Spark Ӧ�ó�����Ż��漰��������棬���� spark Ӧ�ó�����š���Դ���š�������š�Ӳ�̵��ŵȡ�������Ҫ���� ��spark Ӧ�ó�����š� �� ����Դ���š���
�����ظ����� RDD�������ܸ���RDD
����ͬһ�����ݣ�ֻӦ�ô���һ�� RDD�����ͬһ�����ݱ������ɶ�� RDD��Spark ��ҵ���ж���ظ����㣬��������ҵ�����ܿ�����
//���������
val rdd1 = sc.textFile("filePath")
rdd1.map(...)
val rdd2 = sc.textFile("filePath ")
rdd2.reduce(...)
//��ȷ������
val rdd1 = sc.textFile("filePath")
rdd1.map(...)
rdd1.reduce(...)
���ظ�ʹ�õ� RDD ���г־û�
��������ʹ�ûᴥ�� shuffle ����������
Spark shuffle�����ǽ����ݰ��� key �����á�shuffle �����У������ڵ��ϵ���ͬ key ���ݶ�����д�뱾�ش����ļ��У�Ȼ�������ڵ���Ҫͨ�����紫����ȡ�������ڵ��ϵĴ����ļ��е���ͬ key����ͬ key ������ȡ��ͬһ���ڵ���оۺϲ�������ʱ�п��ܻ���Ϊij���ڵ��ϴ����� key ���࣬�����ڴ治����ţ�������д�������ļ��С���� shuffle �����У����ܻᷢ�������Ĵ����ļ���д��IO�������Լ����ݵ����紫����������� IO ���������ݴ����� shuffle ���ܽϲ����Ҫԭ��
����ڿ��������У������ܱ���ʹ�� reduceByKey��join��distinct��repartition �Ȼ���� shuffle �����ӣ�������ʹ�� map ��ķ� shuffle ���ӣ�������ʹ�ù㲥���������� shuffle������ѡ�� reduceByKey��aggregateByKey��combineByKey �滻 groupByKey����Ϊ reduceByKey �����ڲ�ʹ����Ԥ�ۺϲ�����
ʹ�ø���������
ʹ�� mapPartition ���� map
ʹ�� foreachPartition �滻 foreach
filter ֮��ʹ�� coalesce ����
ʹ�� repartitionAndSortWithinPartition ���� reparation �� sort �������
��������㲥��ȥ
�����Ӻ�����ʹ�õ��ⲿ����ʱ��Ĭ������£�Spark�Ὣ�ñ������ƶ��������ͨ�����紫�䵽 task �У���ʱÿ�� task ����һ������������������������ϴ���ô�����ı��������������д�������ܿ������Լ��ڸ����ڵ�� executor ��ռ�ù����ڴ浼�µ�Ƶ�� GC �������գ� �Ἣ���Ӱ�����ܡ�ʹ�� Spark �Ĺ㲥���ܣ��Ըñ������й㲥���㲥��ı�����ÿ�� Executor ֻ����һ�ݱ����������� Executor �е� task ִ��ʱ������ Executor �б����������������Ϳ��Դ����ٱ����������������Ӷ��������紫������ܿ����������ٶ� Executor �ڴ��ռ�ÿ��������� GC ��Ƶ�ʡ�
ʹ�� Kryo ���л���ʽ
�����Ӻ�����ʹ�õ��ⲿ����ʱ���ñ����ᱻ���л���������紫�䣬��ʱ��Ҫ�Դ˱����������л���
���Զ��������Ϊ RDD �ķ�������ʱ�������Զ�����Ķ�����������л���������������Ҫ�Զ���������ʵ�� Serializable �ӿڡ�
ʹ�ÿ����л��ij־û�����ʱ��Spark �Ὣ RDD �е�ÿ�� Partition �����л���һ������ֽ����顣
���л����Դ������������ڴ棬Ӳ����ռ�õĿռ䣬�����������ݴ���Ŀ���������ʹ�������У���Ҫ�����ݽ��з����л��������� CPU���ӳ�����ִ�е�ʱ�䣬�Ӷ����� spark �����ܡ����ԣ����л�ʵ���������� ��ʱ�任�ռ䡱 �ķ�ʽ��
Spark Ĭ��ʹ Java ���л��������������л��ͷ����л��� Spark ͬʱ֧��ʹ�� Kryo ���л��⣬Kyro ���л����е����ܱ� Java ���л�������ܸ���Щ������ Kyro ��֧�����ж�������л���ͬʱ Kryo ��Ҫ�û���ʹ��ǰע����Ҫ���л������ͣ��������㡣
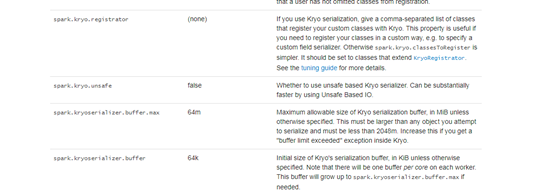
