��ƪ����dz�ԵĴӼ�������̸̸HBase��һЩ�Ż����ɣ�ֻ����Ϊ��ѧϰ�ʼǵ�һ���֣���Ϊѧ���������������Լ��Ժ���
1 �� linux ϵͳ����
Linuxϵͳ���ɴ��ļ���һ��Ĭ�ϵIJ���ֵ��1024,����㲻�����IJ�����������ʱ�����֡�Too Many Open Files���Ĵ���������HBase�������У��������ulimit -n ��������ģ�������/etc/security/limits.conf ��/proc/sys/fs/file-max �IJ�������������Ŀ���ȥGoogle �ؼ��� ��linux limits.conf ��
2 JVM ����
�� hbase-env.sh �ļ��е����ò�����������Ļ���Ӳ���͵�ǰ����ϵͳ��JVM(32/64λ)�����ʵ��IJ���
HBASE_HEAPSIZE 4000 HBaseʹ�õ� JVM �ѵĴ�С
HBASE_OPTS "�\server �\XX:+UseConcMarkSweepGC"JVM GC ѡ��
HBASE_MANAGES_ZKfalse �Ƿ�ʹ��Zookeeper���зֲ�ʽ����
3 HBase�־û�
��������ϵͳ��HBase������ȫ�ޣ�����Բ����κ��ĵ�����£�����һ�ű���дһ�����ݽ��У�Ȼ�������������������ٽ���HBase��shell��ʹ�� list ����鿴��ǰ�����ڵı���һ����û���ˡ��Dz��Ǻܱ��ߣ�û�й�ϵ�������hbase/conf/hbase-default.xml������hbase.rootdir��ֵ���������ļ��ı���λ��ָ��һ���ļ��� �����磺<value>file:///you/hbase-data/path</value>���㽨����HBase�еı������ݾ�ֱ��д������Ĵ����ϣ���ͼ��ʾ��
ͬ����Ҳ����ָ����ķֲ�ʽ�ļ�ϵͳHDFS��·������: hdfs://NAMENODE_SERVER:PORT/HBASE_ROOTDIR��������д������ķֲ�ʽ�ļ�ϵͳ���ˡ�
4 ����HBase�����
��ξ���Ҫ��hbase/conf/hbase-default.xml �ļ��������ã�����������Ϊ�Ƚ���Ҫ�����ò���
hbase.client.write.buffer
���������������������д�����ݻ������Ĵ�С�����ͻ��˺ͷ������˴������ݣ�������Ϊ�����ϵͳ�������ܿ���һ��д�Ļ��������������� �����������������õĴ��ˣ������ϵͳ���ڴ���һ����Ҫ��ֱ��Ӱ��ϵͳ�����ܡ�
hbase.master.meta.thread.rescanfrequency
�������ʱ�� HMaster��ϵͳ�� root �� meta ɨ��һ�Σ���������������õij�һЩ������ϵͳ���ܺġ�
hbase.regionserver.handler.count
����������HBase/Hadoop��Server�Dz���Multiplexed, non-blocking I/O��ʽ����Ƶģ�������������һ��Thread����ɴ������������ڴ���Client�������еķ�����Blocking I/O������������ƻὫClient�����ݹ���������ȷ�����Queue����������Serverʱ���Ȳ���һ��Handler(Thread)����Handler����Polling�ķ�ʽ��ȡ�ø������ִ�ж�Ӧ�ķ�����Ĭ��Ϊ25������ʵ�ʳ����������ô�һЩ��
hbase.regionserver.thread.splitcompactcheckfrequency
