版权声明:微信公众号:芥子观须弥 https://blog.csdn.net/qq_36589234/article/details/90209541
注:本文章是在阿里云 centos7.3 上运行 spark。
目录
1. spark简介
1.1 特点
1.2 与hadoop MapReduce相比的优点
1.3 基本概念
1.4 架构设计
2. spark 安装
2.1 安装jdk
2.2 centos上安装 python 3
2.3 安装hadoop
2.4安装spark
3.第一个Spark应用程序:WordCount
1. spark简介
spark是基于内存计算的大数据并行计算框架,可用于构建大型的、低延迟的数据分析应用程序 。
1.1 特点
运行速度快:使用DAG执行引擎以支持循环数据流与内存计算
容易使用:支持使用Scala(主要编程语言)、 Java、 Python和R语言进行编程,可以通过Spark Shell进行交互式编程
通用性: Spark提供了完整而强大的技术栈,包括SQL查询、流式计算、机器学习和图算法组件
运行模式多样:可运行于独立的集群模式中,可运行于Hadoop中,也可运行于Amazon EC2等云环境中,并且可以访问HDFS、 Cassandra、HBase、 Hive等多种数据源
1.2 与hadoop MapReduce相比的优点
Spark的计算模式也属于MapReduce,但不局限于Map和Reduce操作,还提供了多种数据集操作类型,编程模型比Hadoop MapReduce更灵活
Spark提供了内存计算,可将中间结果放到内存中,对于迭代运算效率更高
Spark基于DAG的任务调度执行机制,要优于Hadoop MapReduce的迭代执行机制
1.3 基本概念
RDD:是弹性分布式数据集(Resilient Distributed Dataset)的简称,是分布式内存的一个抽象概念,提供了一种高度受限的共享内存模型;
DAG:是Directed Acyclic Graph(有向无环图)的简称,反映RDD之间的依赖关系;
Executor:是运行在工作节点(Worker Node)上的一个进程,负责运行任务,并为应用程序存储数据;
Application:用户编写的Spark应用程序;
Task:运行在Executor上的工作单元;
Job:一个Job包含多个RDD及作用于相应RDD上的各种操作;
Stage:是Job的基本调度单位,一个Job会分为多组Task,每组Task被称为“Stage”,或者也被称为“TaskSet”,代表了一组关联的、相互之间没有Shuffle依赖关系的任务组成的任务集。
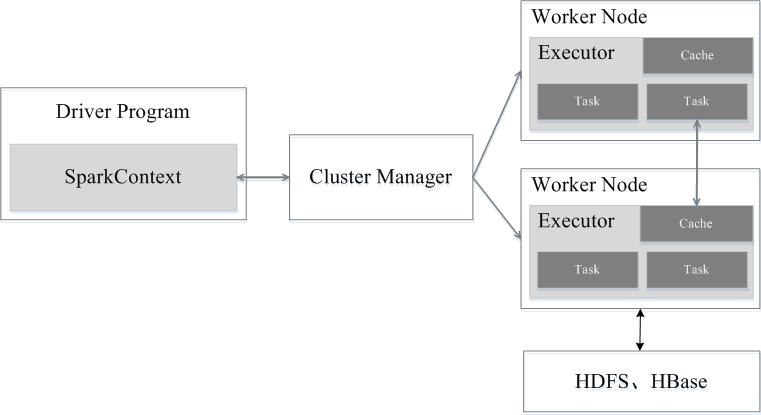
1.4 架构设计
一个Application由一个Driver和若干个Job构成,一个Job由多个Stage构成,一个Stage由多个没有Shuffle关系的Task组成。
Spark运行架构包括:每个应用的任务控制节点(Driver)、群资源管理器(Cluster Manager)、运行作业任务的工作节点(Worker Node)、和每个工作节点上负责具体任务的执行进程(Executor)
2. spark 安装
2.1 安装jdk
参考:【Linux】CentOS7下安装JDK详细过程 ,其中注意【JDK和Open JDK】平常使用的JDK和Open JDK有什么区别 。
2.2 centos上安装python 3
参考:Centos 7安装python3
安装时出现yum包依赖的python2.7被修改的问题(报错信息:[Errno 5] [Errno 2] No such file or directory),因此还需要修改 /usr/bin/yum ;/usr/libexec/urlgrabber-ext-down 两个文件,把他们的文件开头改成 /usr/bin/python2.7
然后执行
yum clean all
yum makecache
2.3 安装hadoop
centos上安装hadoop,参考Hadoop安装教程_伪分布式配置_CentOS6.4/Hadoop2.6.0
2.4安装spark
参考:Spark2.1.0+入门:Spark的安装和使用(Python版)
坑:在~/.bashrc 里配置环境变量时,PYTHONPATH里py4j的版本号要根据SPARK_HOME/python/lib/目录里自己的版本号一致,否则会出现找不到找不到py4j-0.10.7-src.zip的错误。
3.第一个Spark应用程序:WordCount
天坑:python命令行下import zlib没有问题,可是pyspark下运行程序会报zlib缺失,待解 ̄へ ̄