Ӧ�ó����ڴ��CPU����
localģʽ �� ����Ҫ��װ spark��Ҳ����Ҫ���� spark ��Ⱥ
standaloneģʽ �� ��Ҫ��װ spark����Ҫ���� spark ��Ⱥ��
yarnģʽ �� ��Ҫ��װ spark��������Ҫ���� spark ��Ⱥ��
�� spark-default.conf �ļ������� spar k����Դ���ã���Դ�������Ϊ spark.xxx���� spark.driver.cores��
�����ַ�ʽ���� spark ���������ԣ������ȼ��Ӹߵ��͡�
- �ڳ��������ͨ�� sparkConf �������ã�
- ͨ�� spark-submit �����ύ�������ã�
- ͨ�� spark-default.conf �ļ����á�
���ȼ���Spark-default.conf < spark-submit �Cconf < SparkConf����

spark-submit --master spark://bigdata01:7077
--conf spark.executor.memory=1201m
--conf spark.executor.cores=1
--class sparkcore.learnTextFile /opt/sparkapp/learnTextFileCode.jar
��
spark .executor.memory 8G
spark.driver.memory 16G
spark.driver.maxResultSize 8G
spark.akka.frameSize 512
���� spark-env.sh ��

�� webUI �Ͽ��Կ�����ÿ�� worker �ڵ㶼���������� executor��һ�� core ���ĺ� 900m �ڴ档

Ӧ�ó������Դ����ʵս
��������������� ���� executor �� cores ���������˿����� cores ������������û���������С�
���磺
spark-submit --master spark://bigdata01:7077
--executor-memory 900m
--executor-cores 6
--class sparkcore.learnTextFile /opt/sparkapp/learnTextFile.jar
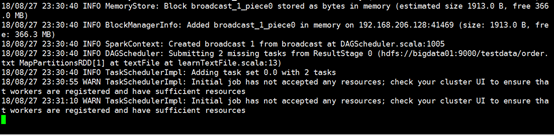
��� worker ���㹻����Դ������ͬһ��Ӧ�ã�����ÿ�� worker �ڵ���������� executor��
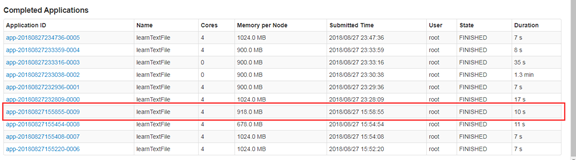
spark-submit --master spark://bigdata01:7077
--executor-memory 918m
--executor-cores 1
--class sparkcore.learnTextFile /opt/sparkapp/learnTextFile.jar

��һ�ֲ�����ֵ�ķ�ʽ --conf PROP=VALUE
spark-submit --master spark://bigdata01:7077
--conf spark.executor.memory=1201m
--conf spark.executor.cores=1
--class sparkcore.learnTextFile /opt/sparkapp/learnTextFile.jar
����������
Spark �����������Ҫ�Ƕ� Spark ���й����и���ʹ����Դ�ĵط���ͨ����������ֵ���Ż���Դʹ��Ч�ʣ����� Spark ��ҵ���ܡ�
num-executors