Kryo ������ã�
���� spark ���л�ʹ�ÿ�
//ʹ��Kryo���л���
sparkconf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer");
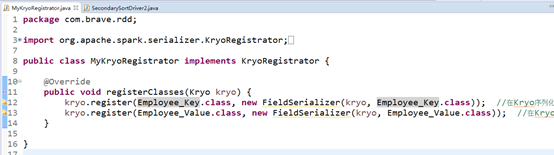
�ڸÿ���ע���û����������
//��Kryo���л�����ע���Զ�����༯��
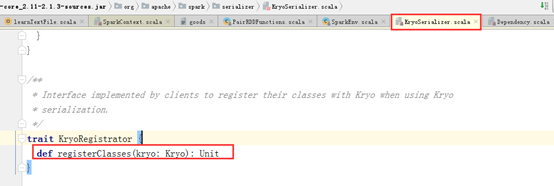
sparkconf.set("spark.kryo.registrator", MyKryoRegistrator.class.getName());
MyKryoRegistrator ��ʵ�� KryoRegistrator �ӿڵ� registerClasses������
���Բ鿴Ĭ�����л���Kyro���л���ռ�ռ�IJ��
��һ��ѹ��
ʹ���Ż������ݽṹ
�Զ������ÿ�� java �����ж���ͷ�����õȶ������Ϣ����˱Ƚ�ռ���ڴ�ռ䡣
�ַ�����ÿ���ַ����ڲ�����һ���ַ������Լ����ȵȶ�����Ϣ��
�������ͣ����������ڲ�ͨ��ʹ���ڲ�������װ����Ԫ�ء�
����� Spark ����ʵ���У��ر��Ƕ������Ӻ����еĴ��룬����ʹ���ַ�������������ʹ��ԭʼ��������ַ�����ʹ����������������ͣ��������Ծ����ܵؼ����ڴ�ռ�ã��Ӷ����� GC Ƶ�ʣ�����ϵ�ܡ�
���������� task ִ�ж��dz��죬���Ǹ��� task ִ�м��������磺�ܹ��� 100 �� task��99 ��task ���� 1������ִ����ɣ�ֻʣ��һ�� task ȴҪ�����ʱ�䡣�����Ϳ���ȷ�Ϸ�����������б �����⣬������б���صĻ����ͻᷢ�� OOM ������ Application ʧ�ܡ�
ʹ������ shuffle �����ӣ��ڽ��� shuffle ʱ�����뽫�����ڵ�����ͬ�� key ��ȡ��ij���ڵ��ϵ�һ�� task �����д��������簴�� key ���оۺϻ� join �Ȳ�������ʱ���ij�� key ��Ӧ���������ر��Ļ����ͻᷢ��������б������� key ��Ӧ 10 �����ݣ����Ǹ��� key ȴ��Ӧ�� 100 �������ݣ���ô�� task ���ܾ�ֻ����䵽 10 �����ݣ�Ȼ���ںܶ�ʱ���ھ�ִ������ˣ�������� task ���ܷ��䵽 100 �������ݣ��������Ҫ���кܾá���ˣ����� Spark ��ҵ�����н�����������ʱ������Ǹ� task �����ġ�
shuffle ������������б���������� shuffle �����ӣ�distinct��groupByKey��reduceByKey��aggregateByKey��join��cogroup��reparation �ȡ���˿����ڴ�����ֱ���ҵ���ص����ӡ�
��Щ���ӻ���� shuffle��shuffle �Ữ�� stage�����ԣ��� WebUI �в鿴����������б�� task �������ĸ� stage�С������� spark standalone ģʽ���� spark on yarn ģʽ��Ӧ�ó��������� spark history server �п�����ϸ��ִ����Ϣ��Ҳ����ͨ�� yarn logs ����鿴��ϸ��������Ϣ��
����� Spark SQL �е� group by��join��䵼�µ�������б����ô�ò�ѯ SQL ��ʹ�õı��� key �ֲ������
����Ƕ� Spark RDD ִ�� shuffle ���ӵ��µ�������б����ô������ spark ��ҵ�м���鿴 key �ֲ��Ĵ��룬���� RDD.countByKey()��Ȼ���ͳ�Ƴ����ĸ��� key ���ֵĴ�����collect/take ���ͻ��˴�ӡ���Ϳ��Կ��� key �ķֲ������
������������ֵ�����б�� key ���������������ҶԼ��㱾��û��̫���Ӱ�죬��ô���ʺϲ��ô˷������������ͱ���ǰ����������ֻ��һ�� key ��Ӧ�� 100w �����ݣ������������ݱ�֮��֮���٣��Ӷ���Ϊ�� key ������������б��
˼·��countByKey ȷ�������������ij�� Key��ʹ�� filter �������ˡ�SparkSQL��ʹ�� where �������ˡ�
�˷���ʵ�ּ�����Ч��Ҳ�ȽϺã�������ȫ����������б���������ó������ࡣ�ڴ����ʵ������£�������б�� key ���Ǻܶ࣬������ֻ������������
��������ʹ�ù��˵ķ����������б���⣬ֻ�����������б�����⡣
˼·��ִ�� RDD shuffle ����ʱ���� shuffle ���Ӵ���һ������������ reduceByKey(100)���ò������������ shuffle ����ִ��ʱ shuffle read task ������������ spark Sql �е� shuffle ����䣬���� group by��join�ȣ���Ҫ����һ���������� spark.sql.shuffle.partititon���ò��������� shuffle.read.task �IJ��жȣ���ֵĬ���� 200��
�˷�����Ȼʵ�ּ����Ǹ÷����α겻�α�������ij�� key ��Ӧ���������� 100w����ô���� task �������Ӷ��٣������Ӧ�� 100w ���ݵ� key �϶����ᱻ���䵽һ�� task ������������˻��ǻᷢ��������б��
�������� RDD ִ�� reduceByKey �Ⱦۺ��� shuffle ���ӻ����� spark sql ��ʹ�� group by �����з���ۺ�ʱ���Ƚ�ʹ�����ַ�����
˼·�������������˼·���ǽ������ξۺ� ����һ���Ǿֲ��ۺϣ��ȸ�ÿ�� key ������һ������������� 10���ڵ����������ʱԭ��һ���� key �ͱ�ɲ�һ���ˡ����� (hello, 1) (hello, 1) (hello, 1) (hello, 1)���ͻ��� (1_hello, 1) (1_hello, 1) (2_hello, 1) (2_hello, 1)��
����ۺ���� shuffle ���ӵ��µ�������б������Ч�Ĵ�����б������ join ��� shuffle ���ӾͲ��ʺ��ˡ�
// ��1���������ǰ��
JavaPairRDD<String, Long> randomPrefixKeyRdd = pairRdd.mapToPair(
new PairFunction<Tuple2<Long,Long>, String, Long>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, Long> call(Tuple2<Long, Long> tuple)
throws Exception {
Random random = new Random();
int prefix = random.nextInt(100);
return new Tuple2<String, Long>(prefix + "_" + tuple._1, tuple._2);
}
});
// ��2�����ֲ��ۺϡ�
JavaPairRDD<String, Long> firstAggRdd = randomPrefixKeyRdd.reduceByKey(
new Function2<Long, Long, Long>() {
private static final long serialVersionUID = 1L;
@Override
public Long call(Long v1, Long v2) throws Exception {
return v1 + v2;
}
});
// ��3����ȥ��key�����ǰ��
JavaPairRDD<Long, Long> removedrandomPrefixKeyRdd = firstAggRdd.mapToPair(
new PairFunction<Tuple2<String,Long>, Long, Long>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<Long, Long> call(Tuple2<String, Long> tuple)
throws Exception {
long originalKey = Long.valueOf(tuple._1.split("_")[1]);
return new Tuple2<Long, Long>(originalKey, tuple._2);
}
});
// ��4��ȫ�־ۺϡ�
JavaPairRDD<Long, Long> secondAggRdd = removedrandomPrefixKeyRdd.reduceByKey(
new Function2<Long, Long, Long>() {
private static final long serialVersionUID = 1L;
@Override
public Long call(Long v1, Long v2) throws Exception {
return v1 + v2;
}
});
�������� RDD ʹ�� join ��������������� spark sql ��ʹ�� join ���ʱ������ join �����е�һ�� RDD ������������Ƚ�С���Ƚ��ʺϴ˷�����
˼·����ʹ��join���ӽ������Ӳ�������ʹ�� Broadcast ������ map ������ʵ�� join ������������ȫ��� shuffle ��IJ��������ױ���������б�ķ����ͳ��֡��C��ʵ��Ҳ�����ù㲥������������
var list1=List(("zhangsan",20),("lisi",22),("wangwu",26))
var list2=List(("zhangsan","spark"),("lisi","kafka"),("zhaoliu","hive"))
var rdd1=sc.parallelize(list1)
var rdd2=sc.parallelize(list2)
//���ַ�ʽ�����������⣬join����shuffle������Ż���
//rdd1.join(rdd2).collect().foreach( t =>println(t._1+" : "+t._2._1+","+t._2._2))
//ʹ�ù㲥������join���е��� ʹ�ó�����join���ߵ�RDD����һ��RDD���������Ƚ�С����ʱ����ʹ�ù㲥�����������С��RDD�㲥��ȥ���Ӷ�����ͨ��join��װ��Ϊmap-side join��
val rdd1Data=rdd1.collectAsMap()
val rdd1BC=sc.broadcast(rdd1Data)
val rdd3=rdd2.mapPartitions(partition => {
val bc=rdd1BC.value
for{
(key,value) <-partition
if(rdd1Data.contains(key))
}yield(key,(bc.get(key).getOrElse(""),value))
})
�� join �������µ�������б��Ч���dz��á���Ϊ���ᷢ�� shuffle��Ҳ�Ͳ��ᷢ��������б���������ֳ���һ���ʺ�һ���� RDD �� һ��С RDD�������
Ϊ�˶����� RDD �е����ݽ��� join��Spark��Ҫ������ RDD �ϵ�������ȡ��ͬһ��������Spark �� join ��Ĭ��ʵ���� shuffle hash join�� ͨ��ʹ�����һ�����ݼ���ͬ��Ĭ�Ϸ������Եڶ������ݼ����з������Ӷ�ȷ��ÿ�������ϵ����ݽ�������ͬ�� key���Ӷ�ʹ�������ݼ�������ͬ hash �ļ�ֵλ��ͬһ����������Ȼ����������ǿ������У����Ǵ��ֲ����ȽϺķ���Դ����Ϊ��Ҫ����һ�� shuffle��
������� RDD ����һ����֪�ķ���������Ա��� shuffle�������������ͬ�ķ������������ʹ�����ڱ��ر��ϲ����������紫�䡣��ˣ������� join ���� RDD ֮ǰ������ Partitionby����������ʹ����ͬ�ķ�������
val partitioner=new HashPartitioner(10)
agesRDD.partitionBy(partitioner)
addressRDD.partitionBy(partitioner)
���ֻ�Ǵ�����Ϊ��������б�ij�����ʹ������ijһ�ַ��������Խ�����⡣�������Ҫ����һ����Ϊ���ӵ�������б��������ô��Ҫ�����ַ����������һ��ʹ�á�
�� Spark ����Դ���ţ�����Ҫ�� Spark ���й����и���ʹ����Դ�ĵط���ͨ�����ڸ��ֲ������Ż���Դʹ�õ�Ч�ʣ��Ӷ����� Spark ��ҵ��ִ�����ܡ�
��Ҫ��Դ�IJ������ţ��� driver��executor ���ڴ棬CPU core �������á�
Java �Ķ��ڴ��Ϊ��������������������������������������������ڽ϶̵Ķ��������������������ڽϳ��Ķ���
�������ֿ��Է�Ϊ��������Eden��from Survivor��to Survivor��
�������չ��̣��� Eden ����ʱ��Eden ����һ�� minor GC������ Eden �� From Survivor �д��ڵĶ����Ƶ� to Survivor����ʱ��from Survivor �� to Survivor ���н��������һ�������㹻�ϣ����� to Survivor ����������ƶ�������������������ӽ���ʱ������� full GC��
ͨ���ռ�����������Ϣ���ж��Ƿ���̫����������չ��̡����� full gc ��һ�� task ���֮ǰ�����˺ü��Σ�˵������ task ���ڴ�ռ䲻�㣬��Ҫ���������ڴ��ˡ�
���� JVM �����Ϣ��λ�� spark-default.conf
driver �� executor �� JVM ���ڴ�Ĵ�Сͨ�� driver-memory �� executor.memory ���������á