��Ȩ����������Ϊ����ԭ�����£�δ��������������ת�ء� https://blog.csdn.net/mll
java1111/article/details/51893841
1.1���Hbase����״��
1.1.1����ϵͳ
1.1.1.1IO
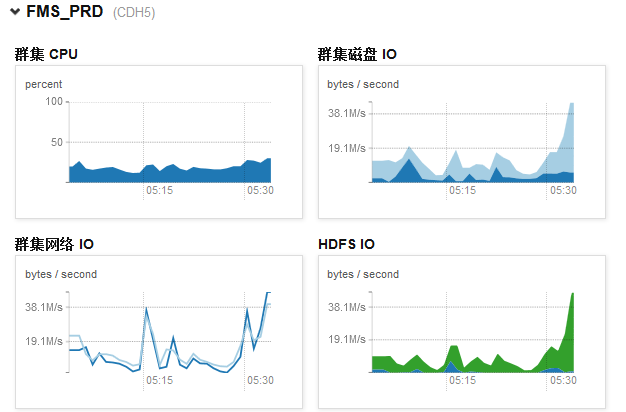
a.Ⱥ������IO������IO��HDFS IO
IOԽ��˵���ļ���д����Խ�ࡣ��IOͻȻ����ʱ���п��ܣ�1.compact���нϴ�Ⱥ���ڽ��д���ѹ��������
2.����ִ��mapreduce��ҵ
����ͨ��CDHǰ̨�鿴������Ⱥ�ۺϵ����ݻ����ָ��������ǰ̨�鿴��̨���������ݣ�
b.Io wait
����IO�Լ�Ⱥ��Ӱ��Ƚϴ����io waitʱ���������ϵͳ������Ƿ����쳣��ͨ��IO����ʱio waitҲ�����ӣ�����FMS�Ļ����������io wait��50ms����
��������ص�ָ�������CDHǰ̨���Ͻ��ȵ㡰������ѡ�Ȼ��ѡҪ�鿴��������
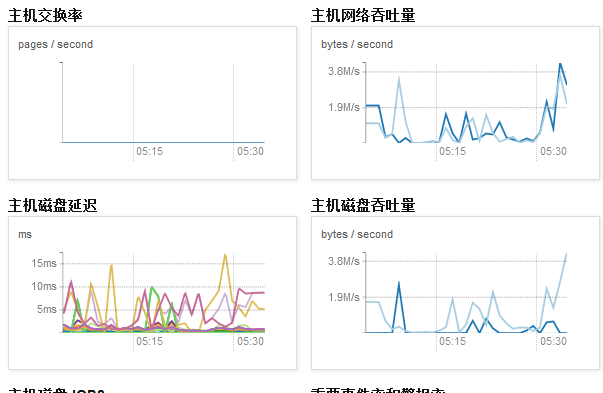
1.1.1.2CPU
���CPUռ�ù����п������쳣�������Ⱥ��Դ���ģ�����ͨ������ָ�����־���鿴��Ⱥ������ʲô��
1.1.1.3�ڴ�
1.1.2 JAVA
GC ���
regionserver��ʱ��GC��Ӱ�켯Ⱥ���ܲ����п��ܻ���ɼ��������
1.1.3��Ҫ��hbaseָ��
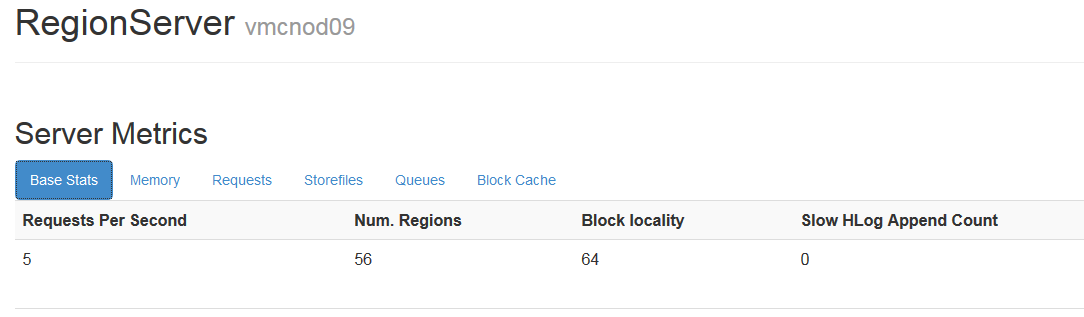
1.1.3.1region���
��Ҫ���
1.region��������������ÿ̨regionserver�ϵ�region����
2.region�Ĵ�С
��������쳣����ͨ���ֶ�merge region���ֶ�����region������
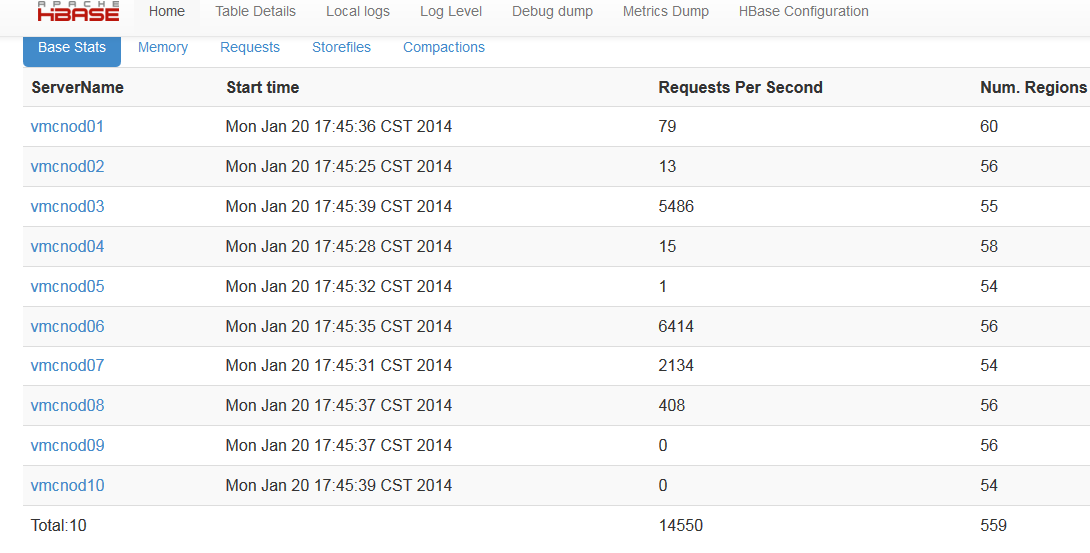
��CDHǰ̨��masterǰ̨�Լ�regionServer��ǰ̨�����Կ���region��������masterǰ̨��
��region serverǰ̨���Կ���storeFile��С��
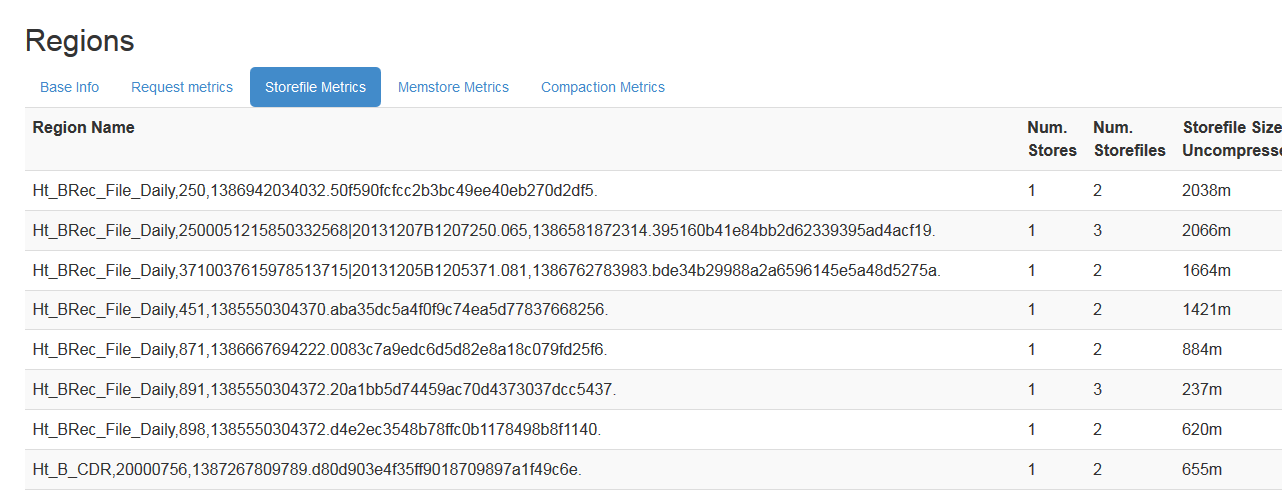
