һ������
HBase�����¼����ص㣺
- HBase�еĿ��Զ�̬���ӣ�������Ϊ�վͲ��洢����,��ʡ�洢�ռ�.
- hbase�Զ��з����ݣ�ʹ�����ݴ洢�Զ�����ˮƽscalability.
- Hbase�����ṩ�߲�����д������֧�֡�
- HBase����֧��������ѯ��ֻ֧�ְ���Row key����ѯ.
- ��ʱ����֧��Master server�Ĺ����л�,��Master崻���,�����洢ϵͳ�ͻ�ҵ�.
��ΪHBase����Щ�ص㣬������Mysql�ĵȹ�ϵ�����ݿ��Ӧ�ó��������������ȫ��ͬ����ͳ��ϵ�����ݿ�(mysql��oracle)���ݴ洢��ʽ��Ҫ���£�
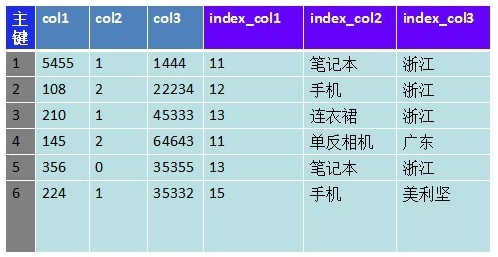
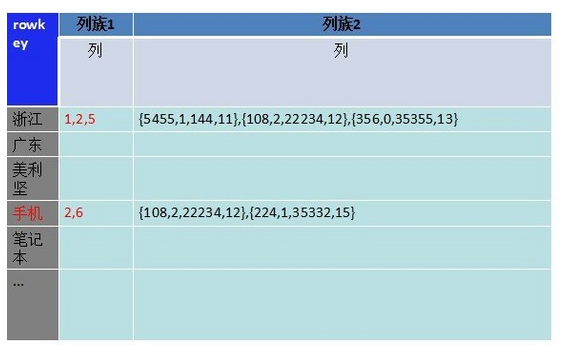
��ͼ�Ǹ��ܵ��͵����ݴ��淽ʽ���Ұ�ÿ����¼�ֳ�3����: ��������¼���ԡ������ֶ� �����ǻ�������ֶν����������ﵽ����������Ч����
��������ҵ��ķ�չ����ѯ����Խ��Խ���ӣ���Ҫ����������ֶΣ��Һܶ�ֵ�������ڣ�����ͼ��
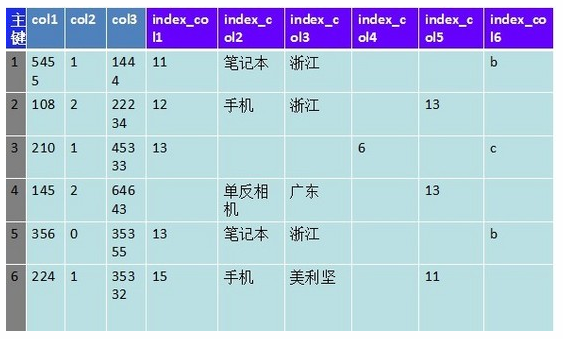
��ͼ��6�������ֶΣ� ʵ������������ϰٸ��������࣬���һ���Ҫ���ݶ�������ֶ�ˢѡ����ѯ����Խ��Խ�ͣ������������ѯҪ��ϵ��������ľ���Ҳ��ʼ���֣����Ǻܾͳ�����Nosql�ȷǹ�ϵ���ݿ⡣
HBase��Ϊһ���������ݿ��ǿ�ܶ��˾�������ݴ�mysqlǨ��hbase���洢�����ݻ��Ǹ���ͼһ����������ΪΪrowkey�����������ֶε����ݣ��洢һ�������µIJ�ͬ�С�������������ֶβ�ѯ��û�а취��Ŀǰ��û�бȽϺõĻ���bigtable�Ķ��������������������������ֶ�����ѯ����ʱ����ʵ����ת����˼ά���������ݵ�����������ͼ��
�Ѹ��������ֶε�ֵ��Ϊrowkey��Ȼ��Ѽ�¼������������ֵ����һ��˳����ڶ�Ӧrowkey��value���ͼֻ��һ�����壬����ķ�ʽ�� Value��ļ�¼�������óɶ�����byte[]�������¼����ͨ����λ���ٲ�ѯ����
��������ֻ�ʺϵ��������ֶεIJ�ѯ�����Ҫͬʱ�Զ�������ֶβ�ѯ�������ѯ���㽭��and���ֻ�������Ҫȡ������value���ٽ��������Ե������������ÿ����¼���������ϰٸ���������Ӱ��ܴ�
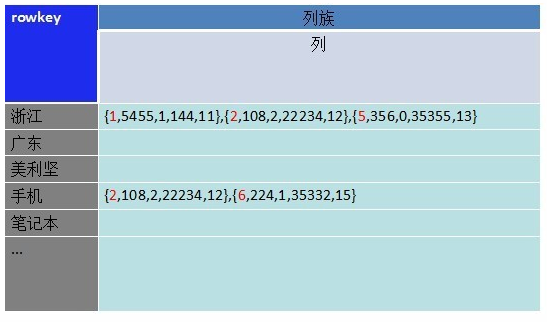
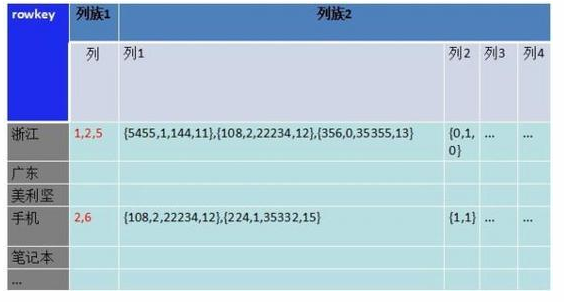
�������ĵ�������ǽ���������ֶβ�ѯ�����⡣���ǽ������ֶκ������ֶηֿ��洢 �������ڲ�ͬ�������£���������ѯֻ��Ҫȡ������1�µ����ݣ���ȥ��С���ϵ�����2��ȡ����Ҫ��ֵ����������ͼ��
Ϊʲô�Dz�ͬ���壬������һ�������µ������У�
�������ݿ������ļ��ǰ�������ֵġ���ȡ����ʱ�������һ����������������ݶ�ȡ��������ʵ�����Dz�����Ҫ�Ѽ�¼��ϸȡ�����������ⲿ�����ݷŵ�����һ�������¡�
�������Ƕ�����2��չ������2���������У�����������ˢѡ�����㴦��������ͼ��
����HBase��RDBMS������
1����������
Hbaseֻ�м��ַ����ͣ����е����Ͷ��ǽ����û��Լ���������ֻ�����ַ������û���Ҫ�Լ���������ת��������ϵ���ݿ��зḻ�����ͺʹ洢��ʽ��
2�����ݲ���
HBaseֻ�кܼIJ��롢��ѯ��ɾ������յȲ��������ͱ�֮���Ƿ���ģ�û�и��ӵı��ͱ�֮��Ĺ�ϵ������ͳ���ݿ�ͨ���и�ʽ�����ĺ��������Ӳ�����
3���洢ģʽ
HBase�ǻ����д洢�ģ�ÿ�����嶼�ɼ����ļ����棬��ͬ��������ļ�ʱ����ġ�����ͳ�Ĺ�ϵ�����ݿ��ǻ��ڱ���ṹ����ģʽ����� ��
4��������
HBase�ĸ��²�����Ӧ�ýи��£���ʵ�����Dz������µ�����ԭ���ľɰ汾��Ȼ�����ţ�����ͳ���ݿ����滻�ġ�
5����������
Hbase����ֲ�ʽ���ݿ����Ϊ�����Ŀ�Ķ����������ģ��������ܹ��������ӻ����Ӳ�������������ҶԴ���ļ����ԱȽϸߡ�����ͳ���ݿ�ͨ����Ҫ�����м�����ʵ�����ƵĹ��ܡ�
����Hbase����ʱ�临�Ӷ�
��Ȼʹ��Hbase��Ŀ���Ǹ�Ч���߿ɿ����߲����ķ��ʺ����ǽṹ�����ݣ���ôHbase�������ݵ�ʱ�临�Ӷ��ǹ�ϵ������Hbase��ҵ��ϵͳ������Ƶ�����֮�أ�Hbase�������ж�죬���ǴӼ�����㷨����ѧ�Ƕ�����Ҫ�������Ա����������ĵ���Ŀʵ����Hbaseҵ��ģ�����ģʽ�еĿ������ء�
�����������±�������Hbase�����������Ϣ��
n=����KeyValue��Ŀ����������Put�����Delete���µı�ǣ�
b=HFile�����ݿ⣨HFileBlock��������
e=ƽ��һ��HFile����KeyValue��Ŀ�����������֪���еĴ�С�����Լ���õ���
c=ÿ�����е�ƽ������
����֪��Hbase���������������-ROOT-&.META.������.META.����¼Region������Ϣ��ͬʱ��.META.Ҳ�����ж��Region������ͬʱ-ROOT-���ּ�¼.META.����Region��Ϣ����-ROOT-ֻ��һ��Region����-ROOT-����λ����Hbase�ļ�Ⱥ�ܿؿ�ܣ���Zookeeper��¼��
����-ROOT-&.META.����ϸ�����ﲻ������������Ȥ�Ķ��߿��Բ���Hbase�CROOT-��.META.�����ϣ�����HbaseIO�����ݼ���ʱ��ԭ����
Hbase����һ�����ݵ���������ͼ��ʾ��
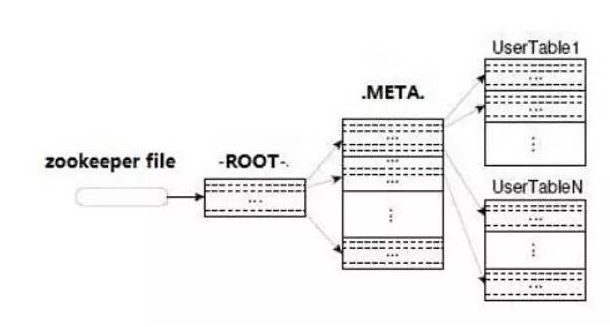
����ͼ���ǿ��Կ�����Hbase����һ���ͻ�������Ҫ�Ĵ������̴������£�
(1)�����֪���н���ֱ�Ӳ�����key-valueֵ��������Ҫ��������region���䣬��������Table�������Ļ�ʱ�临�Ӷ���O(n)��������������ʱ�IJ�����ͨ���ͻ��˳����Dz��ܽ��ܵģ�������Ҫ��������н�ɨ�������ʱ�临�Ӷ������Ҳ��������2��4��������ݡ�
(2)�ͻ���Ѱ����ȷ��RegionServer��Region������3�ι̶������ҵ���ȷ��region����������ZooKeeper������-ROOT-��������.META��������һ��O(1)���㡣
