Apache HBase简介
Apache HBase是Hadoop数据库,是一个分布式,可扩展的大数据存储。
当您需要对大数据进行随机,实时读/写访问时,请使用Apache HBase。HBase是一个分布式的、面向列的开源数据库,该技术来源于Fay Chang所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”。就像Bigtable利用了Google文件系统所提供的分布式数据存储一样,HBase在Hadoop之上提供了类似于Bigtable的能力。HBase是Apache的Hadoop项目的子项目。HBase不同于一般的关系型数据为,它是一个适合于非结构数据存储的数据库。另一个不同的是HBase是基于列的而不是基于行的模式。
官网地址:http://hbase.apache.org/
HBase架构

角色关系:
| 角色 |
说明 |
| Client |
发起HBase读写请求的客户端 |
| Zookeeper |
记载了HBase的元数据信息,其中主要是-ROOT-表所在的位置信息 |
| HMaster |
用于分配RegionServer的Region,负载均衡等作用 |
| HRegionServer |
Hbase集群的一个服务器 |
| HLog |
HBase日志,用于保证数据的完整性 |
| HRegion |
相当于一个表 |
| Store |
抽象的表示,表示字段的存储 |
| MemStore |
内存的存储 |
| StoreFile |
字段数据具体存在的文件 |
| HFile |
当发生溢写时,生成的文件,此文件会通过DFS Client发送到HDFS |
| DataNode |
HDFS上具体存储数据的地方 |
Apache HBase是构建在HDFS之上的一个组件,快速的读/写访问可以满足大数据读/写的实时性,解决了HDFS存储文件的实时性问题。
当读取数据时,HBase首先会从Zookeeper集群中获取元数据信息,以便定位数据所在的HRegion,如果MemStore存在数据,则直接返回。
当写入数据时,首先会把数据写入到StoreFile中,当StoreFile达到一定的阈值时,会溢写到HDFS中,溢写成功后,会把StoreFile文件清空。先经过StoreFile的存储是为了避免频繁访问HDFS文件太系统,提高存储性能。
下面再对HBase的读/写进行更详细的分析。
HBase读取数据流程

步骤:
- HBase客户端发出读取请求,先访问zk集群;
- zk集群返回-ROOT-表的位置信息;
- HBase客户端根据zk集群返回的信息找到-ROOT-表,一个-ROOT-表只能存储在一个HRegion中,不可切分,.-ROOT-记录了.META表的Region信息;
- 通过-ROOT-表再找到.META表的元数据信息,.META表记录了用户创建的表的Region信息,.META可以有多个Region;
- 从 .META表中获取要查询的数据的元数据信息;
- 根据.META返回的元数据信息,找到对应的HRegion;
- HRegion返回数据到客户端。
上图中描述了一个HBase客户端发起读取请求后的整体流程,下面再具体讲解一个如何从HRegion获取要查询的数据。

Memstore是内存写入缓存,BlockCache是内存读取缓存。
HBase在写入数据时,首先会把数据写入到Memstore中,达到一个阈值后会溢写到HDFS生成HFile文件。
当HBase读取数据时,如果从HDFS获取数据,首先会缓存到BlockCache中,然后再返回给客户端。
步骤分析:
- HBase客户端请求获取数据,首先从Memstore查找数据;
- 因为没有达到阈值之前,要写入的数据还会在Memstore中,所以,如果此时再读取,可以马上查找并返回。因为没有达到阈值之前,要写入的数据还会在Memstore中,所以,如果此时再读取,可以马上查找并返回;
- 当Memstore没有查找到数据时,代表数据可能已溢写到hdfs中,此时先查找一下BlockCache,BlockCache是读取缓存,如果要读取的数据之前从HDFS中读取过,会在BlockCache中缓存下来,此时查找就可能会查找到结果并立即返回;
- 当在BlockCache没有查找到数据时,此时才会从HDFS中查找数据;
- 当从HDFS查找到数据后,首先会把数据缓存到BlockCache;
- 然后再从BlockCache返回数据到HBase客户端。
注意,上面的Memstore,BlockCache和HFile都是分布式存储
HBase写入数据流程

