Spark系列之:Spark SQL(2)
四、RDD转换为DataFrame
1. 利用反射机制解析RDD
开发前要导入三个包:
import org.apache.spark.sql.Encoder
import org.apache.spark.sql.catalyst.encoders.ExpressionEncoder
import spark.implicits._ //启用隐式转换
(1)创建RDD
sc.textFile(path)
sc.paralle(集合)
sc.makeRDD(集合)
sc.textFile("/home/duck/software/spark/examples/src/main/resources/people.txt")

(2)创建样例类
case class People(name:String,age:Int)

//用“,”分割数据
res0.map(_.split(","))
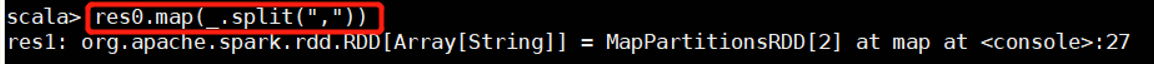
(3)把RDD包装成样例类
res1.map(t=>People(t(0),t(1).trim.toInt))
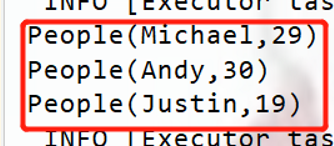
 res2.foreach(println)
res2.foreach(println)

(4)将包装好的样例类转化为DF
res2.toDF
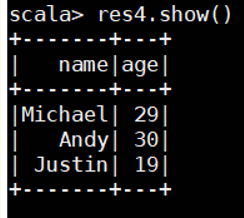
 res4.show()
res4.show()
代码:
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.apache.spark.{SparkConf, SparkContext}
case class People(name: String, age: Int)
object SQLlesson01 {
def main(args: Array[String]): Unit = {
//设置spark
val conf = new SparkConf().setMaster("local").setAppName("sparksql01")
val sc = new SparkContext(conf)
//创建spark sql对象
val sparkSql:SparkSession = SparkSession.builder().config(conf).getOrCreate()
//启用隐式转换
import sparkSql.implicits._
//创建RDD
val unit: RDD[People] = sc.textFile("./people.txt").map(_.split(",")).map(t=>People(t(0),t(1).trim.toInt))
unit.foreach(println)
//转换为DataFrame
val df:DataFrame = unit.toDF()
//创建临时表
df.createOrReplaceTempView("peopleTemp")
//通过临时表查询
sparkSql.sql("select * from peopleTemp").show()
}
}
运行结果:
2. 使用编程方式定义RDD模式

引包:
import org.apache.spark.sql.types._ //类型
import org.apache.spark.sql.Row //行
(1)创建行对象
//获取数据
sc.textFile("/home/duck/software/spark/examples/src/main/resources/people.txt")

//创建行对象
res0.map(_.split(",")).map(t=>Row(t(0),t(1).trim.toInt))

(2)创建表头
Array(StructField("name",StringType,true),StructField("age",IntegerType,true))

//把字段封装进表头
StructType(res2)

(3)将表头和行拼接
spark.createDataFrame(res1,res3)

res4.show()
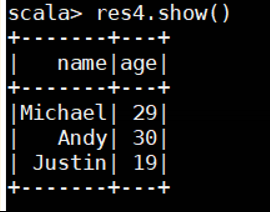
代码:
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.{Row, SparkSession}
import org.apache.spark.{SparkConf, SparkContext}
object SQLlesson02 {
def main(args: Array[String]): Unit = {
//设置spark对象
val conf = new SparkConf().setMaster("local").setAppName("sparkSQL02")
val sc = new SparkContext(conf)
//创建spark sql对象
val spark = SparkSession.builder().config(conf).getOrCreate()
//启用隐式转换
import spark.implicits._
//1. 创建表头
val fields = Array(StructField("name",StringType,true),StructField("age",IntegerType,true))
val structType:StructType = StructType(fields)
//2. 创建行对象
val value:RDD[Row] = sc.textFile("./people.txt").map(_.split(",")).map(t=>Row(t(0),t(1).trim.toInt))
//3. 将表头和行对象拼接
val df = spark.createDataFrame(value,structType)
//创建临时表
df.createOrReplaceTempView("people2")
//通过临时表查询
spark.sql("select * from people2").show()
}
}
五、使用Spark SQL读写数据库(MySQL)
1. 启动MySQL数据库

2. 将mysql驱动包放入spark的jars文件夹中,再启动spark命令行
./spark-shell \
--jars ~/software/spark/jars/mysql-connector-java-5.1.32-bin.jar \
--driver-class-path ~/software/spark/jars/mysql-connector-java-5.1.32-bin.jar

3. 创建jdbc连接
val jdbcDF = spark.read.format("jdbc").
| option("url","jdbc:mysql://Cloud00:3306/test").
| option("driver","com.mysql.jdbc.Driver").
| option("dbtable","tb1").
| option("user","root").
| option("password","admin").
| load()


六、使用spark sql写入MySQL数据库
2. 创建RDD数据
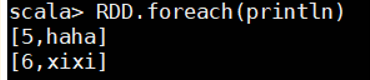
val RDD=sc.parallelize(Array("5 haha","6 xixi")).map(_.split(" ")).map(t=>Row(t(0).trim.toInt,t(1)))

RDD.foreach(println)
3. 创建表头
val schema = StructType(List(StructField("id",IntegerType,true),StructField("name",StringType,true)))

4. 转换为DataFrame
val df = spark.createDataFrame(RDD,schema)

5. 创建配置对象,并设置参数
val prop = new Properties()
prop.put("user","root")
prop.put("password","admin")
prop.put("driver","com.mysql.jdbc.Driver")

6. 写入操作
df.write.mode("append").jdbc("jdbc:mysql://Cloud00:3306/test","tb1",prop)


七、通过spark sql将数据写入hive
- 启动Hadoop集群、YARN和spark集群
- 启动MySQL
- 启动hive
1. 将hive中的配置文件hive-site.xml拷贝到spark/conf目录下,并添加配置

-
启动元数据监听
hive --service metastore &

3. 引包
import org.apache.spark.sql.types._
import org.apache.spark.sql.Row
4. 创建RDD对象 以及数据
val RowRDD = sc.parallelize(Array("7 zs","8 lisi")).map(_.split(" ")).map(t=>Row(t(0).trim.toInt,t(1)))

5. 设置表头信息
val schema = StructType(Array(StructField("id",IntegerType,true),StructField("name",StringType,true)))

6. 将RDD对象和表头拼接并转换为DataFrame
val DF=spark.createDataFrame(RowRDD,schema)

7. 注册临时表
DF.createOrReplaceTempView("stu")

8. 添加数据到hive并查看
sql("insert into pgdb.student select * from stu")
在hive中查看
 ***
***
--->有问题请联系
