Hive����&�ϴ�&��ѹ
Hive���ص�ַ: https://mirrors.tuna.tsinghua.edu.cn/apache/hive/, ѡ�����õİ汾, �������ʹ��apache-hive-1.2.1-bin.tar.gz. ע������������ֻ��1.2.2�汾, ԭ��������ϰ汾���ٷ���, ��1.2.1��1.2.2�������.
�������֮��, ͨ�����乤��(Xftp,filezilla��)��Hive��װ���ϴ�����Ⱥ��node01��client�ڵ���.
��ѹHive��װ��:
tar -zxf apache-hive-1.2.1-bin.tar.gz -C /opt/software/hive
��hive-site.xml.template�ļ�����:
cd /opt/software/hive/apache-hive-1.2.1/conf
cp hive-default.xml.template hive-site.xml
Hive�������ģʽ
(һ)����Derby��Localģʽ(������)
�
��Hive���������˵��, Hive������ϵ�����ݿ�洢Ԫ������Ϣ. Derby��HiveĬ�ϵ�Ԫ���ݿ�(Metastore).
���ִ��ʽ�����, ֻ���ڸ������hive-site.xml�������ļ���.
��hive-site�ļ�:
vim /opt/software/hive/apache-hive-1.2.1/conf/hive-site.xml
����ɾ��<configuration> </configuration>��ǩ���е�����Ȼ�������������
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:derby:;databaseName=metastore_db;create=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>org.apache.derby.jdbc.EmbeddedDriver</value>
</property>
<property>
<name>hive.metastore.local</name>
<value>true</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
����
Hive������HDFS��MapReduce, ���������Hive֮ǰ, Ӧ������HDFS��Yarn(���û��ʹ��SQL�����Բ�������Yarn).
����Hive, ����Hive Shell (��Ҫ�����û�������)
hive
��ʱ, ����Hive�ᱨjava.lang.IncompatibleClassChangeError�Ĵ�, ���������˲鿴
��Ҫע��:
- ʹ��derby�洢��ʽʱ, ����hive���ڵ�ǰĿ¼����һ��derby�ļ���һ��metastore_dbĿ¼.
- Derbyģʽ�����ȱ�������������û�ͬʱ����Hive, ���һ���û��Ѿ���Hive Shell, ��ô�������ڶ��������ӵ�Hive��. ���ȱ������Derby����ȱ����ɵ�, ����Hive������. ������ִ��ʽ������.
(��)����MySQL��Localģʽ
�����ᵽDerby����ȱ��, Ϊ���ֲ��ⷽ��IJ���, ��������ʹ��mysql���ݿ����洢Hive��Ԫ����. ����MySQL��ʵ����ʹ��mysql������derby.
���ִ洢��ʽ��Ҫ�ڱ�������һ��mysql������, Ȼ��������Hive.
��client�ڵ㰲װmysql
����client����Hadoop�İ�װ��������HADOOP_HOME, �����ҵ�Hadoop�������ļ�, ���client�˴Hive���Բ���Hadoop��Ⱥ.
- ��װmysql������
yum install mysql-server -y
service mysqld start
�鿴mysql״̬:
service mysqld status
- ��Ȩ��
�ȵ�¼mysql
mysql -uroot -p77123
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '77123' WITH GRANT OPTION;
ע������*IDENTIFIED BY ��77123��*���ұ���mysql��root�û�����, ��Ȩ��ʱ��Ҫ�ijɶ�Ӧmysql������.
- ɾ�������ֶ�
use mysql;
delete from user where host like '%127%';
user ���ж���������ֶο��ܻ��Ȩ�����Ӱ��. ���ս������:
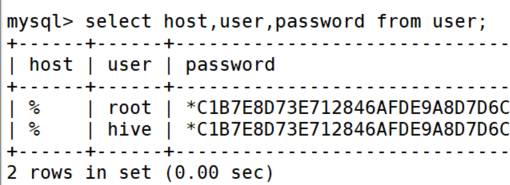
- �����û������ݿ�
CREATE USER 'hive'@'%' IDENTIFIED BY '77123';
CREATE DATABASE hive_meta;
- ��Ȩhive�û�
grant all privileges on hive_meta.* to hive@"%" identified by '77123';
��Ȼhive�û���hive_meta���ݿ��в���Ȩ��, �����������ݿⲻ����, hive�û���û��Ȩ����������ݿ��, ��������ǰ������hive_meta���ݿ�.
- ˢ��Ȩ��
flush privileges;
- ���ÿ���������
chkconfig mysqld on
- ����mysql������
ʹ��mysql�ķ�ʽ, �轫mysql������jar������Hive��libĿ¼��, �������������ʹ��java����mysql��������һ��.