1.1.3.2����������
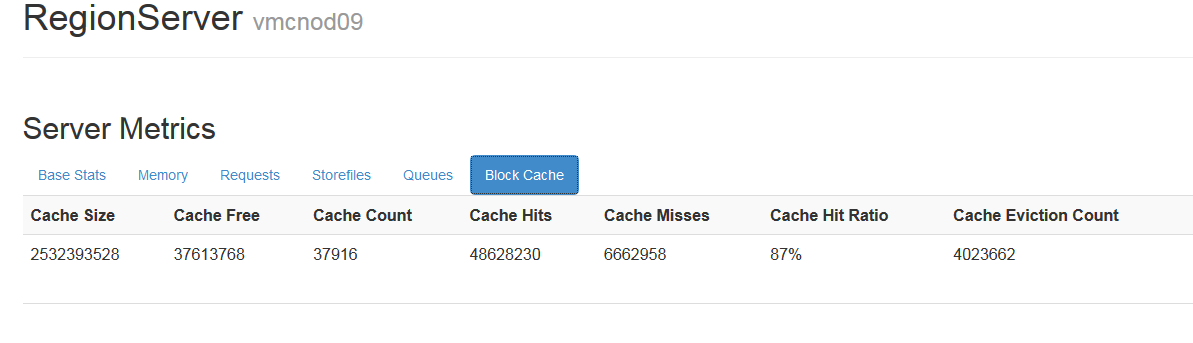
���������ʶ�hbase�Ķ��кܴ��Ӱ�죬���Թ۲����ָ��������blockcache�Ĵ�С��
��regionserver webҳ����Կ���block cache�������
1.1.3.3�������
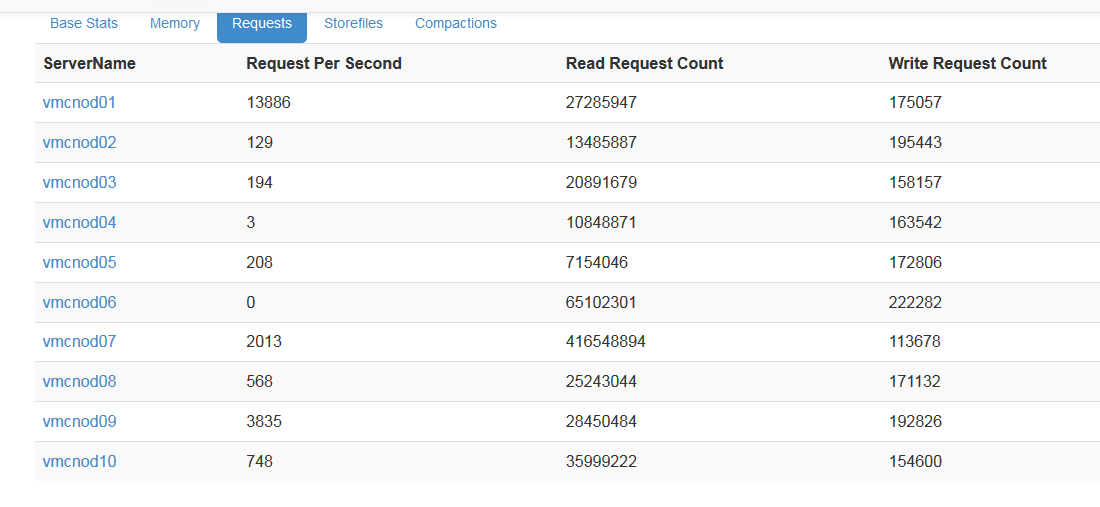
ͨ����д���������Դ�ſ���ÿ̨regionServer��ѹ�������ѹ���ֲ������ȣ�Ӧ�ü��regionServer�ϵ�region�Լ�����ָ��
master web�Ͽ��Կ�������regionServer�Ķ�д������
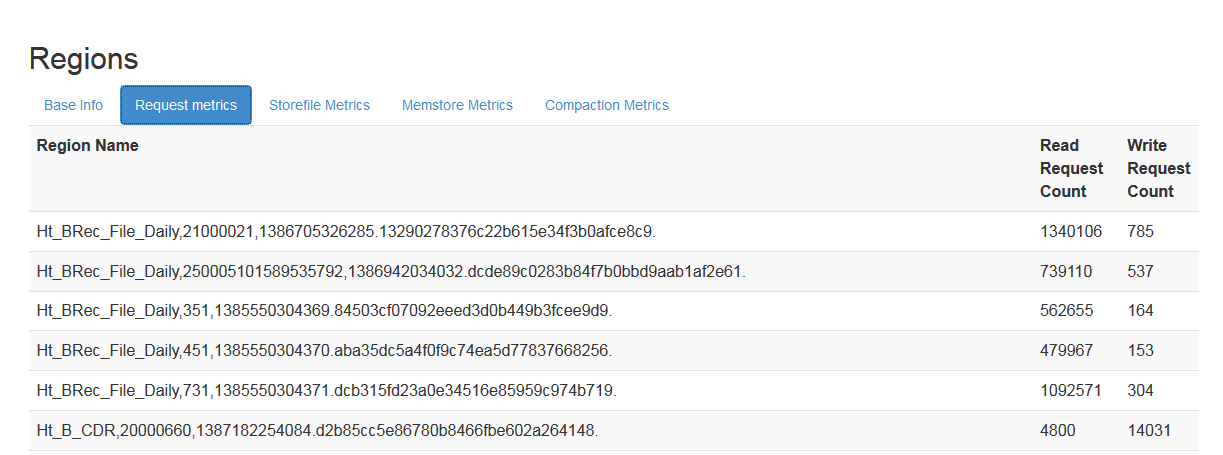
regionServer�Ͽ��Կ���ÿ��region�Ķ�д������
1.1.3.4ѹ������
ѹ�����д�ŵ�������ѹ����storefile��compact������hbase�Ķ�дӰ��ϴ�
ͨ��cdh��hbaseͼ������Կ�����Ⱥ�ܵ�ѹ�����д�С��
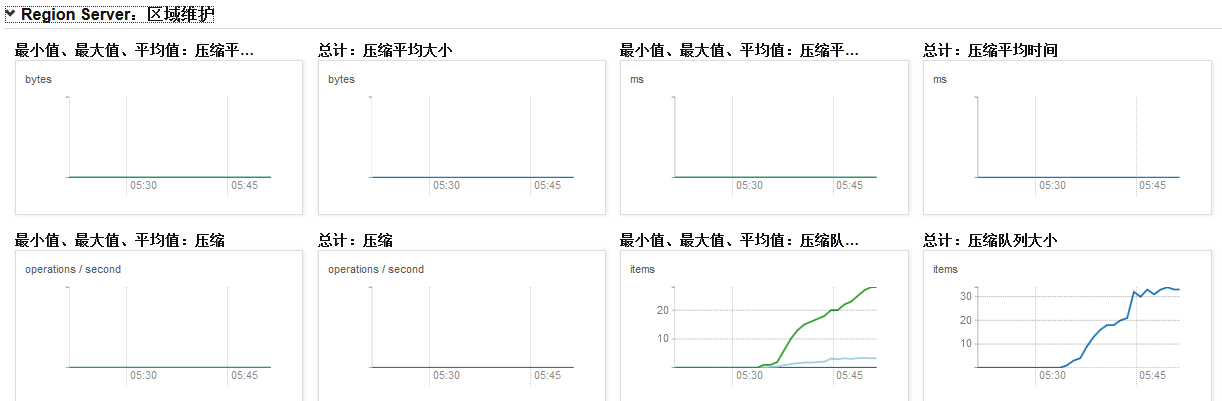
����ͨ��CDH��hbase��ҳ��ѯcompact��־��
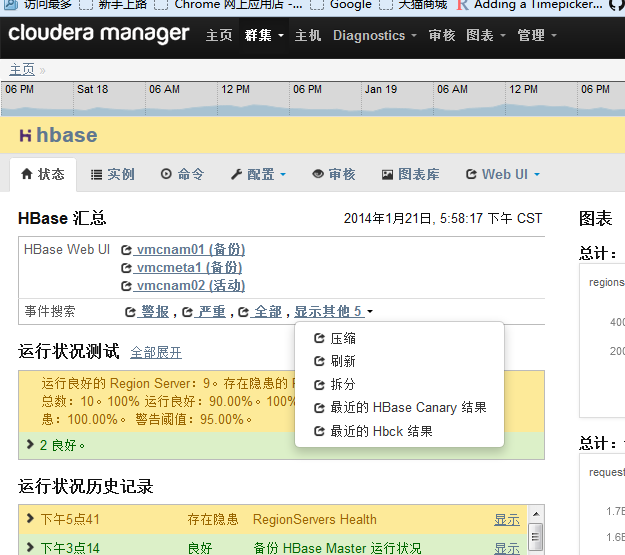
�����ѹ�������룺
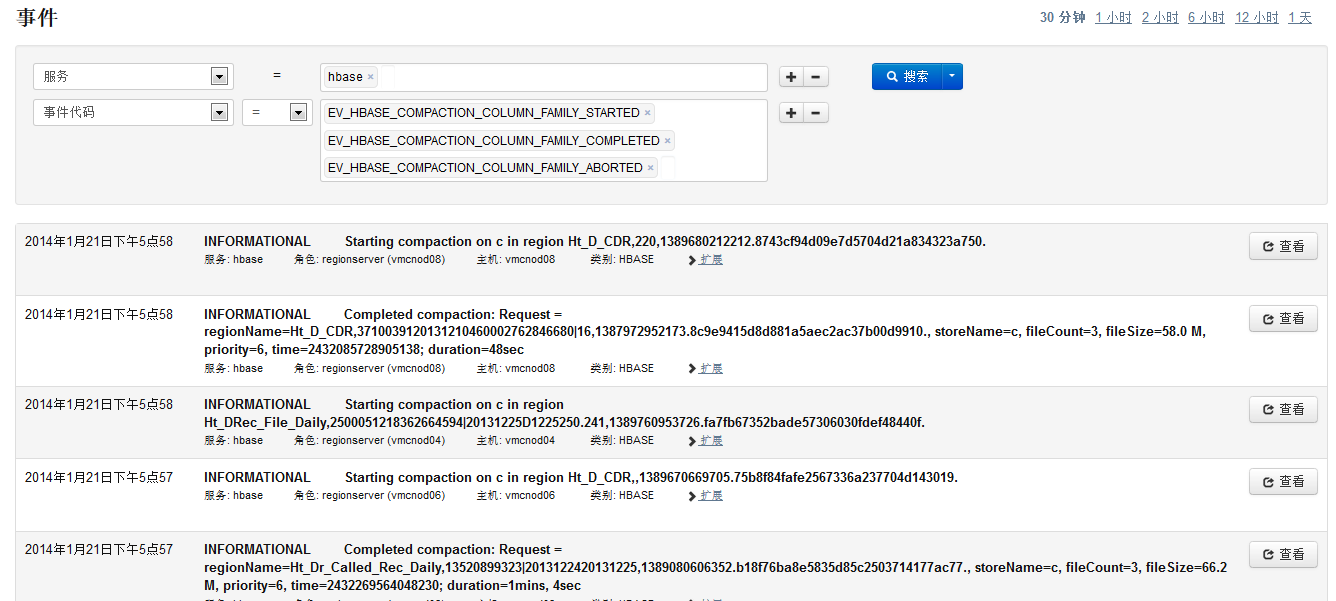
1.1.3.5ˢ�¶���
����region��memstoreд��(128M)��regionServer������region��memstore��С�ܺϴﵽ����ʱ�����flush����,flush����������µ�storeFile
ͬ������ͨ��CDH��hbaseǰ̨�鿴flush��־��
1.1.3.6rpc���ö���
û�м�ʱ������rpc���������rpc�������У���rpc���п��Կ���������������������
1.1.3.7�ļ��鱣���ڱ��صİٷֱ�
datanode��regionserverһ�㶼������ͬһ̨�����ϣ�����region server������region�����ȴ洢�ڱ��أ��Խ�ʡ���翪�������block locality�ϵ��п����Ǹ�����balance�������������compact֮��region�����ݶ���д����ǰ������datanode��block localityҲ�������ﵽ�ӽ�100��
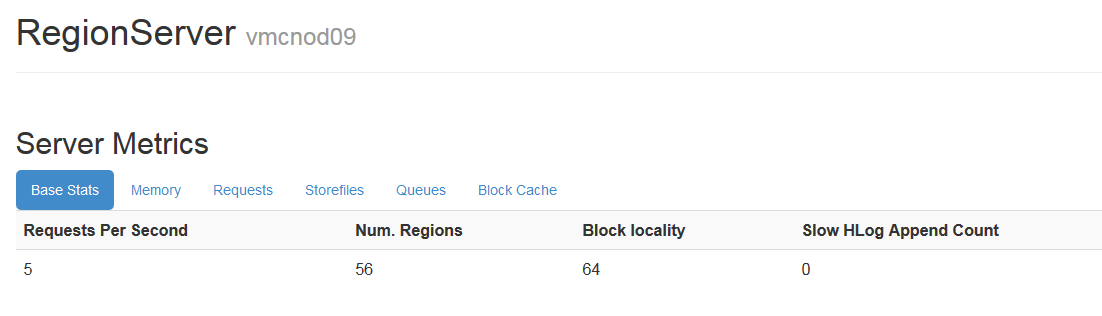
1.1.3.8�ڴ�ʹ�����
�ڴ�ʹ�����,��Ҫ���Կ�used Heap��memstore�Ĵ�С�����usedHeadpһֱ����80-85%�����DZȽ�Σ�յ�
memstore��С��ܴ�Ҳ������
��region Server��ǰ̨���Կ�����
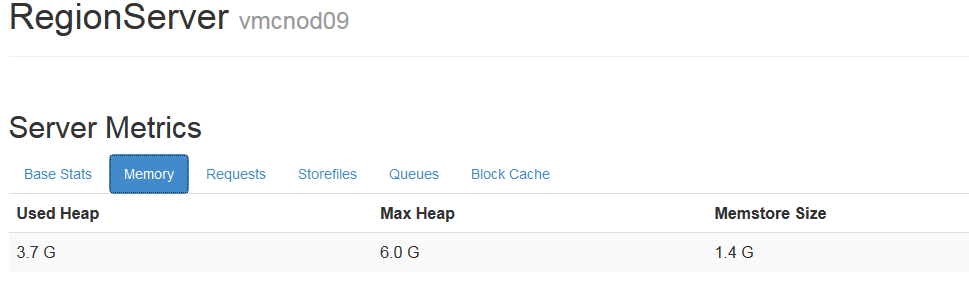
1.1.3.9slowHLogAppendCount
дHLog������>1s���IJ������������ָ�������ΪHDFS״̬�û����ж�
��region Serverǰ̨�鿴��
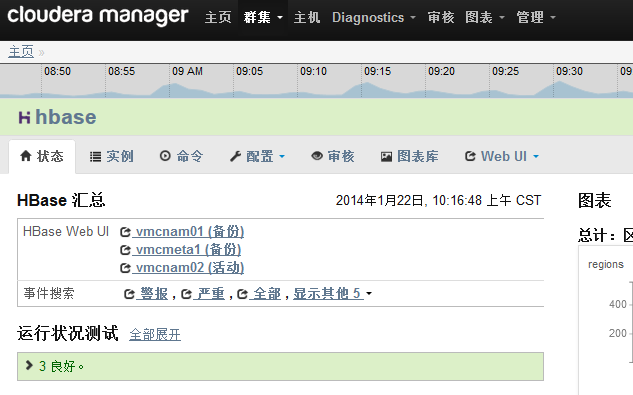
1.1.4CDH�����־
CDH��ǿ���ϵͳ�¼�����־�������ܣ�ÿһ������(�磺hadoop,hbase)����ҳ���ṩ���¼��澯�IJ�ѯ���ճ���ά����CDH��ҳ�ĸ澯�⣬��Ҫ�鿴��Щ�¼��Է���DZ�ڵ����⣺
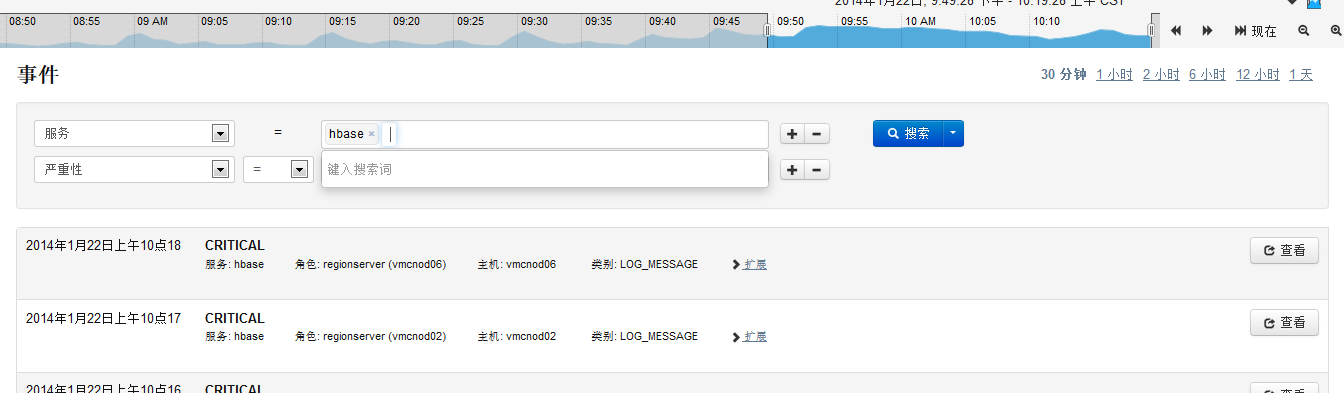
ѡ���¼��������еı�ǩ�����������������ء������Խ�����ص��¼���־���硰���ء���
1.2�������һ�����Լ�������
����һ������ָ��
1.ÿ��region������ȷ�ķ��䵽һ̨regionserver�ϣ�����region��λ����Ϣ��״̬������ȷ�ġ�
2.ÿ��table���������ģ�ÿһ�����ܵ�rowkey �����Զ�Ӧ��Ψһ��һ��region.
1.2.1���
hbase hbck
ע����ʱ��Ⱥ����������region������split��������������ݲ�һ��
hbase hbck -details
���ϨCdetails���г�����ϸ�ļ����Ϣ�������������ڽ��е�split����
hbase hbck Table1 Table2
���ֻ����ָ���ı������������������ϱ������������Խ�ʡ����ʱ��
CDH
ͨ��CDH�ṩ�ļ�鱨��Ҳ���Կ���hbck�Ľ�����ճ�ֻ��Ҫ��CDH hbck�ı��漴�ɣ�
ѡ�������Hbck�������
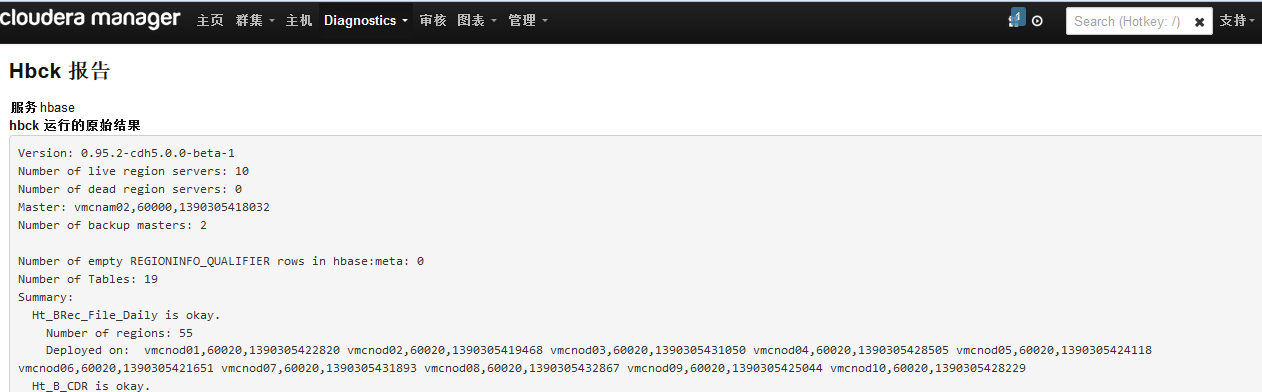
1.2.2��
1.2.2.1�ֲ�����
����������ݲ�һ�£���ʱҪ����ȵĽ��Ϳ��ܳ��ֵķ��գ�ʹ�����������region���������սϵͣ�
1.2.2.1.1hbase hbck -fixAssignments
��regionû�з���(unassigned)��������䣨incorrectly assigned���Լ���η��䣨multiply assigned��������
1.2.2.1.2hbase hbck -fixMeta
ɾ��META�����м�¼��HDFS��û�����ݼ�¼��region
����HDFS�������ݵ���META����û�м�¼��region��META��
1.2.2.1.3hbase hbck -repairHoles
�ȼ��ڣ�hbase hbck -fixAssignments -fixMeta -fixHdfsHoles
-fixHdfsHoles�����ã�
���rowkey���ֿն��������ڵ�����region��rowkey����������ʹ�������������HDFS���洴��һ���µ�region�������µ�region֮��Ҫʹ��-fixMeta��-fixAssignments������ʹ�ù������region������һ���ǰ��������һ��ʹ��
1.2.2.2Region�ص���
�������²����dz�Σ�գ���Ϊ��Щ���������ļ�ϵͳ����Ҫ����������
�������²���ǰ��ʹ��hbck �Cdetails�鿴��ϸ���⣬�����Ҫ��������ͣ��Ӧ�ã����ִ����������ʱͬʱ�����ݲ������ܻ���ɲ����ڵ��쳣��
1.2.2.2.1hbase hbck -fixHdfsOrphans
���ļ�ϵͳ�е�û��metadata�ļ�(.regioninfo)��regionĿ¼���뵽hbase�У�������.regioninfoĿ¼����region���䵽regionser
1.2.2.2.2hbase hbck -fixHdfsOverlaps
ͨ�����ַ�ʽ���Խ�rowkey���ص���region�ϲ���
1.merge:���ص���region�ϲ���һ�����region
2.sideline:��region�ص��IJ���ȥ���������ص���������д�뵽��ʱ�ļ���Ȼ���ٵ��������
����ص������ݺܴ�ֱ�Ӻϲ���һ�����region�����������split��compact����������ͨ�����²�������region����
-maxMerge �ϲ��ص�region���������
-sidelineBigOverlaps �����д���maxMerge������ region�ص�, �����sideline��ʽ����������region���ص�.
-maxOverlapsToSideline �����sideline��ʽ�����ص�region,���sideline n��region .
1.2.2.2.3hbase hbck -repair
������������
hbase hbck -fixAssignments -fixMeta -fixHdfsHoles -fixHdfsOrphans -fixHdfsOverlaps -fixVersionFile �CsidelineBigOverlaps
����ָ��������
hbase hbck -repair Table1 Table2
1.2.2.2.4hbase hbck -fixMetaOnly �CfixAssignments
���ֻ��META����region��һ�£������ʹ�����������
1.2.2.2.5hbase hbck �CfixVersionFile
Hbase�������ļ�����ʱ��Ҫһ��version file���������ļ���ʧ������������������½�һ��������Ҫ��֤hbck�İ汾��Hbase��Ⱥ�İ汾��һ����
1.2.2.2.6hbase org.apache.hadoop.hbase.util.hbck.OfflineMetaRepair
���ROOT����META������������Hbase����������������������������µ�ROOT��META����
��������ǰ����Hbase�Ѿ��رգ�ִ��ʱ�����hbase��homeĿ¼����hbase�������Ϣ��.regioninfo�������������Ϣ�������ľͻᴴ���µ�root��metaĿ¼������
1.2.2.2.7hbase hbck �CfixSplitParents
��region��split������ʱ��region�ᱻ�Զ��������������ʱ����region�ڸ�region�����֮ǰ������split�������Щ�ӳ����ߵĸ�region������META����HDFS�У�����û�в���HBASE�ֲ���������ǡ���������¿���ʹ�ô�����������Щ��META���е�regionΪ����״̬����û��split��Ȼ��Ϳ���ʹ��֮ǰ������������region��
1.3�ֶ�merge region
���в���ǰ�Ƚ�balancer�رգ�������ɺ��ٴ�balancer
����һ��ʱ�������֮���п��ܻ����һЩ��С��region����Ҫ���ڼ����Щregion�������Ǻ����ڵ�region�ϲ��Լ���ϵͳ����region�������ٹ�������
�ϲ�������
1.�ҵ���Ҫ�ϲ���region��encoded name
2.����hbase shell
3.ִ��merge_region ��region1��,��region2��
1.4�ֶ�����region
�������̨regionServer��Դռ���ر�ߣ����Լ����̨regionserver�ϵ�region�Ƿ���ڹ���Ƚϴ��region,ͨ��hbase shell�����ֱȽϴ��region������������Ǻ�æ��regions server��
move ��regionId��,��serverName��
����
move ��54fca23d09a595bd3496cd0c9d6cae85��,��vmcnod05,60020,1390211132297��
1.5�ֶ�major_compact
���в���ǰ�Ƚ�balancer�رգ�������ɺ��ٴ�balancer
ѡ��һ��ϵͳ�ȽϿ��е�ʱ���ֹ�major_compact�����hbase���²���̫Ƶ��������һ�����ڶ����б���һ�� major_compact���������������һ��major_compact�ۿ����е�storefile���������storefile�������ӵ� major_compact���storefile�Ľ�����ʱ�����Զ����б���һ��major_compact��ʱ��Ƚϳ���������������߷���
ע��fms���������Ͽ������Զ�major_compact������Ҫ���ֶ�major compact
1.6balance_switch
balance_switch true ��balancer
balance_switch flase �ر�balancer
����master�Ƿ�ִ��ƽ�����regionserver��region��������������Ҫά����������һ��regionserverʱ����ر�balancer��������ʹ��region��regionserver�ϵķֲ����������ʱ����Ҫ�ֹ��Ŀ���balance��
1.7regionserver����
graceful_stop.sh �Crestart �Creload �Cdebug nodename
���в���ǰ�Ƚ�balancer�رգ�������ɺ��ٴ�balancer
���������ƽ��������regionserver���̣��Է�����Ӱ�죬�����Ƚ���Ҫ������regionserver��������� regionǨ�Ƶ������ķ�������Ȼ������������ֻὫ֮ǰ��regionǨ�ƻ�������������һ������ʱ�����������ַ�ʽ����ÿһ̨���ӣ�����hbase regionserver��������Ҫֱ��kill���̣������������zookeeper.session.timeout���ʱ�䳤���жϣ�Ҳ��Ҫͨ�� bin/hbase-daemon.sh stop regionserverȥ���������������̫�ã�-ROOT-����.META.��������Ļ������е������ȫ��ʧ��
1.8regionserver�ر�����
bin/graceful_stop.sh nodename
���в���ǰ�Ƚ�balancer�رգ�������ɺ��ٴ�balancer
������һ����ϵͳ���ڹر�֮ǰǨ������region��Ȼ��stop���̡�
1.9flush��
����memstoreˢ�µ�hdfs��ͨ���������regionserver���ڴ�ʹ�ù�����ɸû��� regionserver�ܶ��߳�block������ִ��һ��flush������������������hbase��storefile����������Ӧ������������� ��������һ���������hbase����Ǩ�Ƶ�ʱ�����ѡ���ļ���ʽ��������ͣд�룬Ȼ��flush���б��������ļ�
1.10HbaseǨ��
1.10.1copytable��ʽ
bin/hbase org.apache.hadoop.hbase.mapreduce.CopyTable �Cpeer.adr=zookeeper1,zookeeper2,zookeeper3:/hbase ��testtable��
���������Ҫ����hbaseĿ¼���conf/mapred-site.xml�����Ը���hadoop�Ĺ�����
1.10.2Export/Import
bin/hbase org.apache.hadoop.hbase.mapreduce.Export testtable /user/testtable [versions] [starttime] [stoptime]
bin/hbase org.apache.hadoop.hbase.mapreduce.Import testtable /user/testtable
1.10.3ֱ�ӿ���hdfs��Ӧ���ļ�
���ȿ���hdfs�ļ�����bin/hadoop distcp hdfs://srcnamenode:9000/hbase/testtable/ hdfs://distnamenode:9000/hbase/testtable/
Ȼ����Ŀ��hbase��ִ��bin/hbase org.jruby.Main bin/add_table.rb /hbase/testtable
����meta��Ϣ������hbase
2Hadoop�ճ���ά
2.1���Hadoop����״��
1.nameNode��ResourseManager�ڴ�(namenodeҪ���㹻�ڴ�)
2.DataNode��NodeManager����״̬
3.����ʹ�����
4.����������״̬
2.2���HDFS�ļ�����״��
���hadoop fsck
2.3����������(trash)����
trash������Ĭ���ǹرյģ���������ɾ�������ݽ���mv�������û�Ŀ¼�ġ�.Trash���ļ��У��������ó����ʱ�䣬ϵͳ�Զ�ɾ���������ݡ�����һ����������ʧ���ʱ��������mv����
3����Ŀ�����µ�hbase��������
