转载自51cto :http://yaoyinjie.blog.51cto.com/3189782/923378
在hive查询中要限制查询输出条数, 可以用limit 关键词指定,如 select columnname1 from table1 limit 10; 这样hive将输出符合查询条件的10个记录,从根本上说, hive是hadoop提交作业的客户端,它使用antlr词法语法分析工具,对SQL进行分析优化后翻译成一系列MapReduce作业,向hadoop提交运行作业以得到结果.
看一条简单的SQL语句:
- selectdeviceidfromt_aa_pc_logwherept='2012-07-07-00'limit1;
这条语句指定分区字段 pt为2012-07-07-00, 限制结果为 limit 1. 假设运行这个MR作业需要5个map, 那么每个map应该输出一条记录,从jobtrack 的jobdetails页面中的计数器中 Map Input Records 一项应该显示为5(即该作业中Map阶段总共输入5条记录),结果是否如预计的那样, 通过运行改SQL来验证:
- >selectdeviceidfromt_aa_pc_logwherept='2012-07-07-00'limit1;
- TotalMapReducejobs=1
- LaunchingJob1outof1
- Numberofreducetasksissetto0sincethere'snoreduceoperator
- StartingJob=job_201205162059_1547550,TrackingURL=http://jt.dc.sh-wgq.sdo.com:50030/jobdetails.jspjobid=job_201205162059_1547550
- KillCommand=/home/hdfs/hadoop-current/bin/hadoopjob-Dmapred.job.tracker=10.133.10.103:50020-killjob_201205162059_1547550
- 2012-07-0716:22:42,570Stage-1map=0%,reduce=0%
- 2012-07-0716:22:48,628Stage-1map=80%,reduce=0%
- 2012-07-0716:22:49,640Stage-1map=100%,reduce=0%
- 2012-07-0716:22:50,654Stage-1map=100%,reduce=100%
- EndedJob=job_201205162059_1547550
- OK
- 0cf49387a23d9cec25da3d76d6988546
- Timetaken:13.499seconds
- hive>
正如limit 1限制,输出一条记录,再通过http://jt.dc.sh-wgq.sdo.com:50030/jobdetails.jspjobid=job_201205162059_1547550
查看Map Input Records项:

上图显示Map Input Records实际上是35,并非之前设想的每个MAP一条,总共5条,那多出来的30条记录又是怎么来的 实际上这个跟hive mapreduce实现有关,先来看看上面这条SQL的执行计划:
- >explainselectdeviceidfromt_aa_pc_logwherept='2012-07-07-00'limit1;
- OK
- STAGEDEPENDENCIES:
- Stage-1isarootstage
- Stage-0isarootstage
- STAGEPLANS:
- Stage:Stage-1
- MapReduce
- Alias->MapOperatorTree:
- t_aa_pc_log
- TableScan
- alias:t_aa_pc_log
- FilterOperator
- predicate:
- expr:(pt='2012-07-07-00')
- type:boolean
- SelectOperator
- expressions:
- expr:deviceid
- type:string
- outputColumnNames:_col0
- Limit
- FileOutputOperator
- compressed:false
- GlobalTableId:0
- table:
- inputformat:org.apache.hadoop.mapred.TextInputFormat
- outputformat:org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
- Stage:Stage-0
- FetchOperator
- limit:1
- Timetaken:0.418seconds
改执行计划显示,Stage-1 是一个MR程序,且只有map过程, 没有reduce过程,也就是说在Map过程就直接将结果输出到HDFS文件系统, Stage-0是依赖于Stage-1的文件读取操作,它不是MR作业,只是一个基于hadoop文件系统客户端的分布式文件读取程序。
重点分析Stage-1过程,一条记录被读取后调用hive自定义mapper函数,依次经过
TableScanOperator ->Filter Operator ->Select Operator ->Limit Operator->File Output Operator, 以上每一个Operator都是hive定义的一个处理过程, 每一个 Operator都定义有:
- protectedList<Operator<extendsSerializable>>childOperators;
- protectedList<Operator<extendsSerializable>>parentOperators;
这样就构成了一个 Operator图,hive正是基于这些图关系来处理诸如limit, group by, join等操作. Operator 基类定义一个:
- protectedbooleandone;// 初始化值为false