��client�ڵ��ϰ�װHive
���ִ��ʽ�����, ֻ���ڸ������hive-site.xml�������ļ���.
��hive-site�ļ�:
vim /opt/software/hive/apache-hive-1.2.1/conf/hive-site.xml
����ɾ��<configuration> </configuration>��ǩ���е�����Ȼ�������������
<configuration>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive_localmysql/warehouse</value>
</property>
<property>
<name>hive.metastore.local</name>
<value>true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost/hive_meta</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>77123</value>
</property>
</configuration>
����
�����ͳ��ֵ�������Derbyģʽͬ��, �˴�������.
������һ����֮��, ��mysql��hive_meta���ݿ���, �и�TBLS��, ͨ��select * from TBLS ���Կ�����Hive�д����ı���������Ϣ(��Ԫ����).
ͬʱ, ����mysql��������û�ͬʱ����Hive����.
(��)����MySQL��Զ��(Remote)ģʽ(����ģʽ)
ԭ��
�ڴ֮ǰ, ���������˽�һ�»���MySQLԶ��ģʽ��ԭ��.

client�ڵ��ϵ�Hive�����ṩԪ���ݴ洢����. �����÷����, client�ڵ������һ��RunJar����, ������̶����ṩԪ���ݷ���.
�������ڵ�(����node01)��, ��ѹһ��Hive����, ͨ������hive-site.xml�ļ�, ʹ��node01�ڵ��Hive�����ܹ����ӵ�client�ڵ��ṩ��Ԫ���ݷ���.
����ģʽ�����ŵ����� �C ����. ��Ӧ��ͼ��˵, node01�ڵ㲻��Ҫ�ٰ�װmysql���ݿ�, ��������������ڵ�(����node02)��Ҫʹ��Hive����, ֻҪ��ѹ��һ���þͿ��Բ���ͬһ�����е�����(��Ϊ����ʹ��ͬһ��mysql), �Ӷ����⼯Ⱥ���ݵĸ�������.
��client�ڵ㰲װmysql
���ַ�ʽ����Ҳ����Ҫ��client�ڵ㰲װmysql���ݿ�, �������̴˴��Ͳ�����, ���ڶ���ģʽ��˵��������һ��.
��client�ڵ�����Hive����(�����)
����˴��mysql�ı���ģʽһ��.
��hive-site�ļ�:
vim /opt/software/hive/apache-hive-1.2.1/conf/hive-site.xml
������
<configuration>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive_meta/warehouse</value>
</property>
<property>
<name>hive.metastore.local</name>
<value>true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.75.137/hive_meta</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>77123</value>
</property>
</configuration>
��node01�ڵ�����Hive����(�ͻ���)
node01�ڵ���Ҳ��Ҫ��ѹһ��Hive�İ�װ��, �˴�ʡ��.
��hive-site�ļ�:
vim /opt/software/hive/apache-hive-1.2.1/conf/hive-site.xml
������, ʮ�ּ�
<configuration>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.metastore.local</name>
<value>false</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://192.168.75.137:9083</value>
</property>
</configuration>
ʹ��Hive������
Hive������������
vim ~/.bashrc
���ļ�������:
export HIVE_HOME=/opt/software/hive/apache-hive-1.2.1-bin
export PATH=$PATH:$HIVE_HOME/bin
���ļ���Ч
source ~/.bashrc
Hive����
- ���ֱ���ģʽ����Hive
hive
- ����mysql��Զ��ģʽ
Hive�����, ��������
hive --service metastore >>/opt/software/hive/log/meta.log 2>&1 &
Hive�ͻ���, ���ӷ���
hive
�������ִ��ʽ, ������Hive֮ǰ, Ӧ������HDFS��Yarn.����Hive�ᱨjava.lang.IncompatibleClassChangeError�Ĵ�, ��Ҫ���ǽ��(����ǰ汾���¿��ܲ��������������). ���������˲鿴
- ����ʹ��Hive:
������:
create table t1(id Int,name String);
��������:
insert into t1 values(1,'qb');
������������, ������MR����
��ѯ��:
select * from t1;
��������MR����, ֱ��ȥHDFS�ж��ļ�
��Ҫע��:
- ��select * �IJ�ѯSQL����������MR�����, ֻ�е�SQL����д���where, count, sum��ʱ�Ż�����MR����;
- insert������������MR����, �����ֲ����������ݲ��ʺ�Hiveʹ��, ��dz��ķ�ʱ��, ͨ��ʹ��load. insert���Ҫ����!