Spark ���������е�ʱ���Ϊ Driver �� Executor ������
SparkContext �������߽�����ʱ������ Spark ����Ҳ��������
[��ͼ�� SparkContext �ڴ������Ķ���������ͼ ]
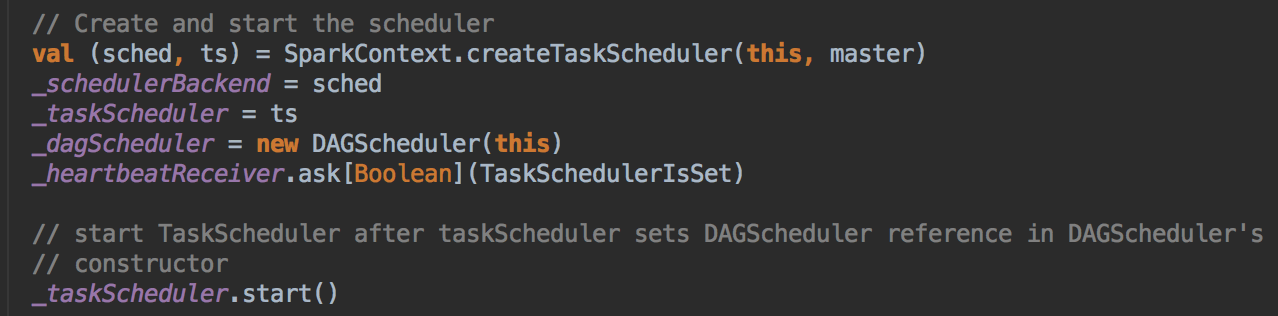