(3)��ָ��Region�ϣ����ڶ������п��ܴ��������ط��������û��ˢд��Ӳ�̣��Ǿ�����MemStore�У�����Ѿ�ˢд��Ӳ�̣�����һ��HFile�С��ٶ�ֻ��һ��HFile����һ������Ҫô�����HFile�У�Ҫô��Memstore�С�
(4)���ں��ߣ�ʱ�临�Ӷ�ͨ���ȽϹ̶�����O(loge)������ǰ�ߣ���������Ҫ���ӵö࣬��HFile�в�����ȷ�����ݿ���һ��ʱ�临�Ӷ�ΪO(logb)�����㣬�ҵ���һ�����ݺ��ٲ����д�����keyvalue�����������ɨ������ˣ�ͬһ�дص�������ͨ������ͬһ���ݿ��еģ��������Ļ�ɨ���ʱ�临�Ӷ���O(elb),����д��е������ݲ���ͬһ���ݿ飬����Ҫ���ʶ���������ݿ飬������ʱ�临�Ӷ�ΪO(c)�����������ʱ�临�Ӷ������ֿ����Ե����ֵ��Ҳ����O(max(c,elb)��
��������������Hbase��ijһ�е�ʱ�俪��Ϊ��
O(1)���ڲ���region
O(loge)������region�ж�λKeyValue�����������MemStore��
O(logb����������HFile������ȷ�����ݿ�
O(max��celb)��������HFile
�ġ�HBase��ģʽ���ԭ���Ż�
1���д�(clumn family)
��Ҫ��һ�ű��ﶨ��̫����дأ�Ŀǰhbase���ܺܺô�������3���дصı���hbase��flush��ѹ���ǻ���region�ģ���һ���д����洢�����ݴﵽflush��ֵʱ���ñ��������дؽ�ͬʱ����flush�������⽫��������Ҫ��I/O������
ͬʱ��Ҫ��ͬһ�����в�ͬ�д����洢�ļ�¼�����IJ�𣬼��дص��ơ����д�����������ʹ������¼�������ٵ��дص����ݷ�ɢ�ڶ��region�ϣ���region�����Ƿֲ��ڲ�ͬ��regionserver�ϣ����������в�ѯ�Ȳ�����ϵͳ��Ч�ʻ��ܵ�һ����Ӱ�졣
2���н�(row key)
��HBase�У�row key�����������ַ��������64KB��ʵ��Ӧ����һ��Ϊ10~100bytes����Ϊbyte[]�ֽ����飬һ����Ƴɶ����ġ�
row key�ǰ����ֵ���洢����ˣ����row keyʱ��Ҫ���������������ص㣬������һ���ȡ�����ݴ洢��һ�飬��������ܻᱻ���ʵ����ݷ���һ�顣
��Σ���Ҫ����ʹ��ʱ����н�����Ϊ�����ݵ���ʱ��hbase���ȸ��ݼ�¼���н���ȷ���洢λ�ã���regionλ�á�����н���ʱ����н�����ô�������������ݽ��ᱻ���䵽ͬһ��region�У�����ʱϵͳ�е�����region/regionserver�����ڿ���״̬�����Ƿֲ�ʽϵͳ��ϣ�������ġ� ���Խ�ʱ����Ϊ�м��ĵڶ����ֶΣ���Ϊ�м�����һ��ǰ��
3��������С���н����дصĴ�С
hbase��һ����¼���ɴ洢��ֵ���н�����Ӧ�����Լ���ֵ��ʱ���������hbase��������Ϊ�˼���������ʵ��ٶȡ��������Ĵ����ǻ��ڡ��н�+�дأ���+ʱ���+ֵ���ģ�����н����дصĴ�С���������������Ĵ�С������ϵͳ�ĸ�����
4���汾����
��������ʱ����ͨ��HColumnDescriptor.setMaxVersions(int maxVersions)���ñ������ݵ����汾�����ֻ��Ҫ�������°汾�����ݣ���ô��������setMaxVersions(1)��HBase�ڽ������ݴ洢ʱ�������ݲ���ֱ�Ӹ��Ǿɵ����ݣ����ǽ����Ӳ�������ͬ������ͨ��ʱ����������֡�Ĭ��ÿ�����ݴ洢�����汾�����鲻Ҫ�������ù���
5�������ڴ�
��������ʱ����ͨ��HColumnDescriptor.setInMemory(true)�����ŵ�RegionServer�Ļ����У���֤�ڶ�ȡ��ʱ��cache���С�
6��TTL
��������ʱ����ͨ��HColumnDescriptor.setTimeToLive(int timeToLive)���ñ������ݵĴ洢�����ڣ��������ݽ��Զ���ɾ�����������ֻ��Ҫ�洢�����������ݣ���ô��������setTimeToLive(2 * 24 * 60 * 60)��
7���ϲ��ͷ�Ƭ(compact&split)
��HBase�У������ڸ���ʱ����д��WAL ��־(HLog)���ڴ�(MemStore)�У�MemStore�е�����������ģ���MemStore�ۼƵ�һ����ֵʱ���ͻᴴ��һ���µ�MemStore�����ҽ��ϵ�MemStore���ӵ�flush���У��ɵ������߳�flush�������ϣ���Ϊһ��StoreFile���ڴ�ͬʱ�� ϵͳ����zookeeper�м�¼һ��redo point����ʾ���ʱ��֮ǰ�ı���Ѿ��־û���(minor compact)��
StoreFile��ֻ���ģ�һ��������Ͳ��������ġ����Hbase�ĸ�����ʵ�Dz����ӵIJ�������һ��Store�е�StoreFile�ﵽһ������ֵ�ͻ����һ�κϲ�(major compact)������ͬһ��key���ĺϲ���һ���γ�һ�����StoreFile����StoreFile�Ĵ�С�ﵽһ����ֵ���ֻ�� StoreFile���зָ�(split)���ȷ�Ϊ����StoreFile��
���ڶԱ��ĸ����Dz����ӵģ�����������ʱ����Ҫ����Store��ȫ����StoreFile��MemStore�������ǰ���row key���кϲ�������StoreFile��MemStore���Ǿ�������ģ�����StoreFile�����ڴ���������ͨ���ϲ����̻��DZȽϿ�ġ�
ʵ��Ӧ���У����Կ��DZ�Ҫʱ�ֶ�����major compact����ͬһ��row key���Ľ��кϲ��γ�һ�����StoreFile��ͬʱ�����Խ�StoreFile���ô�Щ������split�ķ�����
�塢HBase�ı����ʵ��
����Hbase��ϵͳ����뿪���У���Ҫ���ǵ����ز�ͬ�ڹ�ϵ�����ݿ⣬Hbaseģʽ�����ܼ����������������Ŀռ䣬��һЩģʽд���ܺܺã�����ȡ����ʱ���ֲ��ã����������෴�����ƴ�ͳ���ݿ���ڷ�ʽ��OR��ģ����ʵ����Ŀ�п���Hbase���ģʽ�ǣ�������Ҫ�����¼������������֣�
- �����Ӧ���ж��ٸ��д�
- �д�ʹ��ʲô����
- ÿ���д�Ӧ�ж��ٸ���
- ����Ӧ����ʲô���������������ڽ���ʱ���壬���Ƕ�д����ʱ����Ҫ��
- ��ԪӦ�ô��ʲô����
- ÿ����Ԫ�洢ʲôʱ��汾
- �н��ṹ��ʲô��Ӧ�ð���ʲô��Ϣ
����������һ��ʹ��Hbase�����Ŀͻ�����Ϊ����չʾ��
1����������
�ͻ���飺�ͻ���һ���������ֻ���Ϸƽ̨����Ҫ��Թ��������ҽ������β�Ʒ��ͳ�Ʒ�������Ҫ�洢ÿ��������Ҽ��ͻ���ÿ�����β�Ʒ�Ĺ�ע�ȣ���Ϸ�ȶȣ����Ҵ洢ʱ��ά���ϵĹ�ע����Ϣ���Ӷ�����Կͻ���ϲ�ý����ھ������ƾ�Ӫ�������ζ������ͣ����Ӫ����ҵ�Ӷ������ƽ̨���û����������û�ճ�Ŷȡ�
��ƽ̨�����β�Ʒ�����ڶ࣬�ܹ���500�����ϣ�ע����ң��û��ʺţ�������200�����ң������������5��࣬ÿ��ʹ������Ƶ�ʷ�ֵ��10��/�˴����ϣ�������10%���ϡ�
���������������β�Ʒ��̬��������ȷ����Щ���β�Ʒ��Ҫ���洢��ȫ���洢�ֻᳬ��200�У���ɴ����ռ��˷ѣ����ÿ��ʹ�����ε�Ƶ�ʼ����ȷ�����ͻ�ע���û����������ʹ���ȶ�����������1000���У���������Ҳʹ�ñ���ѯ��ҵ�������Ҫ�ļ�Ⱥ�����Ӵ�SQL�Ż���Ч�ʵ��£���˴�ͳ��ϵ�����ݿⲻ�ʺϸ������ݷ����ʹ�������������Ŀ�����Ǿ�������Hbase���������ݲ�Ĵ洢�ķ�����
2���߱����
�����ǻص����������ģʽ�����Ǹÿͻ������б�����ƣ�������Ҫ�洢�����Ϣ��ͨ�����źţ�QQ�ż��ڸ�����ƽ̨��ע����ʺţ�ͬʱ��Ҫ�洢���û���עʲô���β�Ʒ����Ϣ�����û�ÿ�����һ�����߶�����β�Ʒ��ÿ����Ʒ��һ�λ��߶�Σ���˴洢��Ӧ���Ǹ��û���ijһ���β�Ʒ�Ĺ�ע�ȣ�ʹ�ô���������ʹ�ô�����ÿ����һ����̬��ֵ�����û������β�ƷҲ��һ����Զ��key value��ֵ�ļ��ϡ�������ƽ̨���̹��ĵ������硰XXX�ͻ���ҹ�עYYY������ô��������YYY���α��û���ע��ô���������ҵ��ά�ȷ�����
����ÿ��ÿ��������Ҷ�ÿ����Ʒ�Ĺ�ע�ȶ����ڸñ��У���һ�����ܵ���Ʒ�����ÿ���û�ÿ���Ӧһ�У�ʹ���û�ID+�����ʱ�����Ϊ�н�������һ���������β�Ʒʹ����Ϣ���дأ�ÿ�д���������û��Ըò�Ʒ��ʹ�ô�����
������������ֻ���һ���дأ�һ���ض����д���HDFS�ϻ���һ��Region�������region�µ������洢�����ж��HFile��һ���д�ʹ����������Ӳ���ϴ����һ��ʹ��������Կ���ʹ��ͬ���͵������ݷ��ڲ�ͬ���д��ϣ��Ա���룬��Ҳ��Hbase����Ϊ�����д洢��ԭ�������ű����Ϊ�������β�Ʒ��û�����Եķ��࣬�Ա��ķ���ģʽҲ�����������β�Ʒ���ͣ���˲�����Ҫ����дصĻ��֣�����Ҫ��ʶ��һ�㣺һ�������˱����κζԸñ��дصĶ���ͨ������Ҫ���ñ�offline��
���ǿ���ʹ��HbaseShell��������Hbaseshell�ű�ʾ�����£�
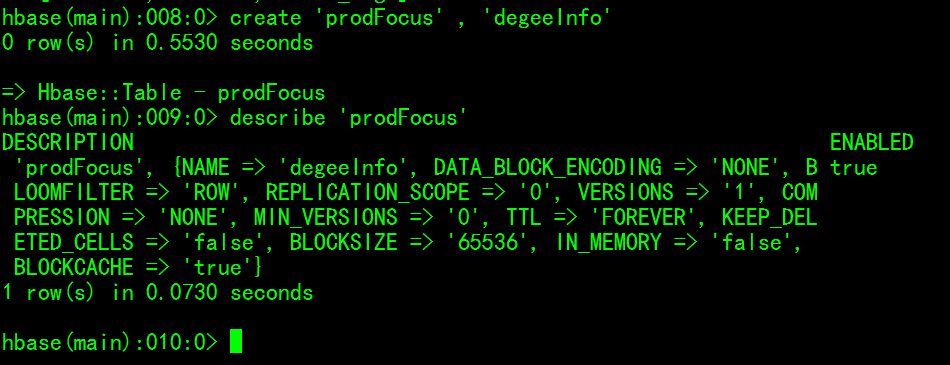
Ȼ����ñ��в������ݣ����洢��ʾ���������£�
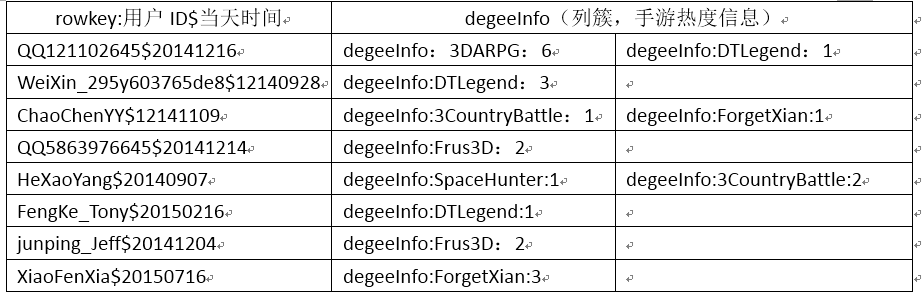
����ƽ������£�
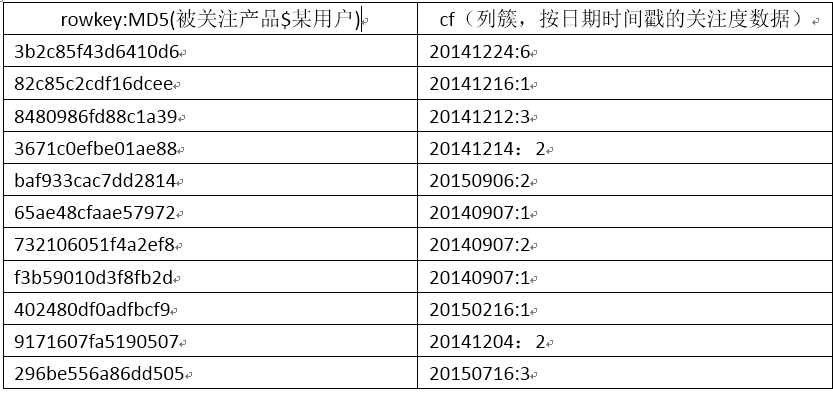
rowkeyΪQQ121102645$20141216��ʾ�ʺ�ΪQQ121102645��������ң���QQ��������֤�ģ���2014��12��16�յ������Ϸ��¼���д�degeeInfo��¼�����˻������ÿ�ֲ�Ʒ���͵ĵ���ȶ�(��Ϸ����)������SpaceHunter: 1��ʾ��(���ߵ㿪)SpaceHunter(ʱ������)�Ĵ���Ϊ1�Ρ�
����������Ҫ�������ű��Ƿ���������Ϊ������Ҫ�����Ƕ������ģʽ��Ҳ����Ӧ��ϵͳ��η���Hbase���е����ݣ�������Hbaseϵͳ��ƿ���������Ӧ�þ�����ô����
��������������������Ƶĸ�Hbase���Ƿ��ܻش�ͻ����ĵ����⣺���硰�ʺ�ΪQQ121102645���û���ע����Щ���Σ�����������������һ��˼���������ҵ����������⣺��QQ121102645�û��Ƿ����3CountryBattle������3�����Σ�������Щ�û���ע��DTLegend����������)������3CountryBattle������3�����α���ע���𣿡�
�������ڵ�prodFocus����ƣ�Ҫ�ش��ʺ�ΪQQ121102645���û���ע����Щ���Σ����������ģʽ�������ڱ���ִ��һ����Scanɨ��������õ��û᷵������QQ121102645ǰ�������У�ÿһ�е��дؽ����б��������ҵ��û���ע�������б���
�������£�
HTablePool pool = new HTablePool();
HTableInterface prodTable = pool.getTable(��prodFocus��);
Scan a = new Scan();
a.addFamily(Bytes.toBytes(��degreeInfo��));
a.setStartRow(Bytes.toBytes(��QQ121102645��));
ResultScanner results = prodTable.getScanner(a);
List<KeyValue> list = result.list();
List<String> followGamess = new ArrayList<String>();
for(Result r:results){
KeyValue kv = iter.next();;
String game =kv.get(1];
followGames.add(user);
}
��ΪprodFocus��rowkey���Ϊ�û�ID $ �����ʱ�����������Ǵ������û���QQ121102645��Ϊ����ǰ��Scanɨ�裬ɨ�践�ص�ResultScanner��Ϊ���û���ص����������ݣ�����ÿ�еġ�degreeInfo���д��еĸ����м��ɻ�ø��û����й�ע������������β�Ʒ��
�ڶ������⡰QQ121102645�û��Ƿ����3CountryBattle������3�����Ρ���ҵ�����һ�����ƣ��ͻ��˴��������Scan�ҳ��н�ΪQQ121102645ǰ�������У����ص�result���Ͽ��Դ���һ�������б�����������б����3CountryBattles�����Ƿ���Ϊ�������ڣ������жϸ��û��Ƿ��עijһ���Σ���Ӧ��������������1�Ĵ������ƣ�
HTablePool pool = new HTablePool();
HTableInterface prodTable = pool.getTable(��prodFocus��);
Scan a = new Scan();
a.addFamily(Bytes.toBytes(��degreeInfo��));
a.setStartRow(Bytes.toBytes(��QQ121102645��));
ResultScanner results = prodTable.getScanner(a);
List<Integer> degrees = new ArrayList<Integer>();
List<KeyValue> list = results.list();
Iterator<KeyValue> iter = list.iterator();
String gameNm =��3CountryBattle��;
while(iter.hasNext()){