这个字段指示某一个层级的Operator是否已经处理完成,每当一条记录进入特定的Operator操作时,当前Operator会判断自己的childOperators 的done是否全部为true, 如果是, 表示childOperators已去全部处理完毕, 当前这个Operator也把自己的 done设置为true, 这样层层返回,直到最外层的Operator, 这个查询中涉及的部分Operator如下图:

该hive MR作业中指定的mapper是:
- mapred.mapper.class= org.apache.hadoop.hive.ql.exec.ExecMapper
input format是:
- hive.input.formatorg.apache.hadoop.hive.ql.io.CombineHiveInputFormat
部分执行流程:
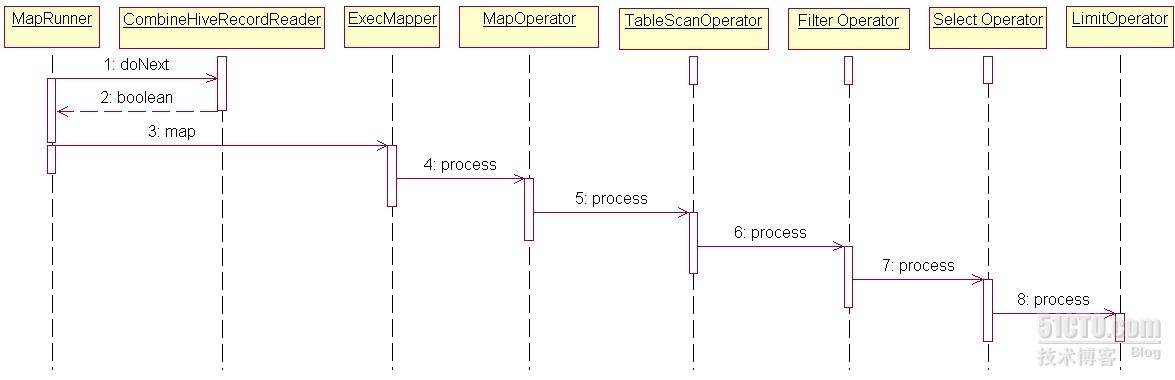
MapRunner会循环调用CombineHiveRecordReader的doNext方法读入行记录,直到doNext方法返回false, doNext方法中有一个重要的逻辑来控制记录读取是否结束
- @Override
- publicbooleandoNext(Kkey,Vvalue)throwsIOException{
- if(ExecMapper.getDone()){
- returnfalse;
- }
- returnrecordReader.next(key,value);
- }
每读取一条记录都会判断 MapRunner.getDone()是否为真, 如果是则结束Mapper读取过程, ExecMapper类中定义了一个静态变量done(静态非常重要,因为在hadoop框架下执行时 CombineHiveRecordReader无法拿到 ExecMapper实例), 当 MapRunner读取一条记录后就会调用 MapRunner的map函数, ExecMapper中定义了一个MapOperator,MapOperator的 childOperators列表中持有TableScanOperator实例,依次类推,
各Operator递归包含.
ExecMapper的map函数被调用时会先判断 MapOperator的done是否为true, 如果是,则将自己的静态变量done设置为true(这样 CombineHiveRecordReader在下一次读取记录时发现 ExecMapper的done为true, 结束mapper记录读取),否则执行MapOperator的process方法, 具体逻辑如下:
- publicvoidmap(Objectkey,Objectvalue,OutputCollectoroutput,
- Reporterreporter)throwsIOException{
- if(oc==null){
- oc=output;
- rp=reporter;
- mo.setOutputCollector(oc);
- mo.setReporter(rp);
- }
- //resettheexecContextforeachnewrow
- execContext.resetRow();
- try{
- if(mo.getDone()){
- done=true;
- }else{
- //Sincethereisnoconceptofagroup,wedon'tinvoke
- //startGroup/endGroupforamapper
- mo.process((Writable)value);
接下来再看看各Operator如何判断自己状态是否为执行完成:
- intchildrenDone=0;
- for(inti=0;i<childOperatorsArray.length;i++){
- Operator<extendsSerializable>o=childOperatorsArray[i];
- if(o.getDone()){
- childrenDone++;
- }else{
- o.process(row,childOperatorsTag[i]);
- }
- }
- //ifallchildrenaredone,thisoperatorisalsodone
- if(childrenDone==childOperatorsArray.length){
- setDone(true);
- }
每个Operator都判断自己的子Operator状态是否全部完成, 如果是则把自己的状态也设置成done=true.
最后再看LimitOperator的判断逻辑:
- @Override
- publicvoidprocessOp(Objectrow,inttag)throwsHiveException{
- if(currCount<limit){
- forward(row,inputObjInspectors[tag]);
- currCount++;
- }else{
- setDone(true);
- }
- }
currCount是一个记录处理的计数器, 初始值为0, 当该值大于等于limit后,将自己标识成处理完成状态,即设置done=true.
分析到现在, 已经可以非常清晰的解释最初的疑问了, 为什么 limit 1, map数为5的前提下, Map Input Records 是35而不是5
1. 第一条记录进入LimitOperator done 为false
2. 第二条记录进入LimitOperator done 为true
3. 第三条记录进入SelectOperator done 设置为true
4. 第四条记录进入FilterOperator done设置为true
5. 第五条记录进入TableScanOperator done设置为true
6. 第六条记录进入MapOperator done设置为true
7. 第7条记录进入ExecMapper 静态变量done设置为true
8. 读取第八条记录时 CombineHiveRecordReader发现 ExecMapper的done已经为true, 结束数据读取,从而 MapRunner退出循环, 结束mapper过程.
从上面8个步骤看出, 每个map会读取7条记录, 5个map, 正好是35条记录.
在平时工作中, 通过分析 hive 执行计划可以让我们清楚的知道MR中的每一个过程,理解HIVE执行过程, 进而对SQL优化.