��������������DZ�ʾ���ȥRegionServer����������һ��split/compaction��ʱ��������Ȼsplit֮ǰ���Ƚ���һ��compact����.���compact����������minor compactҲ������major compact.compact��,������е�Store�µ�����StoreFile�ļ������Ǹ�ȡmidkey.���midkey���ܲ�������ȫ�����ݵ�mid��.һ��row-key����������ݿ��ܻ�粻ͬ��HRegion��
hbase.hregion.max.filesize
������HRegion�е�HStoreFile���ֵ���κα��е�����һ�����������С���ᱻ�з֣���HStroeFile��Ĭ�ϴ�С��256M��
hfile.block.cache.size
������ָ�� HFile/StoreFile ������JVM���з���İٷֱȣ�Ĭ��ֵ��0.2����˼����20%������������ó�0���ͱ�ʾ�Ը�ѡ�����Ρ�
hbase.zookeeper.property.maxClientCnxns
������ �������õ�ѡ����Ǵ�zookeeper�����ģ���ʾZooKeeper�ͻ���ͬʱ���ʵIJ�����������ZooKeeper����HBase��˵����һ��������������ֵ�����ʵ��Ŵ�Щ��
hbase.regionserver.global.memstore.upperLimit
��������Region Server������memstoresռ�öѵĴ�С�������ã�Ĭ��ֵ��0.4����ʾ40%���������Ϊ0�����Ƕ�ѡ��������Ρ�
hbase.hregion.memstore.flush.size
������Memstore�л�������ݳ������õķ�Χ��д�������ϣ����磺ɾ����������д��MemStore��������ǣ�ָʾ�Ǹ�value, column �� family������Ҫɾ���ģ�HBase�ᶨ�ڶԴ洢�ļ���һ��major compaction������ʱHBase���MemStoreˢ��һ���µ�HFile�洢�ļ��С������һ��ʱ�䷶Χ��û����major compaction����Memstore�г����ķ�Χ��д��������ˡ�
5 HBase��log4j����־
HBase����־����ȼ�Ĭ��״̬���ǰ�debug�� info �������־�ģ����Ը����Լ�����Ҫ����log����HBase��log4j��־�����ļ��� hbase\conf\log4j.properties Ŀ¼�¡�
4�C�洢
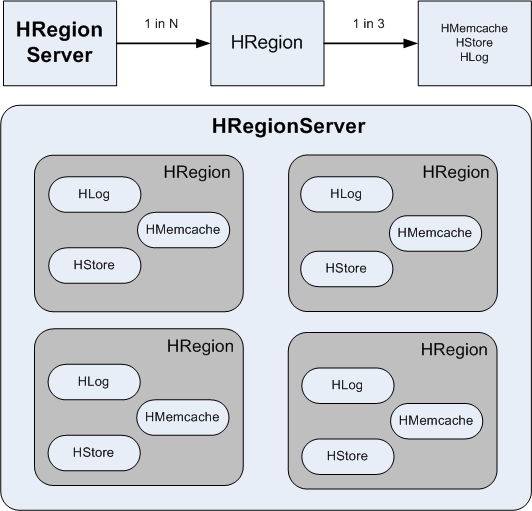
��HBase�д�����һ�ű����Էֲ��ڶ��Hregion��Ҳ��˵һ�ű����Ա���ֳɶ�飬ÿһ������Ǻ�Ϊһ��Hregion��ÿ��Hregion�ᱣ ��һ��������ij�����������ݣ��û��������Ǹ�����е�ÿ��Hregion������Hregion�������ṩά��������Hregion����Ҫͨ�� Hregion����������һ��Hregion���Ӧһ��Hregion��������һ�������ı����Ա����ڶ��Hregion �ϡ�HRegion Server ��Region�Ķ�Ӧ��ϵ��һ�Զ�Ĺ�ϵ��ÿһ��HRegion�������ϻᱻ��Ϊ�������֣�Hmemcache(����)��Hlog(��־)��HStore(�־ò�)��
������Щ��ϵ�����Ժ��е����ӣ���ͼ��ʾ��
1.HRegionServer��HRegion��Hmemcache��Hlog��HStore֮��Ĺ�ϵ����ͼ��ʾ��
2.HBase���е�������HRegionServer�ķֲ���ϵ����ͼ��ʾ��
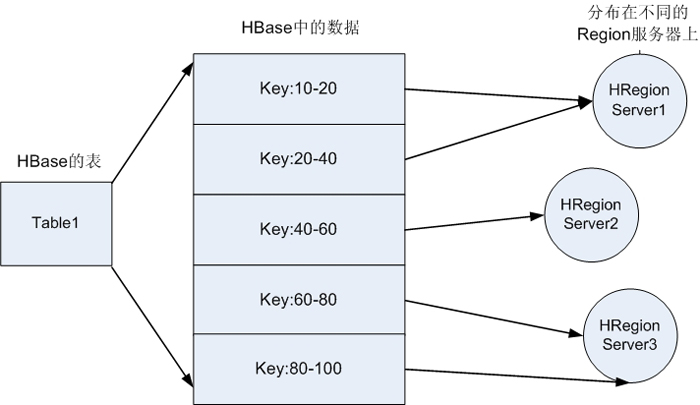
HBase������
HBase��ȡ�������ȶ�ȡHMemcache�е����ݣ����δȡ����ȥ��ȡHstore�е����ݣ�������ݶ�ȡ�����ܡ�
HBase���
HBaseд�����ݻ�д��HMemcache��Hlog�У�HMemcache�������棬Hlogͬ��Hmemcache��Hstore��������־������Flush Cacheʱ�����ݳ־û���Hstore�У������HMemecache��
�ͻ��˷�����Щ���ݵ�ʱ��ͨ��Hmaster ��ÿ�� Hregion �����������Hmaster ����������һ�������ӣ�Hmaster ��HBase�ֲ�ʽϵͳ�еĹ����ߣ�������Ҫ�������Ҫ����ÿ��Hregion ��������Ҫά����ЩHregion���û�����Щ�����ݿ��Ա�����Hadoop �ֲ�ʽ�ļ�ϵͳ�ϡ� �����������Hmaster��������ô����ϵͳ������Ч�������һῼ����ν��Hmaster��SPFO�����⣬��������е�����Hadoop��SPFO ����һ��ֻ��һ��NameNodeά��ȫ�ֵ�DataNode��HDFSһ������ȫ�����ˣ�Ҳ����˵����Heartbeat�����������⣬���������ҳ�
�����Ľ�����������ʱ�䣬���а취�ġ�
������hadoop-0.21.0��hbase-0.20.6�Ļ����������˺ܾã�һֱ������������Ϣ���£�
Exception in thread "main" java.io.IOException: Call to localhost/serv6:9000 failed on local exception:
java.io.EOFException
10/11/10 15:34:34 ERROR master.HMaster: Can not start master
java.lang.reflect.InvocationTargetException
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:39)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:27)
at java.lang.reflect.Constructor.newInstance(Constructor.java:513)
at org.apache.hadoop.hbase.master.HMaster.doMain(HMaster.java:1233)
at org.apache.hadoop.hbase.master.HMaster.main(HMaster.java:1274)
|
�������Ӳ���HDFS��Ҳ������HMaster�����ư���
�����밡�������룬����ǰһ�� java.io.EOFException ����쳣���Dz����п�����RPC Э����ʽ��һ�µ��µģ�Ҳ����˵�������˺Ϳͻ��˵İ汾��һ�µ����⣿����һ��HDFS�ķ��������Ժ�һ�ж����ˣ���Ȼ�ǰ汾�����⣬������ hadoop-0.20.2 ����hbase-0.20.6 �Ƚ��ȵ���
����Ч����ͼ��ʾ��
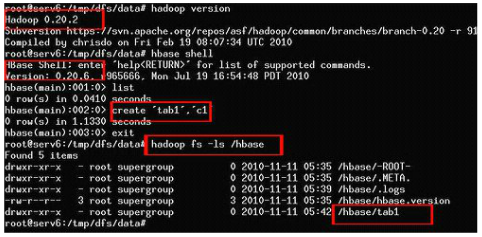
��ͼ��һЩ����˵����
- hadoop�汾��0.20.2 ,
- hbase�汾��0.20.6,
- ��hbase�д�����һ�ű� tab1���˳�hbase shell����,
- ��hadoop����鿴���ļ�ϵͳ�е��ļ���Ȼ����һ���ոմ�����tab1Ŀ¼,��������ͼƬ˵��HBase�ڷֲ�ʽ�ļ�ϵͳApache HDFS�������ˡ�
5(��Ⱥ) -ѹ��������ʧЧת��
����һƪ����HBase������������������HBase�ڷֲ�ʽ�еļܹ�����ƪ���½��ὲ��HBase�ڷֲ�ʽ������������ų�������ϵ�(SPFO)����һ��Сʵ�齲��HBase�ڷֲ�ʽ�����еĸ߿����ԣ����ۿ���һЩ��������һЩ˼���Ļ��⡣
