Apache Spark���
Apache Spark��һ����Դ��Ⱥ�����ܡ�ʹ��Spark��Ҫ���伯Ⱥ�����ͷֲ�ʽ�洢ϵͳ��Spark ֧�ֶ�����Hadoop YARN����Apache Mesos ��Ⱥ������Spark���Ժ�Hadoop Distrubuted File System (HDFS), MapR File System (MapR-FS), Cassandra, OpenStack Swift, Amazon S3 �ȷֲ�ʽ�洢ϵͳ���ʹ�á�Spark����������Scala������ԡ�
Apache Spark ��Ⱥ�
1. ���ذ�װScala
Scala2.11.4 ���ص�ַ��http://www.scala-lang.org/download/2.11.4.html
��ѹ��[spark@Node1 apache_spark]$ tar zxvf scala-2.11.4.tgz
���ã��༭ ~/.bash_profile�ļ� ����SCALA_HOME������������
export SCALA_HOME=/home/spark/apache_spark/scala-2.11.4
PATH=$PATH:$SCALA_HOME/bin
export PATH
��֤Scala�����Ƿ���������source ~/.bash_profile��
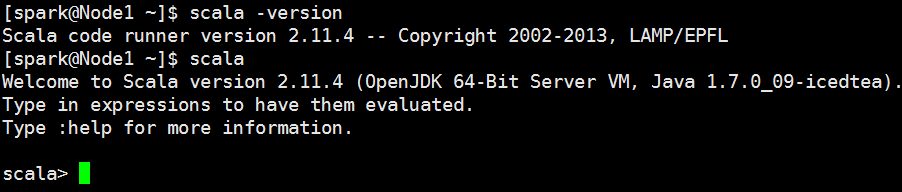
2. ��װJDK
���ص�ַ��http://www.oracle.com/technetwork/cn/java/javase/downloads/java-se-jdk-7-download-432154-zhs.html
��ѹ��tar jdk-7-linux-x64.tar.gz
3. ��װSpark
��Ⱥ��Ϣ˵��
Node1 192.168.100.101 (Master)
Node2 192.168.100.102 (Slaver)
Node3 192.168.100.103 (Slaver)
Node4 192.168.100.104 (Slaver)
����Spark
wget http://d3kbcqa49mib13.cloudfront.net/spark-1.2.0-bin-hadoop2.4.tgz
��ѹ
[spark@Node1 apache_spark]$ tar zxvf spark-1.2.0-bin-hadoop2.4.tgz
���û�������
export SPARK_HOME=/home/spark/apache_spark/spark-1.2.0-bin-hadoop2.4
PATH=$PATH:$SPARK_HOME/bin
�������ļ���
cd /home/spark/apache_spark/spark-1.2.0-bin-hadoop2.4/conf
mv spark-env.sh.template spark-env.sh
vim spark-env.sh
export SCALA_HOME=/home/spark/apache_spark/scala-2.11.4
export JAVA_HOME=/home/spark/apache_spark/jdk1.7.0_51
export SPARK_MASTER_IP=192.168.100.101
export SPARK_WORKER_MEMORY=512M
export master=spark:
mv slaves.template slaves
vim slaves
Node2
Node3
Node4
�ַ��ļ����ӽڵ㣨�����ýڵ�֮���ssh���ţ�
scp ~/.bash_profile Node2:~/.bash_profile
scp ~/.bash_profile Node3:~/.bash_profile
scp ~/.bash_profile Node4:~/.bash_profile
scp -r ~/apache_spark node2:~/
scp -r ~/apache_spark node3:~/
scp -r ~/apache_spark node4:~/
������ֹͣspark
����Spark
/home/spark/apache_spark/spark-1.2.0-bin-hadoop2.4/sbin/start-all.sh

ֹͣspark
/home/spark/apache_spark/spark-1.2.0-bin-hadoop2.4/sbin/stop-all.sh

�鿴Spark��Ⱥ��Ϣ
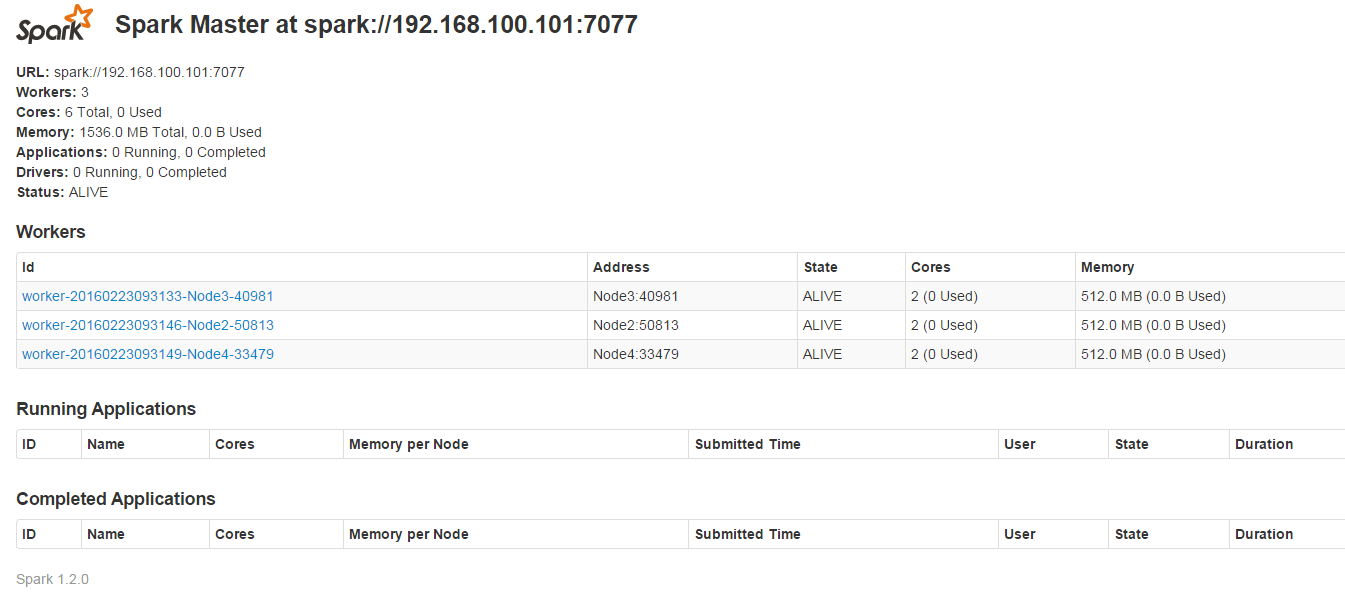
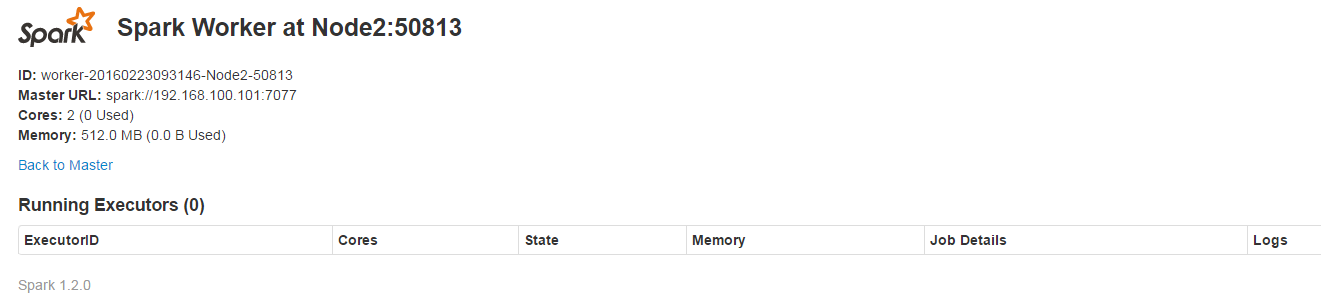
����
����ʱ����
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
ntpdate time.windows.com
hwclock �Csystohc
�ο�
[1] Spark����ѧϰ
[2] spark-1.2.0 ��Ⱥ�����
[3] spark1.3.1��װ�ͼ�Ⱥ�Ĵ