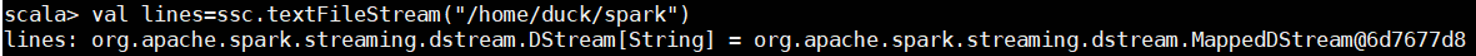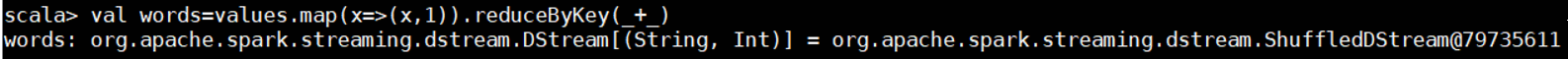数据密集型,数据 大量、快速、时变的流形式。
秉承的基本概念是数据的价值随着时间的流逝而降低 ,如用户点击量。因此,这些数据应该立即处理,而不是缓存起来进行批量处理。为了及时处理流数据,就需要一个低延迟、可扩展、高可靠的处理引擎。
a. 高性能:如每秒处理几十万条数据
b. 海量式:支持TB级甚至是PB级的数据规模
c. 实时性:保证较低的延迟时间,达到秒级别,甚至是毫秒级别
d. 分布式:支持大数据的基础架构,必须能够平滑扩展
e. 易用性:能够快速进行开发和部署
f. 可靠性:能可靠地处理流数据
目前常见的三类流计算框架和平台:商业级的流计算平台、开源流计算框架、公司为支持自身业务开发的流计算框架。
商业级:IBM InfoSphere Stream和IBM StreamBase
较为常见的开源流计算框架:Twitter Strom :免费、开源的分布式实时计算系统Yahoo!S4 (Simple Scalable Streaming System):开源流计算平台,是通用的、分布式的、可扩展的、分区容错的、可插拔式的流式系统Dstream Facebook Puma 银河流数据处理平台(淘宝)
a. 数据实时采集:需要保证实时性、低延迟与稳定可靠。 Facebook的Scribe LinkedIn的Kafka 淘宝的Time Tunnel 基于Hadoop的Chukwa和Flume b. 数据实时计算:对采集的数据进行实时的分析和计算,并反馈实施结果。 c. 数据实时查询:经由流计算框架得出的结果可供用户进行实时查询、展示和储存。
a.
b. 基本原理:将实时输入数据流以时间片(秒级)为单位进行拆分,然后经过spark引擎以类似批处理的方式处理每个时间片数据。
c. Spark Streaming最主要的抽象是DStream (Discretized Stream,离散化数据流),表示连续不断的数据流。在内部实现上,Spark Streaming的输入数据按照时间片(如1秒)分成一段一段,每一段数据转换为spark中的RDD,这些分段就是DStream,并且对DStream的操作都最终转变为对相应的RDD的操作。
①. Spark Streaming无法实现毫秒级的流计算,而Storm可以实现毫秒级相应。
使用Spark架构具有的优点:
l 实现一键式安装和配置,线程级别的任务监控和告警;
l 降低硬件集群、软件维护、任务监控和应用开发的难度;
l 便于做成统一的硬件、计算平台资源池。
a. 在Spark Streaming中,会有一个组件Receiver,作为一个长期运行的task跑在一个Executor上。
b. 每个Receiver都会负责一个Input DStream(比如从文件中读取数据的文件流,比如套接字流,或者从Kafka中读取的一个输入流等)
c. Spark Streaming通过input DStream与外部数据进行连接,读取相关数据。
a. 通过创建输入DStream来定义输入流; b. 通过对DStream应用转换操作来定义流计算; c. 用StreamingContext.start()来开始接收数据和处理数据; d. 通过StreamingContext.awaitTermination()方法来等待处理结束; e. 可以通过StreamingContext.stop()来手动结束流计算进程。
a. 引包
import org.apache.spark.streaming._
b. 设置间隔时间
val ssc=new StreamingContext(sc,Seconds(20))
c. 读取文件
val lines=ssc.textFileStream("/home/duck/spark")
d. 按格式提取数据
val values=lines.flatMap(_.split(" "))
val words=values.map(x=>(x,1)).reduceByKey(_+_)
e. 启动并查看结果
words.print()
ssc.start() //启动流计算
import org.apache.log4j.Logger
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
object stream01 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[2]").setAppName("stream01")
val ssc = new StreamingContext(conf,Seconds(20))
Logger.getLogger("org.apache.spark")
val lines:DStream[String] = ssc.textFileStream("D:\\IDEA\\src\\scalaLesson\\log")
val words:DStream[String] = lines.flatMap(_.split(" "))
val values:DStream[(String,Int)] = words.map(t=>(t,1))
val wordcount:DStream[(String,Int)] = values.reduceByKey(_+_)
wordcount.print()
ssc.start()
ssc.awaitTermination()
ssc.stop()
}
}
a. 写好程序代码
bin/spark-submit \
--class com.spark.streaming.stream01 \
/home/duck/Lesson-1.0-SNAPSHOT.jar
--->有问题请联系