SparkContext ������피�������ģ�DAGScheduler ,TaskScheduler,SchedulerBackend DAGScheduler ������ Job �� Stage �ĸߌ��{������ TaskScheduler ��һ���ӿڣ��ǵ͌��{�������������w�� ClusterManager �IJ�ͬ���в�ͬ�Č��F��Standalone ģʽ�¾��w�Č��F TaskSchedulerImpl; SchedulerBackend ��һ���ӿڣ��������w�� ClusterManager �IJ�ͬ���в�ͬ�Č��F��Standalone ģʽ�¾��w�Č��F��SparkDeploySchedulerBackend �����������\�еĽǶȁ��v��SparkContext �����Ĵ���Č���DAGScheduler ,TaskScheduler,SchedulerBackend,MapOutputTrackerMaster
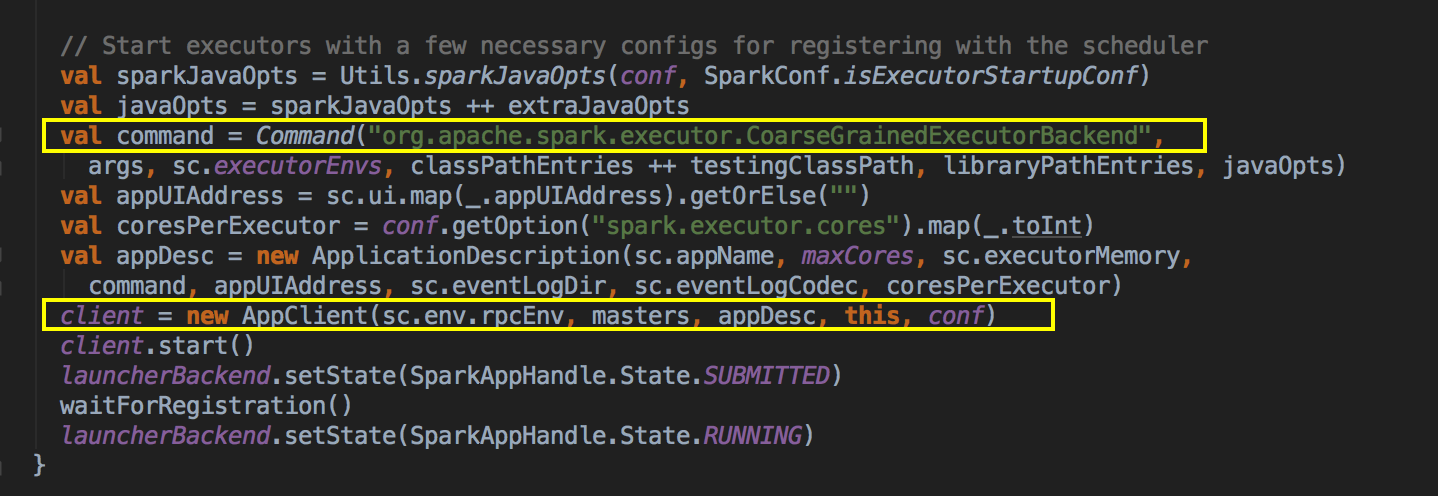