�ò����������� Spark ��ҵ��Ҫʹ�ö��ٸ� Executor ������ִ�С�Driver �� Yarn ��Ⱥ������������Դʱ��Yarn ��Ⱥ�������ᾡ���ܰ������ò������ڼ�Ⱥ�ĸ��� worker �ڵ��ϣ�������Ӧ������ Executor ���̡�Ĭ�ϲ���ֻ���ṩ������ Executor ���̣���ʱ Spark ��ҵ�������ٶ��Ƿdz����ġ�
�ò������õ�̫�٣�����������ü�Ⱥ��Դ�������������̫�࣬�ֶ��п����������ֵ���Դ��
executor-memory(spark.executor.memory)
�ò�����������ÿ�� Executor ���̵��ڴ档Executor �ڴ�Ĵ�С���ܶ�ʱ��ֱ�Ӿ����� Spark ��ҵ�����ܣ����Ҹ������Ķ� JVM OOM �쳣��Ҳ��ֱ�ӹ�ϵ��
ÿ�� Executor ���̵��ڴ����� 4G ~ 8G ��Ϊ���ʡ�������ֻ��һ���ο�ֵ����������û���Ҫ���ݲ�ͬ���ŵ���Դ������������������������ŷ�����ڴ���Դ����ô����������ڴ��С��ò�Ҫ�������ڴ���Դ�� 1/3 ~ 1/2�������Լ��� Spark ��ҵռ��������Դ������������ҵ�����С�
executor-cores��spark.executor.cores��
�ò�����������ÿ�� Executor ���̵� CPU core �������������������ÿ�� Executor ���̲���ִ�� task �̵߳���������Ϊÿ�� CPU core ͬһʱ��ֻ��ִ��һ��task�̣߳����ÿ�� Executor ���̵� CPU core ����Խ�࣬Խ�ܿ��ٵ�ִ���������Լ������� task �̡߳�
Executor ��CPU core ��������Ϊ 2~3 ���ȽϺ��ʣ�����Ҳ������ݲ�ͬ���ŵ���Դ������������
������������Ź��������Դ����ô���������CPU core���ܳ�����CPU cores�� 1/3 ~ 1/2���ң��������Ա���Ӱ��������ҵ�����С�
driver-memory
�ò����������� driver ���̵��ڴ档
Driver ���ڴ�ͨ������Ҫ���ã��������� 1G ���ҡ����������Ҫ���� collect ���ӽ� RDD ������ȫ����ȥ�� Driver�Ͻ��д�������ô����ȷ�� Driver ���ڴ��㹻������ OOM �ڴ���������⡣
spark.defaultparallelism
�ò�����������ÿ�� stage ��Ĭ�� task ������
���飺spark ��ҵ��Ĭ�� task ������Ϊ 500 ~ 1000 ����Ϊ���ʡ���������������������ô��ʱ�ͻᵼ�� spark �Լ����ݵײ� HDFS �� block ���������� task ������Ĭ����һ��HDFS block ��Ӧһ�� task��ͨ����˵��spark Ĭ�����õ�����ƫ�ٵġ���� taks ����ƫ�٣��ͻᵼ�� executor û���������ܡ�
���磺��� task ֻ��һ������������ô 90% �� executor ���̿��ܸ���û�� task ִ�У�ֻ���˷���Դ��
��ˣ������ֵ����Ϊ��num-executors * executor-cores �� 2~3 ����Ϊ���ʡ�
spark.storage.memoryFraction

�ò����������� RDD �־û������� executor �ڴ�����ռ�ı�����Ĭ���� 0.6���� executor �� 60% ���ڴ���������־û��� RDD ���ݡ�
�� spark ��ҵ�У�����н϶�� RDD �־û���������ô��ֵ���Կ������Щ��Ҳ����˵��� RDD �־û���ռ�ڴ�ı�������֤�־û������ܹ����������ڴ��У������ڴ治�������»����������ݵ����̣����������ܡ�
������� spark ��ҵҪ���бȽ϶�� shuffle ���������־û��IJ����Ƚ��٣���ô�������ֵ���Խ��͵㣬�� shuffle ������ռ�õ��ڴ���ߣ��� RDD �־û����ڴ���١�
������ҵ��Ƶ���ij��� GC ��������ô��ʾ�������Ӳ������ڴ��DZȽϲ����õģ���ô��Ҫ����ֵ��
spark.shuffle.memoryFraction

�ò����������� shuffle �������ܹ�ʹ�õ� executor �ڴ�ı�����Ĭ����0.2��Ҳ����˵��executor ��Ĭ�Ϸ��� 20% ���ڴ����ڽ��� shuffle ���ӵIJ�����shuffle �����ڽ��оۺ�ʱ���������ʹ�õ��ڴ泬���� 20% �����ƣ���ô��������ݽ�����д�������ļ��С���ʱ���ή�����ܡ�
��� spark ��ҵ�е� RDD �־û������Ƚ��٣��� shuffle �����Ƚ϶�ʱ�����齵�ͳ־û����� spark.storage.memoryFraction ���ڴ���ռ�ı�������� shuffle �������ڴ���ռ�ı��������� shuffle ���������ݹ���ʱ�ڴ治���ã���д�����̣��������ܡ�
���Ƶ���� GC �������л�������ζ�� task ִ���û�������ڴ治���ã���ô�������ֵ������Ҫ���͡�
ע���������Ƶ���� GC������Ϊ JVM �������ˣ���Ϊ executor ���������� JVM �У���ô����Ҫ��֤ JVM ���ڴ治����ȫʹ�ã������Ҫ���� spark.storage.memoryFraction ���� spark.shuffle.memoryFraction �ı���ֵ��
���һ�Ҫ֪�� executor-memory ��ϵͳ����� executor ���ڴ��С����ֵ�� spark.storage.memoryFraction �� spark.shuffle.memoryFraction���Լ���������������ͬ�����ġ�
�� standalone ģʽ�£���Ϊ executor �ǽ��̼��𣬶�Ӧһ�� JVM �Ľ��̡�task ���̼߳��𡣶� worker ��ʾʵ��Ľڵ��豸��һ�� worker �ڵ�����ж�� executor ���̣�һ�� executor ���̿����ж�� task �̡߳�ͬʱһ�� task �̶߳�Ӧһ�� CPU core��
��Դ�����ĵ��ţ�û�й̶��IJ���ֵ����Ҫ������Ŀ��ʵ������������á