��Ȩ����������Ϊ����ԭ�����£�δ��������������ת�ء� https://blog.csdn.net/u010168160/article/details/51720661
���ǽ���֮ǰѧϰ�Ĵ�������ѧϰ��֮ǰ˵����NoSql��HBase���ݿ��Լ�Hadoop�е�HDFS�洢ϵͳ���������Ƿ����������ƽʱ���õĹ�ϵ�����ݿ��кܴ�����Ϊ��ʹ�÷��㣬��������Դ����ݴ洢�����ݲֿ�Hive��
һ����ʲô
1������
Hive ��һ������ Hadoop �Ŀ�Դ���ݲֿ�ߣ����ڴ洢�ʹ��������ṹ�����ݡ� ���Ѻ������ݴ洢�� hadoop �ļ�ϵͳ�����������ݿ⣬���ṩ��һ�������ݿ�����ݴ洢�ʹ������ƣ������� HQL ���� SQL �����Զ���Щ���ݽ����Զ��������ʹ��������ǿ��� Hive �к����ṹ�����ݿ���һ�����ı�����ʵ������Щ�����Ƿֲ�ʽ�洢�� HDFS �еġ� Hive �����������н�����ת������������һϵ�л��� hadoop �� map/reduce ����ͨ��ִ����Щ����������ݴ�����
2����ϵ�ṹ
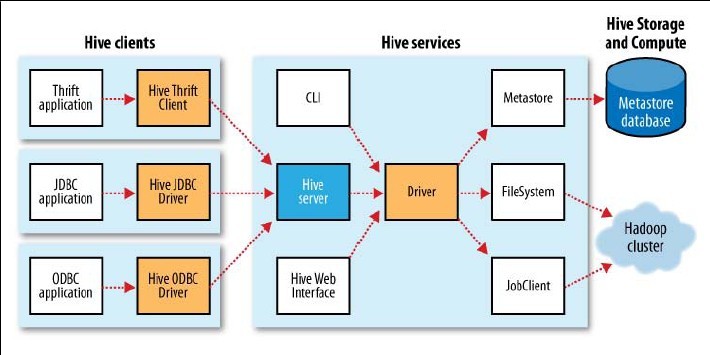
hiveserver������ʽ��hive �Cservice hiveserver
HiveServer֧�ֶ������ӷ�ʽ��Thrift��JDBC��ODBC
metastore�����洢hive��Ԫ������Ϣ(�������ݿⶨ���)��Ĭ��������Ǻ�hive�ģ�������ͬһ��JVM�У���Ԫ���ݴ洢��Derby��
���ַ�ʽ���õ�һ����û�а취Ϊһ��Hive�������ʵ��(Derby�ڶ������ʵ��֮��û�а취����)
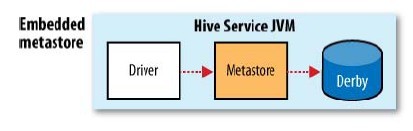
Hive�ṩ����ǿ���ã��ɽ����ݿ��滻��MySql�ȹ�ϵ���ݿ⣬���洢���ݶ��������ڶ������ʵ��֮�乲��
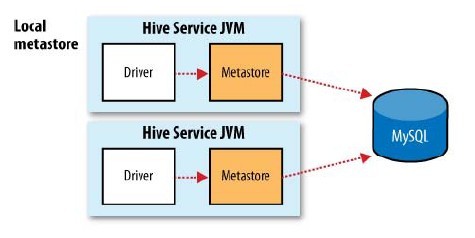
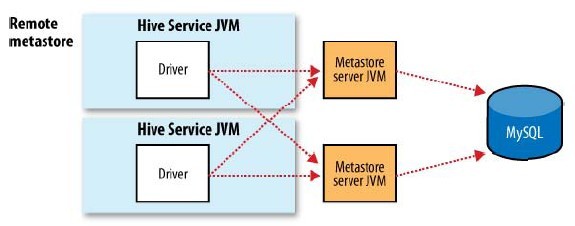
���������Խ�metastore ServiceҲ������������������JVM��ȥ����ͨ��Զ�̵��õķ�ʽȥ����
3����ȱ��
����չ
Hive�������ɵ���չ��Ⱥ�Ĺ�ģ��һ������²���Ҫ��������
��չ��
Hive֧���û��Զ��庯�����û����Ը����Լ���������ʵ���Լ��ĺ���
�ݴ�
���õ��ݴ��ԣ��ڵ��������SQL�Կ����ִ��
��֧�ּ�¼����ĸ��¡������ɾ������
Hive����һ�����������ݿ⡣Hadoop�Լ�hdfs����Ʊ���Լ���;����Ե�������hive����ʤ�εĹ�����Hive��֧�ּ�¼����ĸ��¡������ɾ�������������û�����ͨ����ѯ�����±����߽���ѯ������뵽�ļ��С�
��ѯ��ʱ�Ƚ�����
��ΪHadoop��һ��������������ϵͳ����mapreduce����job��������������Ҫ���Ľϳ���ʱ�䣬����hive��ѯ��ʱ�Ƚ����ء���ͳ���ݿ������뼶������ɵIJ�ѯ����hive�У���ʱ���ݼ���Խ�С������Ҳ��Ҫִ�и�����ʱ�䡣
����Hadoop������ʱ�俪���ܴ���Hadoop��������������������ݹ�ģ�dz�������ύ��ѯ�ͷ��ؽ���ǿ��ܾ��зdz������ʱ�ģ�����hive����������OLAP�ġ����������֣�����Ŀǰ��û�����㡣����û���Ҫ�Դ��ģ����ʹ��OLTP���ܵĻ�����ôӦ��ѡ��ʹ��һ��NOSQL���ݿ⡣���磬��Hadoop���ʹ�õ�HBase��Cassandra.
��֧������
���������ϵ
1����HBase�Ĺ�ϵ
Hive�ǻ���Hadoop��һ�����ݲֿ�ߣ���Ϊ��дMapReduce��������ģ�Hiveʮ���ʺ����ݲֿ��ͳ�Ʒ�����
HBase��һ���ֲ�ʽ�ġ������еĿ�Դ���ݿ⣬����һ���ʺ��ڷǽṹ�����ݴ洢�����ݿ⡣
2����RDBMS�Ĺ�ϵ
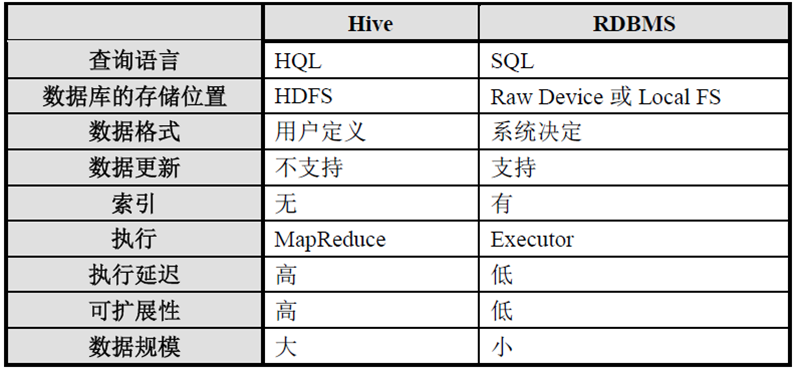
�ܽ
��������ͨ����Hive��ѧϰ���Դ����ݵĴ���������һ������ʶ�����Ժ��ʵ�ʲ����У�����ȥ��������Hive��ʹ�÷�����ͨ������ѧϰ���ﵽ�Լ������Ŀ�ꡣ