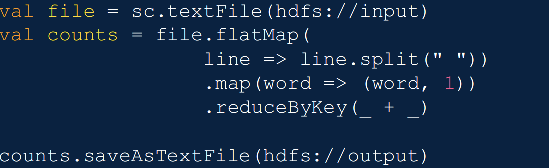
������������map�� reduce̫��ʱ
�C Ҳ��һ���ֲ�ʽ�IJ��м�����
�C ��������ڴ�cache
�C ������ҵ����
java �� python
��
����ģʽ����Ⱥģʽ Spark Standalone����Ⱥģʽ Spark on Yarn ��Ⱥ��yarn-clusterģʽ��
Spark standalone vs. Spark on Yarn
Yarn Client vs. Spark Standlone vs. Yarn ClusterYarn Cluster����������������
Yarn��ͨ�ã�
spark��mapreduce��ҵ֮�������
Spark�У�
Spark�У�Task��������С�Ĺ�����Ԫ
Scala�������������ڱ�����������һ���� :�� �ָ������û��ָ���������ͣ������������Զ��ƶ���
֧�ֵ��������ͣ�
�������ͣ