno
Varchar2(3)
��
ѧ�ţ�������
Sname
Varchar2(8)
��
ѧ������
Ssex
Varchar2(2)
��
ѧ���Ա�
Sbirthday
Date
��
ѧ����������
SClass
Varchar2(5)
��
ѧ�����ڰ༶
��������Course���γ̱���
������
��������
�ɷ�Ϊ��
�� ��
Cno
Varchar2(5)
��
�γ̺ţ�������
Cname
Varchar(10)
��
�����
Tno
Varchar2(3)
��
�̹���ţ������
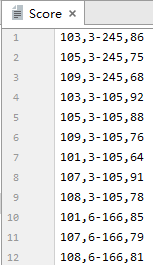
��������Score(�ɼ���)
������
��������
�ɷ�Ϊ��
�� ��
Sno
Varchar2(3)
��
ѧ�ţ������
Cno
Varchar2(5)
��
�γ̺ţ������
Degree
Number(4,1)
��
�ɼ�
�����ģ�Teacher(��ʦ��)
������
��������
�ɷ�Ϊ��
�� ��
Tno
Varchar2(3)
��
�̹���ţ�������
Tname
Varchar2(4)
��
�̹�����
Tsex
Varchar2(2)
��
�̹��Ա�
Tbirthday
Date
��
�̹���������
Prof
Varchar2(6)
��
ְ��
Depart
Varchar(10)
��
�̹����ڲ���
���ű��е�����
���Ӵ��룬ճ�����ã�ע��ע�͵�����Ҫ�ĵط�����
package com.cdpsql1 import org.apache.spark.sql.{Row,SparkSession} import org.apache.spark.sql.types._ import scala.collection.mutable import java.text.SimpleDateFormat objectSparkSqlExample1{ defmain(args:Array[String]):Unit={ valspark=SparkSession .builder() .master("local" ) .appName("test" ) .config("spark.sql.shuffle.partitions" , "5" ) .getOrCreate() valStudentSchema:StructType=StructType(mutable.ArraySeq( StructField("Sno" ,StringType,nullable= false ), StructField("Sname" ,StringType,nullable= false ), StructField("Ssex" ,StringType,nullable= false ), StructField("Sbirthday" ,StringType,nullable= true ), StructField("SClass" ,StringType,nullable= true ) )) valCourseSchema:StructType=StructType(mutable.ArraySeq( StructField("Cno" ,StringType,nullable= false ), StructField("Cname" ,StringType,nullable= false ), StructField("Tno" ,StringType,nullable= false ) )) valScoreSchema:StructType=StructType(mutable.ArraySeq( StructField("Sno" ,StringType,nullable= false ), StructField("Cno" ,StringType,nullable= false ), StructField("Degree" ,IntegerType,nullable= true ) )) valTeacherSchema:StructType=StructType(mutable.ArraySeq( StructField("Tno" ,StringType,nullable= false ), StructField("Tname" ,StringType,nullable= false ), StructField("Tsex" ,StringType,nullable= false ), StructField("Tbirthday" ,StringType,nullable= true ), StructField("Prof" ,StringType,nullable= true ), StructField("Depart" ,StringType,nullable= false ) )) defgetDate(time:String)={ valnow:Long=System.currentTimeMillis() vardf:SimpleDateFormat=new SimpleDateFormat(time) df.format(now) } valStudentData=spark.sparkContext.textFile("input/sqltable/Student" ).map{ lines=> valline=lines.split("," ) Row(line(0 ),line( 1 ),line( 2 ),line( 3 ),line( 4 )) } valCourseData=spark.sparkContext.textFile("input/sqltable/Course" ).map{ lines=> valline=lines.split("," ) Row(line(0 ),line( 1 ),line( 2 )) } valScoreData=spark.sparkContext.textFile("input/sqltable/Score" ).map{ lines=> valline=lines.split("," ) Row(line(0 ),line( 1 ),line( 2 ).toInt) } valTeacherData=spark.sparkContext.textFile("input/sqltable/Teacher" ).map{ lines=> valline=lines.split("," ) Row(line(0 ),line( 1 ),line( 2 ),line( 3 ),line( 4 ),line( 5 )) } valStudentTable=spark.createDataFrame(StudentData,StudentSchema) StudentTable.createOrReplaceTempView("Student" ) valCourseTable=spark.createDataFrame(CourseData,CourseSchema) CourseTable.createOrReplaceTempView("Course" ) valScoreTable=spark.createDataFrame(ScoreData,ScoreSchema) ScoreTable.createOrReplaceTempView("Score" ) valTeacherTable=spark.createDataFrame(TeacherData,TeacherSchema) TeacherTable.createOrReplaceTempView("Teacher" ) spark.sql("SELECTsname,ssex,sclassFROMStudent" ).show() spark.sql("SELECTDISTINCTdepartFROMTeacher" ).show() spark.sql("SELECT*FROMStudent" ).show() spark.sql("SELECT*FROMScoreWHEREdegree>=60anddegree<=80" ).show() spark.sql("SELECT*FROMScoreWHEREdegree='85'ORdegree='86'ORdegree='88'" ).show() spark.sql("SELECT*FROMStudentWHEREsclass='95031'ORssex='female'" ).show() spark.sql("SELECT*FROMStudentORDERBYsclassDESC" ).show() spark.sql("SELECT*FROMStudentORDERBYsclass" ).show() spark.sql("SELECT*FROMScoretORDERBYt.snoASC,t.degreeDESC" ).show() spark.sql("SELECTt.sclasstotalnumFROMStudenttWHEREsclass='95031'" ).show() spark.sql("SELECTt.sclassAStotalnumFROMStudenttWHEREsclass='95031'" ).show() spark.sql("SELECT*FROM(SELECT*FROMScoreORDERBYdegreeDESCLIMIT1)" ).show() spark.sql("SELECTt.sno,t.cnoFROMScoretORDERBYdegreeDESC" ).show() spark.sql("SELECT*FROMScoreWHEREdegreeIN(SELECTMAX(degree)FROMScoret)" ).show() spark.sql("SELECTAVG(degree)averageFROMScoretWHEREcno='3-245'" ).show() spark.sql("SELECTAVG(degree)averageFROMScoreWHEREcno='3-105'" ).show() spark.sql("SELECTAVG(degree)averageFROMScoreWHEREcno='6-166'" ).show() spark.sql("SELECTcno,AVG(degree)FROMScoretGROUPBYcno" ).show() spark.sql("SELECTcno,AVG(degree)FROMScoreWHEREcnoLIKE'3%'GROUPBYcnoHAVINGCOUNT(1)>=5" ).show() spark.sql("SELECTsnoFROMScoreWHEREdegreeBETWEEN70AND90" ).show() spark.sql("SELECTs.sname,t.cno,t.degreeFROMScoret,StudentsWHEREt.sno=s.sno" ).show() spark.sql("SELECTs.sname,t.cno,t.degreeFROMScoretJOINStudentsONt.sno=s.sno" ).show() spark.sql("SELECTs.sname,t.cno,t.degreeFROMScoretJOINStudentsONt.sno=s.sno" ).show() spark.sql("SELECTs.sname,t.degree,c.cnameFROMScoret,Students,CoursecWHEREt.sno=s.snoANDt.cno=c.cno" ).show() spark.sql("SELECTs.sname,t.degree,c.cnameFROMScoret" + "JOINStudentsont.sno=s.sno" + "JOINCourseconc.cno=t.cno" ).show() spark.sql("SELECTAVG(degree)averageFROMScoreWHEREsnoIN(SELECTsnoFROMStudentWHEREsclass='95033')" ).show() spark.sql("SELECT*FROMScoreWHEREcno='3-105'ANDdegree>(SELECTdegreeFROMscoreWHEREsno='109'ANDcno='3-105')" ).show() spark.sql("SELECT*FROMScoreWHEREsnoIN" + "(SELECTsnoFROMScoretGROUPBYt.snoHAVINGCOUNT(1)>1)ANDdegree!=(SELECTMAX(degree)FROMScore)" ).show() spark.sql("SELECT*FROMScoreWHEREdegree!=(SELECTMAX(degree)FROMScore)" ).show() spark.sql("SELECT*FROMScoretWHEREt.degree>(SELECTdegreeFROMScoreWHEREsno='109'ANDcno='3-105')" ).show() spark.sql("SELECTsno,sname,sbirthday" + "FROMStudent" + "WHEREsubstring(sbirthday,0,4)=(" + "SELECTsubstring(t.sbirthday,0,4)" + "FROMStudentt" + "WHEREsno='108')" ).show() spark.sql("SELECTt.tno,c.cno,c.cname,s.degreeFROMTeachert" + "JOINCoursecONt.tno=c.tno" + "JOINScoresONc.cno=s.cnoWHEREt.tname='Zhangxu'" ).show() spark.sql("SELECTtnameFROMTeachere" + "JOINCoursecONe.tno=c.tno" + "JOIN(SELECTcnoFROMScoreGROUPBYcnoHAVINGCOUNT(cno)>5)tONc.cno=t.cno" ).show() spark.sql("SELECT*FROMStudentWHEREsclassIN('95031','95033')" ).show() spark.sql("SELECT*FROMStudentWHEREsclassLIKE'9503%'" ).show() spark.sql("SELECTcnoFROMScoreWHEREdegree>85GROUPBYcno" ).show() spark.sql("SELECTt.sno,t.cno,t.degreeFROMScoret" + "JOINCoursecONt.cno=c.cno" + "JOINTeachereONc.tno=e.tnoWHEREe.depart='departmentofcomputer'" ).show() spark.sql("SELECTtname,prof" + "FROMTeacher" + "WHEREprofNOTIN(SELECTa.prof" + "FROM(SELECTprof" + "FROMTeacher" + "WHEREdepart='departmentofcomputer'" + ")a" + "JOIN(SELECTprof" + "FROMTeacher" + "WHEREdepart='departmentofelectronicengineering'" + ")bONa.prof=b.prof)" ).show() spark.sql("SELECTtname,prof" + "FROMTeacher" + "WHEREdepart='departmentofelectronicengineering'" + "ANDprofNOTIN(SELECTprof" + "FROMTeacher" + "WHEREdepart='departmentofcomputer')" + "ORdepart='departmentofcomputer'" + "ANDprofNOTIN(SELECTprof" + "FROMTeacher" + "WHEREdepart='departmentofelectronicengineering')" ).show() spark.sql("SELECTt.sno,t.cno,degree" + "FROMSCOREt" + "WHEREdegree>(" + "SELECTMIN(degree)" + "FROMscore" + "WHEREcno='3-245'" + ")" + "ANDt.cno='3-105'" + "ORDERBYdegreeDESC" ).show() spark.sql("SELECTt.sno,t.cno,t.degreeFROMScoretWHEREt.degree>(SELECTMAX(degree)FROMScoreWHEREcno='3-245')ANDt.cno='3-105'" ).show() spark.sql("SELECTsname,ssex,sbirthdayFROMStudent" + "UNIONSELECTtname,tsex,tbirthdayFROMTeacher" ).show() spark.sql("SELECTsname,ssex,sbirthday" + "FROMStudent" + "WHEREssex='female'" + "UNION" + "SELECTtname,tsex,tbirthday" + "FROMTeacher" + "WHEREtsex='female'" ).show() spark.sql("SELECTs.*" + "FROMscores" + "WHEREs.degree<(" + "SELECTAVG(degree)" + "FROMscorec" + "WHEREs.cno=c.cno)" ).show() spark.sql("SELECTtname,depart" + "FROMteachert" + "WHEREt.tnoIN(" + "SELECTtno" + "FROMcoursec" + "WHEREc.cnoIN(" + "SELECTcno" + "FROMscore))" ).show() spark.sql("SELECTtname,depart" + "FROMteachert" + "WHEREt.tnoNOTIN(" + "SELECTtno" + "FROMcoursec" + "WHEREc.cnoIN(" + "SELECTcno" + "FROMscore))" ).show() spark.sql("SELECTSClass" + "FROMStudentt" + "WHERESsex='male'" + "GROUPBYSClass" + "HAVINGCOUNT(Ssex)>=2" ).show() spark.sql("SELECT*FROMStudenttWHERESnameNOTLIKE('Wang%')" ).show() spark.sql("SELECTSname,(" +getDate( "yyyy" )+ "-substring(sbirthday,0,4))ASageFROMSTUDENTt" ).show() spark.sql("SELECTSname,(CAST(" +getDate( "yyyy" )+ "ASINT)-CAST(substring(sbirthday,0,4)ASINT))ASage" + "FROMStudentt" ).show() spark.sql("SELECTMAX(t.sbirthday)ASmaximumFROMStudentt" ).show() spark.sql("SELECTMIN(t.sbirthday)ASminimumFROMStudentt" ).show() spark.sql("SELECT*" + "FROMStudent" + "ORDERBYSClassDESC,CAST(" +getDate( "yyyy" )+ "ASINT)-CAST(substring(Sbirthday,0,4)ASINT)DESC" ).show() spark.sql("SELECTTSex,CName" + "FROMTeachert" + "JOINcoursecONt.tno=c.tno" + "WHERETSex='male'" ).show() spark.sql("SELECT*" + "FROMScore" + "WHEREdegree=(" + "SELECTMAX(degree)" + "FROMSCOREt)" ).show() spark.sql("SELECTsname" + "FROMSTUDENTt" + "WHEREssexIN(" + "SELECTssex" + "FROMstudent" + "WHEREsname='LiuJun')" ).show() spark.sql("SELECTsname" + "FROMStudentt" + "WHEREssexIN(" + "SELECTssex" + "FROMstudent" + "WHEREsname='LiuJun')" + "ANDsclassIN(SELECTsclass" + "FROMstudent" + "WHEREsname='LiuJun')" ).show() spark.sql("SELECTt.sno,t.cno,t.degree" + "FROMScoret" + "JOINCoursecONt.cno=c.cno" + "JOINStudentsONs.sno=t.sno" + "WHEREs.SSex='male'" + "ANDc.CName='Introductiontocomputer'" ).show() } }