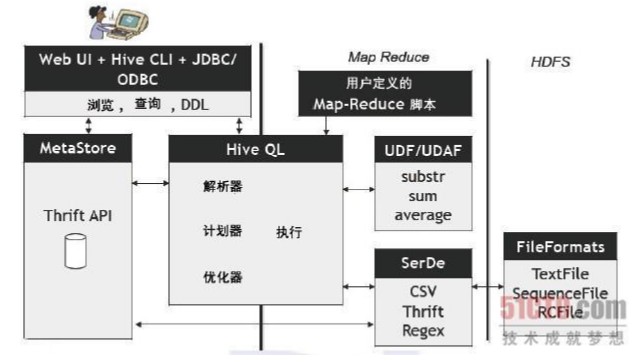
Ĭ������£�HiveԪ���ݱ�������Ƕ�� Derby ���ݿ��У�ֻ������һ���Ự���ӣ�ֻ�ʺϼIJ��ԡ�Ϊ��֧�ֶ��û���Ự������Ҫһ��������Ԫ���ݿ⣬����ʹ�� MySQL ��ΪԪ���ݿ⣬Hive �ڲ��� MySQL �ṩ�˺ܺõ�֧�֡�
�������Ŀ��ֱ���ԣ�
1. ��ͨ��hdfs�ļ����뵽hive�С�
����һ��rootĿ¼��һ����ͨ�ļ���
[root@db96 ~]# cat hello.txt
# This is a text txt
# by coco
# 2014-07-18
��hive�е�����ļ���
hive> create table pokes(foo int,bar string);
OK
Time taken: 0.068 seconds
hive> load data local inpath '/root/hello.txt' overwrite into table pokes;
Copying data from file:/root/hello.txt
Copying file: file:/root/hello.txt
Loading data to table default.pokes
rmr: DEPRECATED: Please use 'rm -r' instead.
Deleted hdfs://db96:9000/user/hive/warehouse/pokes
Table default.pokes stats: [numFiles=1, numRows=0, totalSize=59, rawDataSize=0]
OK
Time taken: 0.683 seconds
hive> select * from pokes;
OK
NULL NULL
NULL NULL
NULL NULL
NULL NULL
NULL NULL
Time taken: 0.237 seconds, Fetched: 5 row(s)
hive>
hive> load data local inpath '/root/hello.txt' overwrite into table test;
Copying data from file:/root/hello.txt
Copying file: file:/root/hello.txt
Loading data to table default.test
rmr: DEPRECATED: Please use 'rm -r' instead.
Deleted hdfs://db96:9000/hive/warehousedir/test
Failed with exception Unable to alter table.
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.MoveTask
hive> show tables;
OK
hivetest
pokes
test
test3
Time taken: 1.045 seconds, Fetched: 4 row(s)
hive> select * from test;
OK
# This is a text txt NULL
# by coco NULL
# 2014-07-18 NULL
NULL
hello world!! NULL
Time taken: 1.089 seconds, Fetched: 5 row(s)
�����濴����ɹ������Dz�ѯ�Ķ���null��������Ϊû�мӷָ�.test��Ĭ�ϵ���terminated by '\t'
lines terminated by '\n' �ָ��������Ծ����б���������Ҳ�Dz���ġ�
��ȷ�ĵ����Ϊ��
create table aaa(time string,myname string,yourname string) row format delimited
fields terminated by '\t' lines terminated by '\n' stored as textfile
hive> create table aaa(time string,myname string,yourname string) row format delimited
> fields terminated by '\t' lines terminated by '\n' stored as textfile;
OK
Time taken: 1.011 seconds
hive> load data local inpath '/root/aaaa.txt' overwrite
> into table aaa;
Copying data from file:/root/aaaa.txt
Copying file: file:/root/aaaa.txt
Loading data to table default.aaa
rmr: DEPRECATED: Please use 'rm -r' instead.
Deleted hdfs://db96:9000/hive/warehousedir/aaa
[Warning] could not update stats.
OK
Time taken: 2.686 seconds
hive> select * from aaa;
OK
20140723,yting,xmei NULL NULL
Time taken: 0.054 seconds, Fetched: 1 row(s)
2. ��ѯ�����������
��hive�аѱ��е����ݵ�������������ı����͡�
�ȼ�����Ҫ�Ľ����
hive> select time from aaa;
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1405999790746_0002, Tracking URL = http://db96:8088/proxy/application_1405999790746_0002/
Kill Command = /usr/local/hadoop//bin/hadoop job -kill job_1405999790746_0002
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
2014-07-23 16:28:51,690 Stage-1 map = 0%, reduce = 0%
2014-07-23 16:29:02,457 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.33 sec
MapReduce Total cumulative CPU time: 1 seconds 330 msec
Ended Job = job_1405999790746_0002
MapReduce Jobs Launched:
Job 0: Map: 1 Cumulative CPU: 1.33 sec HDFS Read: 221 HDFS Write: 20 SUCCESS
Total MapReduce CPU Time Spent: 1 seconds 330 msec
OK
20140723,yting,xmei
Time taken: 26.281 seconds, Fetched: 1 row(s)
����ѯ������������Ŀ¼
hive> insert overwrite local directory '/tmp' select a.time from aaa a;
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1405999790746_0004, Tracking URL = http://db96:8088/proxy/application_1405999790746_0004/
Kill Command = /usr/local/hadoop//bin/hadoop job -kill job_1405999790746_0004
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
2014-07-23 16:34:28,474 Stage-1 map = 0%, reduce = 0%
2014-07-23 16:34:35,128 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.27 sec
MapReduce Total cumulative CPU time: 1 seconds 270 msec
Ended Job = job_1405999790746_0004
Copying data to local directory /tmp
Copying data to local directory /tmp
MapReduce Jobs Launched:
Job 0: Map: 1 Cumulative CPU: 1.27 sec HDFS Read: 221 HDFS Write: 20 SUCCESS
Total MapReduce CPU Time Spent: 1 seconds 270 msec
OK
Time taken: 21.943 seconds
���Կ���/tmp��ȷʵ��һ���ļ���000000_0�����ļ�������Ϊ�����Dz�ѯ���������ݡ�
root@db96 tmp]# ll
������ 4
-rw-r--r-- 1 root root 20 7�� 23 16:34 000000_0
[root@db96 tmp]# vim 000000_0
20140723,yting,xmei
~
�ܶ�ʱ��������hive��ִ��select��䣬ϣ�������յĽ�����浽�����ļ����߱��浽hdfsϵͳ��
���߱��浽һ���µı��У�hive�ṩ�˷���Ĺؼ��ʣ���ʵ�����������Ĺ��ܡ�
1.��select�Ľ���ŵ�һ���ĵı����У�����Ҫ��create table�����µı���
insert overwrite table test select uid,name from test2;
2.��select�Ľ���ŵ������ļ�ϵͳ��
INSERT OVERWRITE LOCAL DIRECTORY '/tmp/reg_3' SELECT a.* FROM events a;
3.��select�Ľ���ŵ�hdfs�ļ�ϵͳ��
INSERT OVERWRITE DIRECTORY '/tmp/hdfs_out' SELECT a.* FROM invites a WHERE a.ds='<DATE>';
����ʾ����
hive> select a.time from aaa a;
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1405999790746_0005, Tracking URL = http://db96:8088/proxy/application_1405999790746_0005/
Kill Command = /usr/local/hadoop//bin/hadoop job -kill job_1405999790746_0005
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
2014-07-23 16:47:42,295 Stage-1 map = 0%, reduce = 0%
2014-07-23 16:47:49,567 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.19 sec
MapReduce Total cumulative CPU time: 1 seconds 190 msec
Ended Job = job_1405999790746_0005
MapReduce Jobs Launched:
Job 0: Map: 1 Cumulative CPU: 1.19 sec HDFS Read: 221 HDFS Write: 20 SUCCESS
Total MapReduce CPU Time Spent: 1 seconds 190 msec
OK
a.time
20140723,yting,xmei
Time taken: 21.155 seconds, Fetched: 1 row(s)
hive> create table jieguo(content string);
OK
Time taken: 2.424 seconds
hive> insert overwrite table jieguo
> select a.time from aaa a;
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1405999790746_0006, Tracking URL = http://db96:8088/proxy/application_1405999790746_0006/
Kill Command = /usr/local/hadoop//bin/hadoop job -kill job_1405999790746_0006
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
2014-07-23 16:49:50,689 Stage-1 map = 0%, reduce = 0%
2014-07-23 16:49:57,329 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.3 sec
MapReduce Total cumulative CPU time: 1 seconds 300 msec
Ended Job = job_1405999790746_0006
Stage-4 is selected by condition resolver.
Stage-3 is filtered out by condition resolver.
Stage-5 is filtered out by condition resolver.
Moving data to: hdfs://db96:9000/hive/scratchdir/hive_2014-07-23_16-49-36_884_4745480606977792448-1/-ext-10000
Loading data to table default.jieguo
rmr: DEPRECATED: Please use 'rm -r' instead.
Deleted hdfs://db96:9000/hive/warehousedir/jieguo
Failed with exception Unable to alter table.
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.MoveTask
MapReduce Jobs Launched:
Job 0: Map: 1 Cumulative CPU: 1.3 sec HDFS Read: 221 HDFS Write: 90 SUCCESS
Total MapReduce CPU Time Spent: 1 seconds 300 msec
hive> show tables;
OK
tab_name
aaa
hello
hivetest
jieguo
pokes
test
test3
Time taken: 1.03 seconds, Fetched: 7 row(s)
hive> select * from jieguo;
OK
jieguo.content
20140723,yting,xmei
Time taken: 1.043 seconds, Fetched: 1 row(s)