KeyValue kv = iter.next();
if(gameNm.equals(Bytes.toString(kv.getKey()))){
return true;
}
}
prodTable.close();
return false;
������ͣ�ͬ��ͨ��ɨ��ǰΪ��QQ121102645����Scanִ�б��������������ص�List<keyValue>������ÿһKey-value��degreeInfo�д���ÿһ�еļ�ֵ�ԣ����û���ע������������β�Ʒ��Ϣ���ж���Keyֵ�Ƿ������3CountryBattle������Ϸ����Ϣ����֪�����û��Ƿ��ע�����β�Ʒ��
���������������Ǽ�ʵ�õģ�����������ǽ��ſ��������͵��ĸ�ҵ�����⡰��Щ�û���ע��DTLegend����������)������3CountryBattle������3�����α���ע���𣿡�
�����������ģ����еı���ƶ��ڶ�����β�Ʒ�Ƿ����дصĶ�����ֶ��еģ���˵�ijһ�û��Բ�Ʒ��ϲ�����ڶ�������ʱ��productkey-value��ֵ�Ի�ܶ࣬��ζ��ijһrowkey�ı��дػ�䳤���Ȿ��Ҳ���Ǵ����⣬����Ӱ�쵽�˿ͻ��˶�ȡ�Ĵ���ģʽ�����ÿͻ���Ӧ�ô����úܸ��ӡ�
ͬʱ�����ڵ����͵���������ԣ�ÿ����һ�����ι�ע��key-value��ֵ���ͻ��˴������Ҫ�ȶ������û���row�У��ٱ����������д��е�ÿһ�����ֶΡ�������Hbase������ԭ�����ڲ������Ļ�������֪�����н�������Hbase�����ľ��������أ������֪���н�������Ҫ��ɨ����������HFile���ݿ��У����鷳���ǣ�������ݻ�û�д�HDFS�������ݿ黺�棬��Ӳ�̶�ȡHFile�Ŀ�����������Hbase������ʱ�临�Ӷȷ������������ڵ�Hbase�����ģʽ����Ҫ��Region�м���ÿһ�У�Ч�����еĸ���*O(max(elb)�����������Ѿ�����ӵ����ݼ������̡�
�Թ�ע��ƽ̨ҵ��Ŀͻ���˾�Ƕȿ��ǣ����������ĸ���ҵ��������ӹ�ע�ͻ��˻�ȡ���������ʵʱ���������ܣ���˴����ģʽ��Ӧ����Ƹ������н������̵��д��ֶΣ����Hbase�н��ļ���Ч�ʲ�ͬʱ���ٷ��ʿ��еĿ�����
3���������
Hbase���ģʽ�ļ�������������������Ż�������Ҫ���ܶ�Ĺ����Ϳ��Դ��ͻ��˴��룬����ʹ���������ܻ��������������������������prodFocus������һ�����ģʽ��֮ǰ�ı������һ�ֿ�����widetable��ģʽ����һ�а����ܶ��С�ÿһ�д���ijһ���ε��ȶȡ�ͬ������Ϣ�����ø߱���talltable����ʽ�洢���µĸ߱���ʽ��ƵIJ�Ʒ��ע�ȱ��ṹ������ʾ��
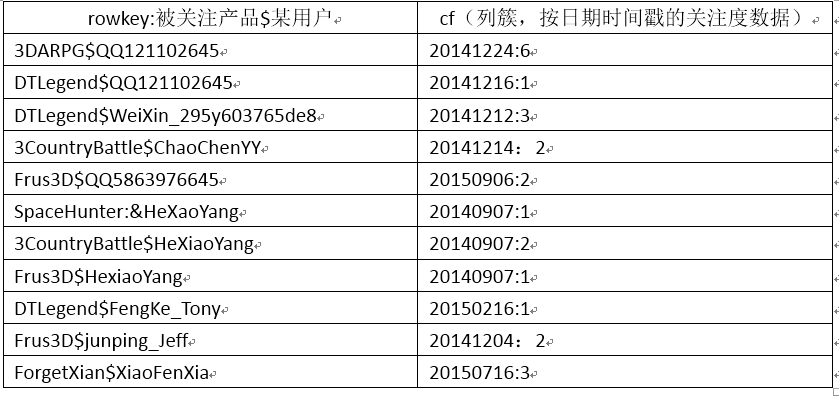
�����ͣ�����Ʒ��ijһ�챻ij�û���ע�Ĺ�����ϵ��Ƶ�rowkey�У������ע������ֻ��һ��key-value���洢���н�Daqier_weixin1398765386465����������ֵ����Ʒ�����û����ʺţ�����ԭ���������ijһ�û���ij�����Ϣ��ת��Ϊһ������Ʒ-��ע���û����Ĺ�ϵ�����ǵ��͵ĸ߱���ơ�
HFile�е�key-value����洢�д����֡�ʹ�ö̵��д������ڼ���Ӳ�̺�����IO������а����������Ż���ʽҲ����Ӧ�õ��н���������������Ԫ�����յ�rowkey�洢ҵ��������ζӦ�ó������ʱ��IO���ط�����͡������±�����ڻش�֮ǰҵ����ĵġ���Щ�û���ע��XXXX��Ʒ�������ߡ�XXXX��Ʒ����ע���𣿡���������ʱ���Ϳ��Ի����н�ʹ��get()ֱ�ӵõ��𰸣��д���ֻ��һ����Ԫ�����Բ����е�һ������ж��key-value���������⣬��Hbase�з���פ����BlockCache��һ��խ�������Ķ���������IO����������ɨ����Щ����һ��������ִ��get����Ȼ��������е�Ԫ��ȣ���RegionServer��ȡ������������ͬ�ģ�����������Ч�����Դ������ˡ�
����Ҫ������3CountryBattles������Ⱥ�ۣ������Ƿ�QQ121102645�û���ע����ʱ���ͻ��˴���ʾ�����£�
HTablePool pool = new HTablePool();
HTableInterface prodTable = pool.getTable(��prodFocusV2��);
String userNm =��QQ121102645��;
String gameNm =��3CountryBattles��;
Get g = new Get(Bytes.toBytes(userNm+��$��+gameNm));
g.addFamily(Bytes.toBytes(��degreeInfo��));
Result r = prodTable.get(g);
if(!r.isEmpty()){
return true;
}
table.close();
return false;
������ͣ�����prodFocusV2��rowkey��Ƹ�Ϊ����ע��Ʒ$�û�Id�ĸ߱�ģʽ�����β�Ʒ���û���Ϣֱ�Ӵ�����н��У���˴��������β�Ʒ����3CountryBattles$�����û��ʺš�QQ121102645����Byte������ΪGet��ֵ���ڱ���ֱ��ִ��Get�������жϷ��ص�Result������Ƿ�Ϊ�ռ���֪�������β�Ʒ�Ƿ��û���ע��
4�������Ż�
��Ȼ����һЩ�����Ż����ɡ������ʹ��MD5ֵ��Ϊ�н����������Եõ�������rowkey��ʹ��ɢ�м����������ô�����������н���ʹ��MD5ȥ����$���ָ����������������ô���һ���м�����ͳһ���ȵģ�����������õ�Ԥ���д���ܡ��ڶ����ô��ǣ�������Ҫ�ָ�����scan�IJ����������������ʼ��ֹͣ��ֵ�������Ļ���ʹ�û����û�$��������MD5ɢ��ֵ���趨Scanɨ����ڵ���ʼ�У�startRow��stopRow���Ϳ����ҵ��������ܹ�ע�����µ��ȶ���Ϣ��
ʹ��ɢ�м�Ҳ�����������ݸ����ȵķֲ���region�ϡ���ð����У�����ͻ��Ĺ�ע���������ģ���ÿ�춼�в�ͬ�Ŀͻ��治ͬ����Ϸ���������ݵķֲ��������⣬���п���ijЩ�ͻ��Ĺ�ע����������б�ģ���ij�û�����ϲ��ijһ������Ʒ��ÿ���ȶȶ�����һ������Ʒ�ϣ����Ǿͻ���һ�����⣬�����������û�з�̯������Hbase��Ⱥ�϶��Ǽ�����ijһ���ȵ��region�ϣ��⼸��region���Ϊ�������ܵ�ƿ�����������Daqier_weixin$1398765386465ģʽ��MD5���㲢�ѽ����Ϊ�м������������region��ʵ��һ�����ȵķֲ���
ʹ��MD5ɢ��prodFocusV2����ı�ʾ�����£