�����ع�һ��HBase��Ҫ������
- HBaseMaster
- HRegionServer
- HBase Client
- HBase Thrift Server
- HBase REST Server
HBaseMaster
HMaster �����HRegionServer��������,���Ҹ���Լ�Ⱥ�����е�HReginServer���и��ؾ��⣬HMaster�������ؼ�Ⱥ�����е�HReginServer������״�������ijһ̨HReginServer down����HBaseMaster����Ѳ����õ�HReginServer���ṩ�����HLog�ͱ��������·���ת��������HReginServer���ṩ��HBaseMaster����������ݺͱ����й������������ṹ�ͱ������ݵı������Ϊ�� META ϵͳ���д洢�����е���ر���Ϣ������HMasterʵ����ZooKeeper��Watcher�ӿڿ��Ժ�zookeeper��Ⱥ������
HRegionServer
HReginServer�������û��Ķ���д�IJ�����HReginServerͨ����HBaseMasterͨ�Ż�ȡ�Լ���Ҫ��������ݱ�������HMaster�����Լ�������״������һ��д����������ʱ�������Ȼ�д��һ������HLog��write-ahead log�С�HLog���������ڴ��У���ΪMemcache��ÿһ��HStoreֻ����һ��Memcache����Memcache�������õĴ�С�Ժ��ᴴ��һ��MapFile������д��������ȥ���⽫����HReginServer���ڴ�ѹ������һ���ȡ����������ʱ��HReginServer������Memcache��Ѱ�Ҹ����ݣ����Ҳ�����ʱ�Ż�ȥ��MapFiles
��Ѱ�ҡ�
HBase Client
HBase Client����Ѱ���ṩ�������ݵ�HReginServer������������У�HBase Client��������HMasterͨ�ţ��ҵ�ROOT�������������Client��Master֮����е�ͨ�Ų�����һ��ROOT�����ҵ��Ժ�Client�Ϳ���ͨ��ɨ��ROOT�����ҵ���Ӧ��META����ȥ��λʵ���ṩ���ݵ�HReginServer������λ���ṩ���ݵ�HReginServer�Ժ�Client�Ϳ���ͨ�����HReginServer�ҵ���Ҫ�������ˡ���Щ��Ϣ���ᱻClient�������������´������ʱ�Ͳ���Ҫ���������������ˡ�
HBase����ӿ�
HBase Thrift Server��HBase REST Server��ͨ����Java�����HBase���з��ʵ�һ��;����
��������
������һ��HBase��Ⱥ��ģ������˻�����һ����4̨�������ֱ���� zookeeper��HBaseMaster��HReginServer��HDSF 4������Ϊ��չʾʧЧת����Ч��HBaseMaster��HReginServer����2̨��ֻ����һ̨�����ϼ�������HBaseMaster��Ҳ������HReginServer��
ע�⣬HBase�ļ�Ⱥ������HBaseMasterֻ��ʧЧת��û��ѹ�����صĹ��ܣ���HReginServer���ṩʧЧת��Ҳ�ṩѹ�����ء�
�������嵥���£�
- zookeeper 192.168.20.214
- HBaseMaster 192.168.20.213/192.168.20.215
- HReginServer 192.168.20.213/192.168.20.215
- HDSF 192.168.20.212
����ģ����ļܹ���ͼ��ʾ��
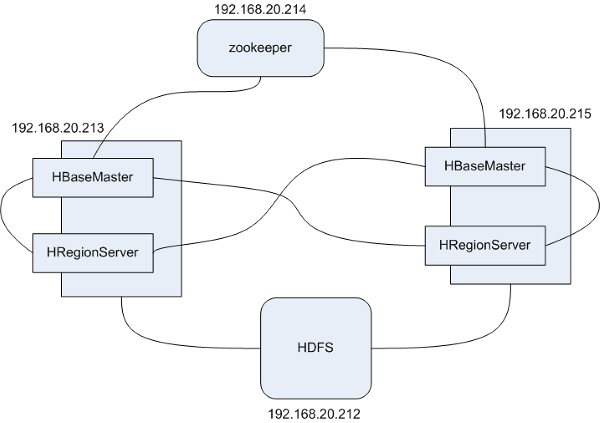
ע�⣬����ֻ������һ��ģ�������Ϊ����������ص���HBase������zookeeper��HDFS�����ǵ�̨��
��Ȼ˵������HBase�ļ�Ⱥ������ֻ����һ��HMaster�������ڼ�Ⱥ������HMaster�������������������ʹ�õ���HMaster Serverֻ��һ��������down����ʱ������������HMaster Server�����Ṥ����ֱ����ZooKeeper�������ж��뵱ǰ���е�HMasterͨѶ��ʱ����Ϊ����������е�HMaster������down���ˣ�Zookeeper�Ż�ȥ������һ̨HMaster Server��
����˵,���������HMaster������down���ˣ���ôzookeeper����б���ѡ����һ��HMaster ���������з��ʣ������ӹ�down����HMaster��������֮����Java�ͻ��˶�HBase���в�����ͨ��ZooKeeper�ģ�Ҳ����˵���zookeeper��Ⱥ�еĽڵ�ȫ���� ��ôHBase�ļ�ȺҲ���ˡ�����HBase�����洢�е��κ����� �����������DZ�����HDFS�ϣ�����HBase��������һ�µģ�����HDFS�ļ�ϵͳ���ˣ�HBase�ļ�ȺҲ�ҡ�
��һ̨HMasterʧ�ܺͻ��˶�HBase��Ⱥ��������ʱ���ͻ����Ȼ�ͨ��zookeeperʶ��HMaster�����쳣��ֱ��ȷ�϶�κ����ӵ���һ��HMaster����ʱ�����ݵ�HMaster�������Ч����IDE�����е�Ч������ͼ��ʾ��
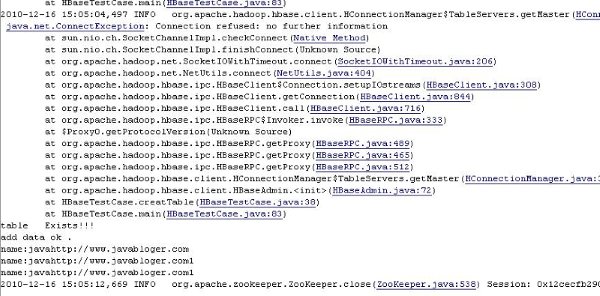
��ͼ���ܿ����׳���һЩ�쳣��name:javahttp://www.javabloger.com��name:javahttp://www.javabloger.com1�Ľ��������Ϊ����serv215��������killall java����� HMaster��HReginServer���ص�������������Java�ͻ��˶�HBase�ļ�Ⱥ�������з������쳣�׳�������retry��һ���������ѯ�������ǰ���Ѿ�˵�˷���HBase��ͨ��zookeeper�ٺ����������ݴ���Ҳ����˵zookeeper�ӹ���һ��standby
�� HMaster����ԭ��Standby��HMaster������ʧЧ��HMaster�������ӹܵ�HBaseMaster�ٶ�HReginServer��������з��䣬�� HReginServerʧ�ܺ�zookeeper��֪ͨ HMaster��HReginServer��������з��䡣������ֵ�˵����HBase������ʵЧת���Ĺ��ܡ�
��ͼ��ʾ��

��ˮ��
1��HBase��ʧЧת����Ч�ʱȽ����ˣ���ָ������1-2���л��ͻָ���ϣ�Ҳ��������ʱû�з�����ʲô�����������ʧЧת���ͻָ����̵��ٶȣ������������ע������⡣
2���ڹٷ���վ�Ͽ���HBase0.89.20100924�İ汾��ƪ������������ͬ�������£��ҳ�����һ����һ̨�����Ͽ���������ν��HBase���⼯Ⱥ�����������л�����̨�����ķֲ�ʽ�����У�����ʧЧת�����ٶȺ�����HBase0.20.6��Ҫ�������ּ�����Ƿ������������⣬Ŀǰ��δ�ҵ���ȷ�Ĵ𰸣�����HBase0.89.20100924 �°��е�����ͬ����ԭ������ͼ��ʾ��(������Ϣ)
ת�س�����http://blog.csdn.net/frankiewang008/article/details/41965543