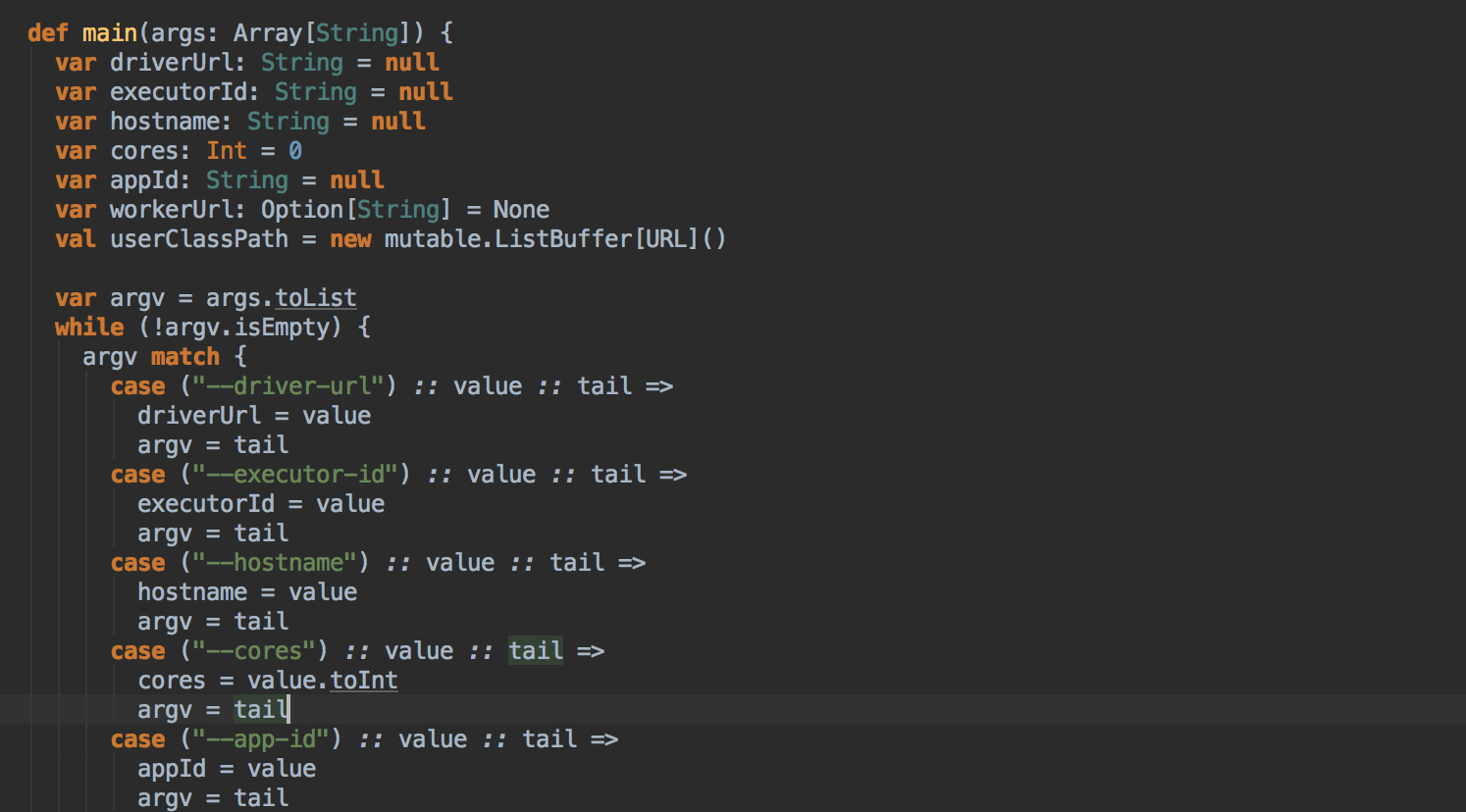
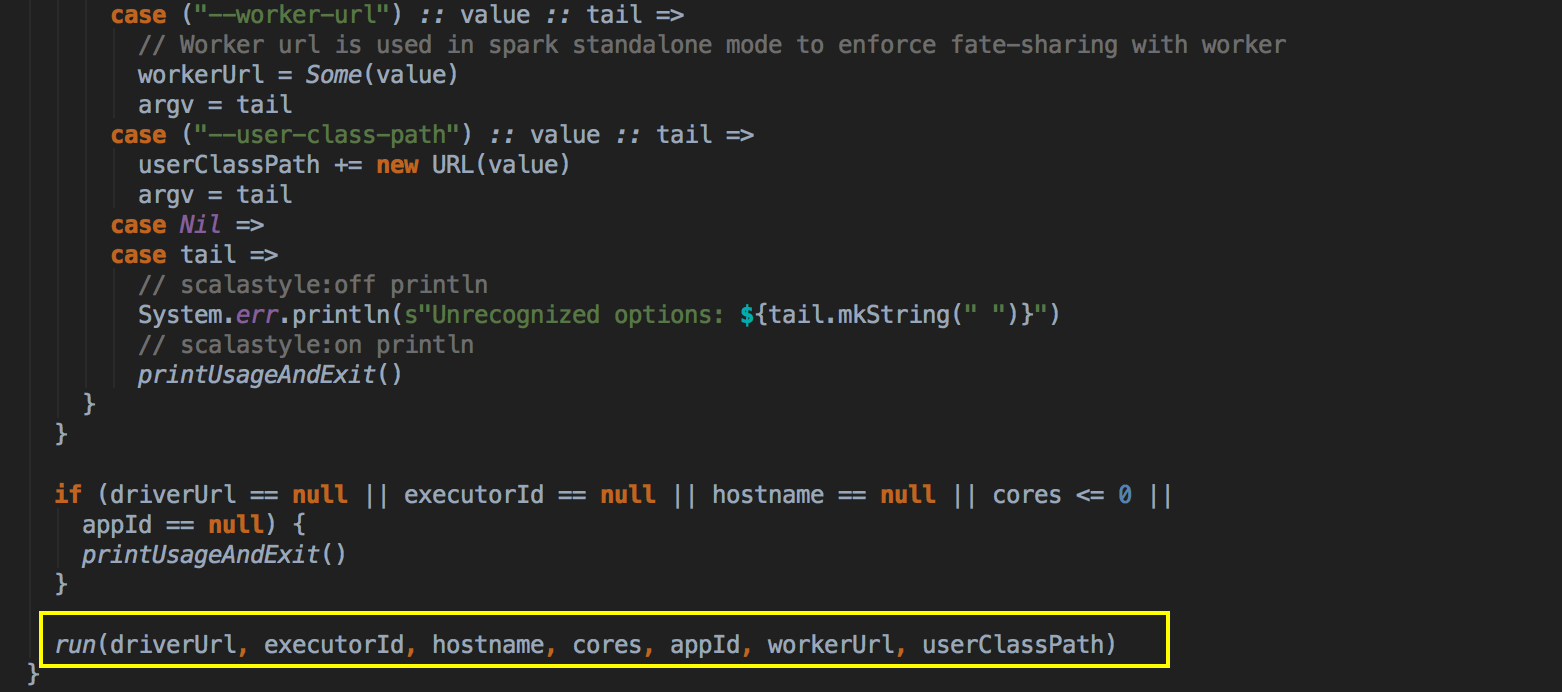
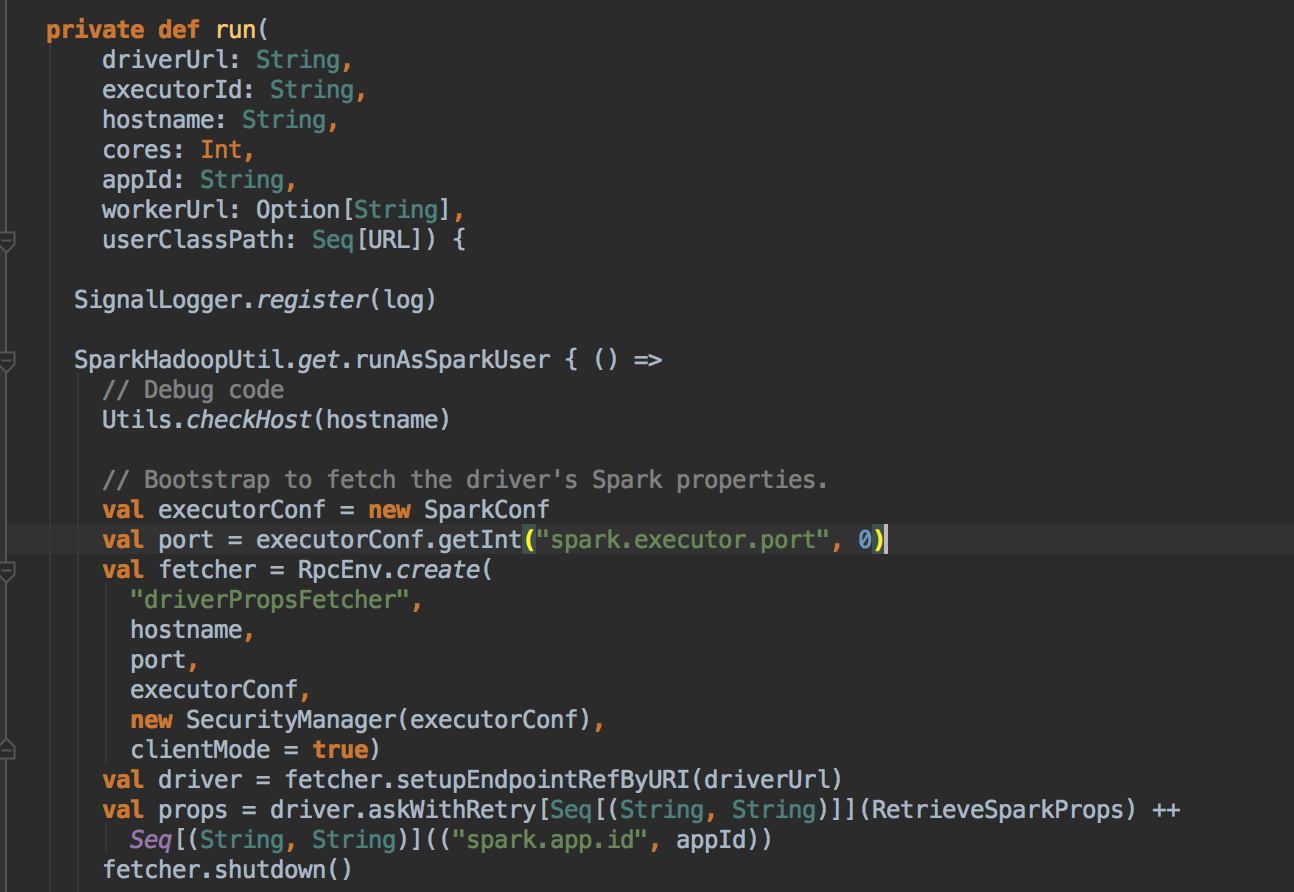
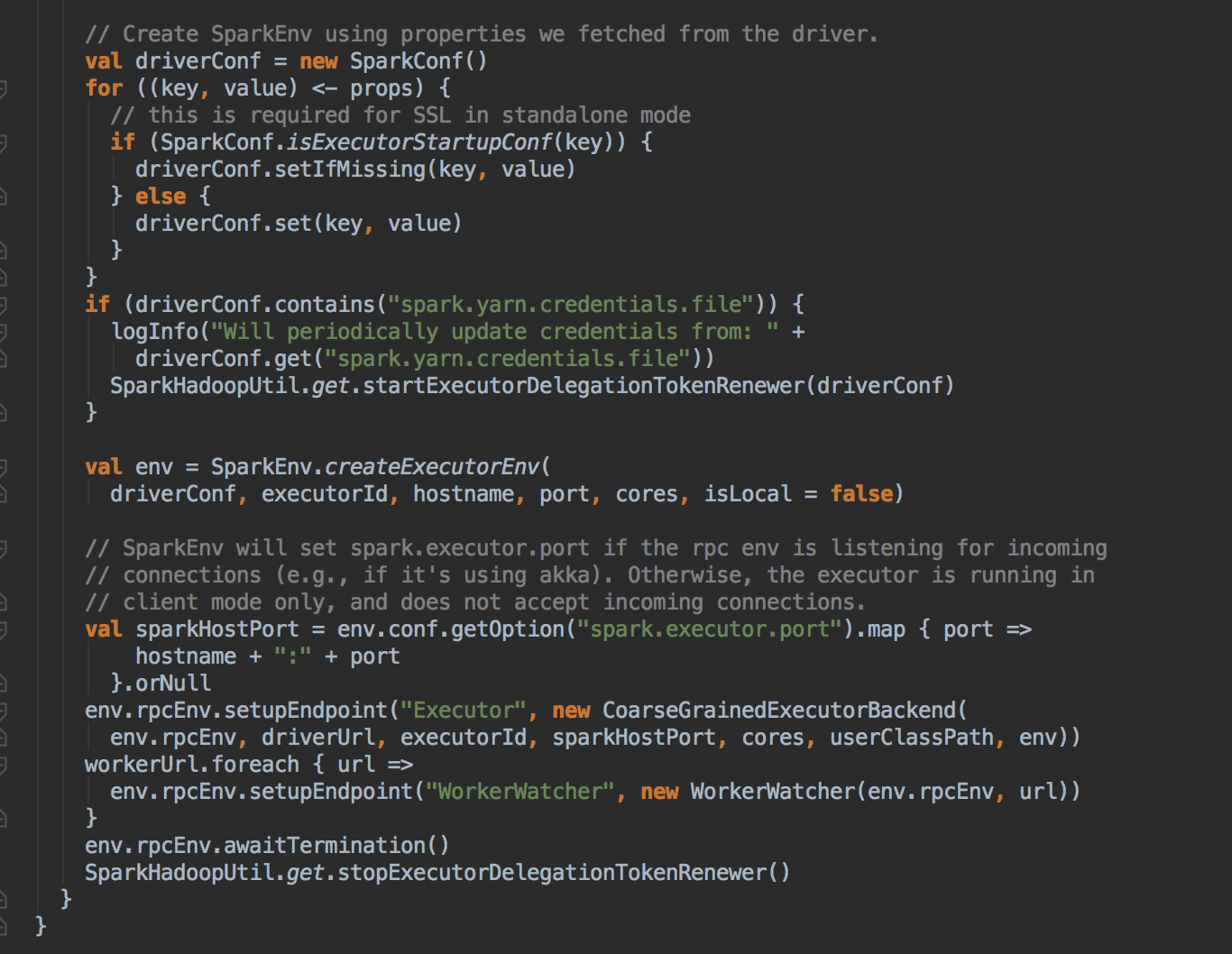
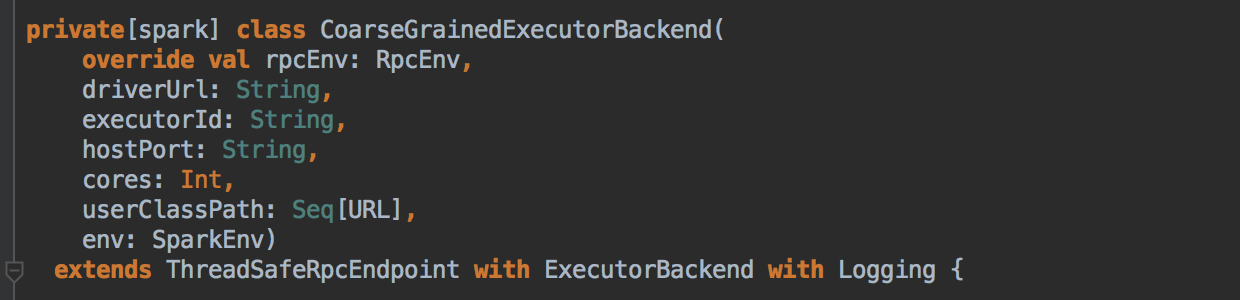
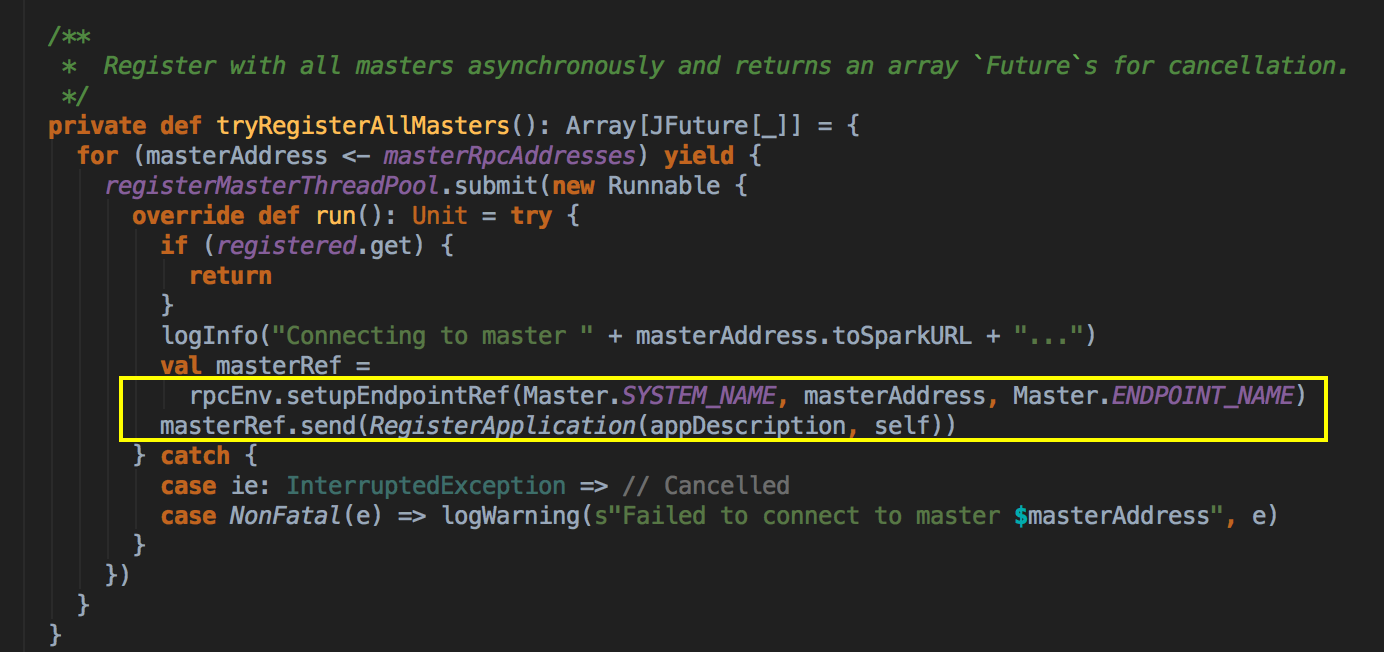
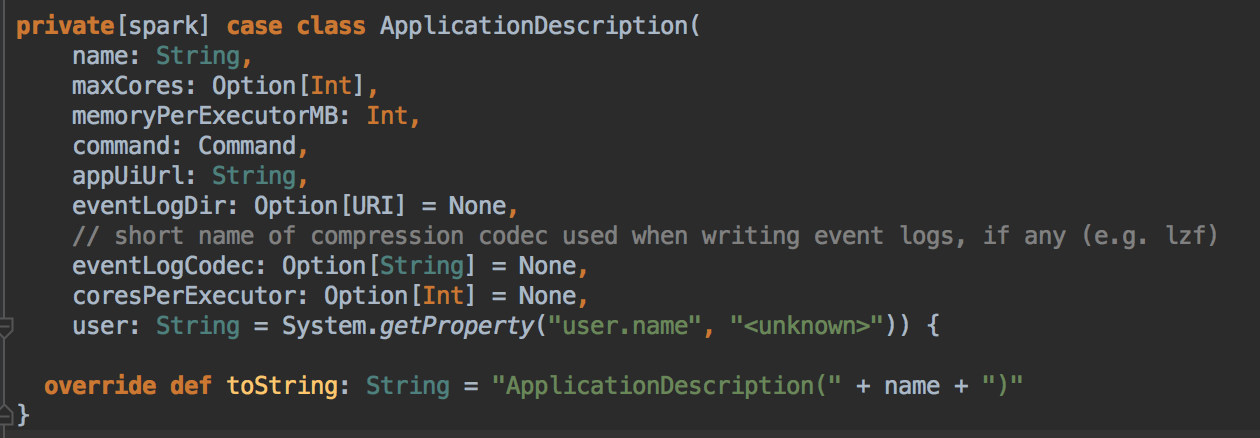
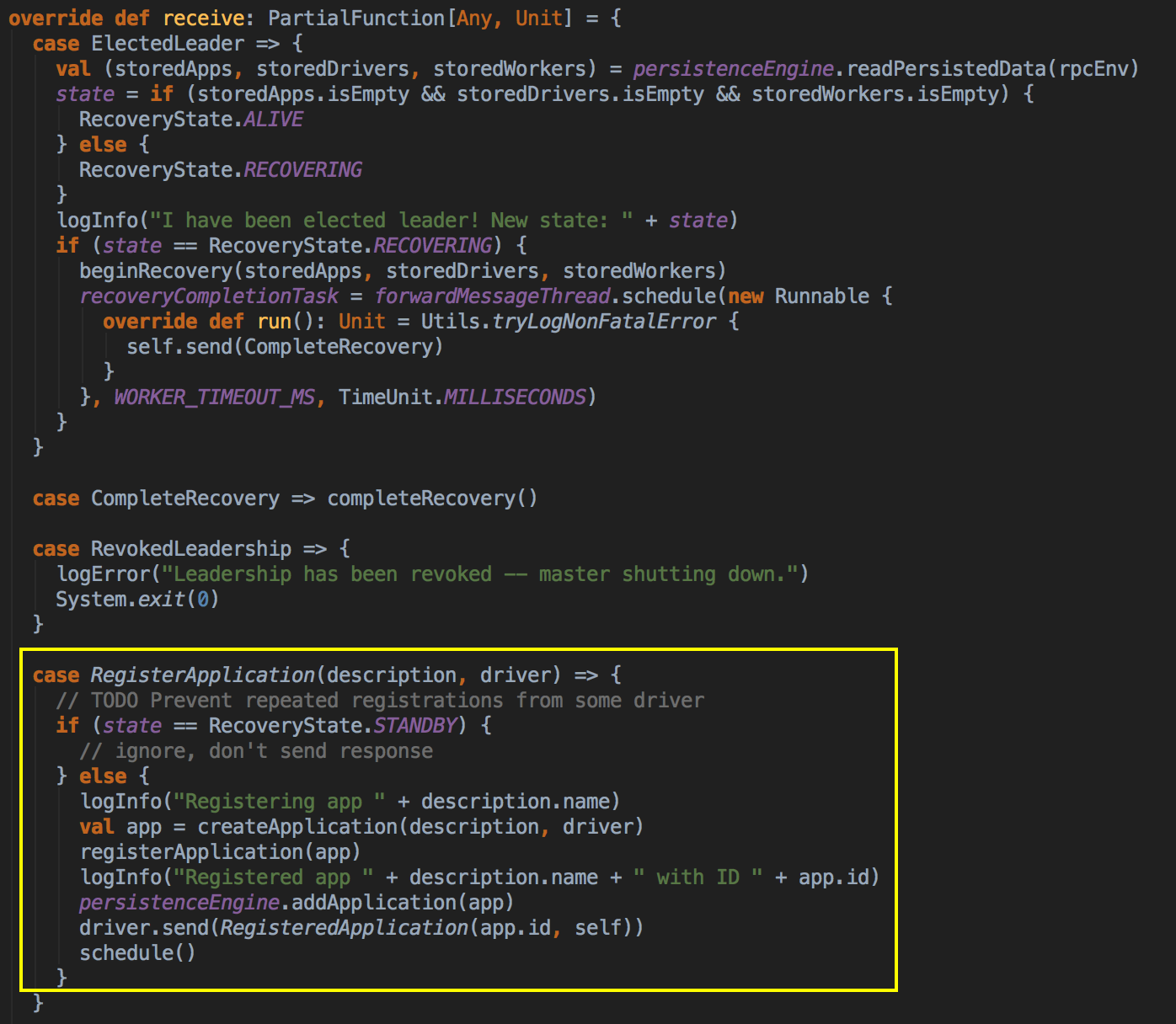
SparkDeploySchedulerBackend ��������Ĺ��ܣ�
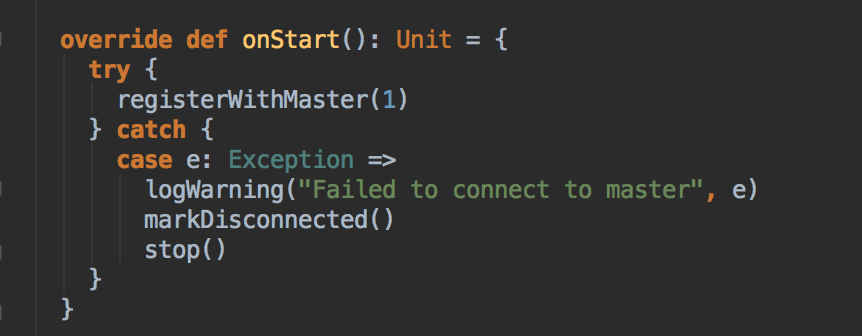
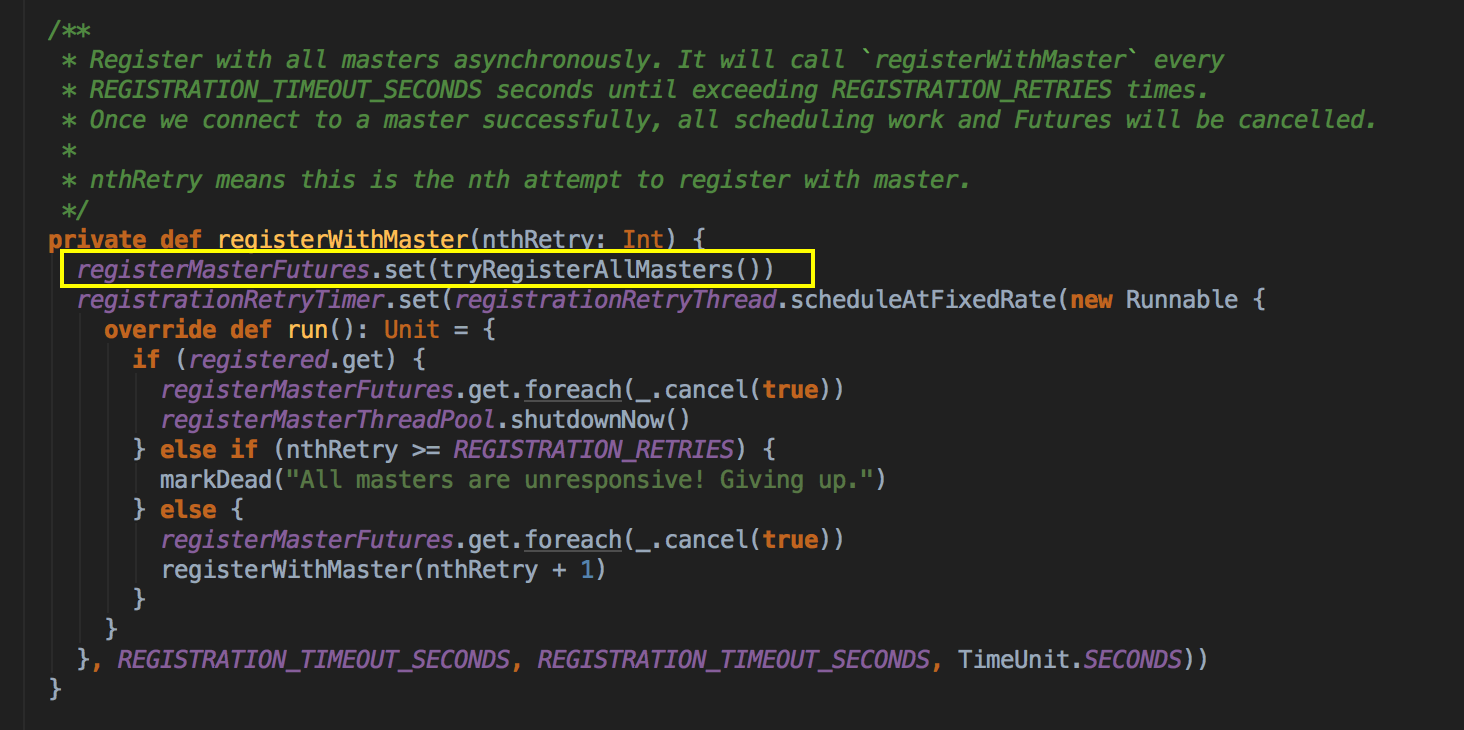
ؓ؟�c Master �B��ע�Ԯ�ǰ���� RegisterWithMaster ���ռ�Ⱥ�О鮔ǰ���ó���������Ӌ���YԴ Executor ��ע�ԁK���� Executors; ؓ؟�l�� Task �����w�� Executor ���� �a���f������SparkDeploySchedulerBackend �DZ�TaskSchedulerImpl �������ģ�
���� SparkContext �ĺ��Ķ���