步骤分析:
- HBase客户端请求zk集群获取表元数据;
- zk集群返回表的元数据信息,-ROOT-和.Meta表的元数据;
- HBase客户端通过-ROOT-和.Meta表的元数据获取到可以写入数据的Region,并通过RPC协议与RegionServer进行交互;
- 数据首先写入到HLog中,HLog是为了防止数据丢失,以便使数据可恢复,保证数据的完整性;
- 然后再写入到Memstore,Memstore默认大小是16kb;
- 当Memstore存储满后,会溢写到HFile中,至此,HBase写数据完成。
HBase安装部署
- 下载安装包,目前稳定版为1.4.9
https://mirrors.tuna.tsinghua.edu.cn/apache/hbase/stable/
- 上传到服务器并解压
- 修改conf/hbase-env.sh文件
export JAVA_HOME=
export HBASE_MANAGES_ZK=false
- 修改conf/hbase-site.xml文件
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://hd-even-01:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.master.port</name>
<value>16000</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hd-even-01:2181,hd-even-02:2181,hd-even-03:2181</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/even/hd/zookeeper-3.4.10/zkData</value>
</property>
</configuration>
- 修改conf/regionservers,添加作为regionservers的主机
# 虽然本次配置把hd-even-01作为region-master,而region-master也可以作为regionserver使用,所以此处也添加进去
hd-even-01
hd-even-02
hd-even-03
- 解决依赖包问题
# hbase需要依赖hadoop和zookeeper,因此,lib目录下需要有hadoop和zookeeper相关的包,默认情况下已包含,但需要根据自己安装的hadoop和zookeeper进行修改
cd hbase/lib
rm -f hadoop-*
rm -f zookeeper-*
#然后把自己使用的hadoop和zookeeper相关jar包拷贝过来。
- 把hadoop的配置软连接到hbase/conf中,hbase是构建在hadoop的hdfs之上的,所以需要hadoop的配置
# 根据自己的实际情况
ln -s /hadoop/core-site.xml /hbase/conf
ln -s /hadoop/hdfs-site.xml /hbase/conf
- 启动集群
# 启动master-server,推荐使用hbase-daemon.sh命令
bin/hbase-daemon.sh start master
# 启动regionserver
bin/hbase-daemon.sh start regionserver
- 启动终端
bin/hbase shell

- 可视化界面,hd-even-01是master的主机号:
http://hd-even-01:16010

Hbase Shell命令
基本命令
- 查看服务器状态
status ‘hd-even-01’

activiti master代表活跃的master服务器,backup masters表示备份master服务器,servers表示regionserver服务器,dead表示宕机的数量,average load表示平均加载。
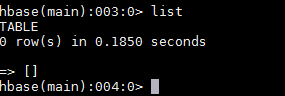
- 查看当前所有表
list
- 查看帮助
help

表操作
-
创建表
create ‘表名’,‘列族’,‘列族1’,‘列族2’…

-
查看表结构
describe ‘表名’

VERSIONS表示列族的版本号
-
向表中插入数据
put ‘表名’,‘rowkey’,‘列族:列名’,‘值’

-
全表扫描
scan ‘表名’

rowkey表示行键,唯一不重复;timestamp表示时间戳;cell表示单元格,数据存放的位置;column familly表示列族,列族下包含多个列,一个表包含多个列族;column表示列。
HBase没有修改功能,只有覆盖功能,只要保持rowkey不变,列族和列相同就会进行覆盖操作
-
筛选扫描
scan ‘表名’,{STARTROW => ‘1001’,STOPROW = ‘1002’}
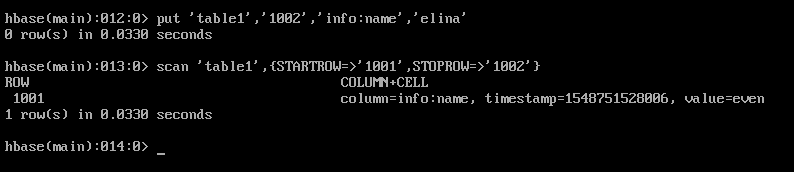
=>不是代表大于等于的意思,而是“指向”。上面代表扫描开始行是1001,结束行是1002。除此之外还有LIMIT,限制显示条件;TIMERANGE和FITLER等高级功能。
-
变更表信息
alter ‘表名’,{NAME=>‘info’,VERSIONS=>‘3’,BLOCK=>‘65538’}

-
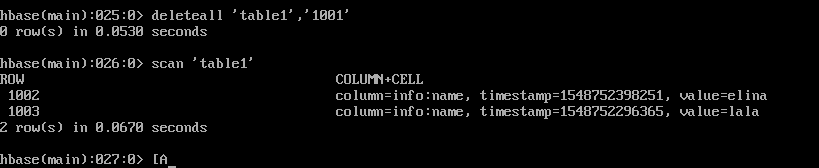
删除数据
根据rowkey删除
deleteall ‘表名’,‘rowkey’
根据具体的列删除
delete ‘表名’,‘rowkey’,‘列族:列’

-
清空表
truncate ‘表名’
-
删除表
第一步,设置表为不可用状态
disable ‘表名’
第二步,删除该表
drop ‘表名’
-
统计表中的数据行数,即rowkey的数量
count ‘表名’
-
查看指定rowkey值
get ‘表名’,‘rowkey’
-
查看具体列值
get ‘表名’,‘rowkey’,‘列族:列’
HBase API操作
导入依赖:
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>1.4.9</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>1.4.9</version>
</dependency>
- 建立连接
public static Configuration conf;
public static Connection connection;
static {
conf = HBaseConfiguration.create();
}
public static void connect() throws IOException {
connection = ConnectionFactory.createConnection(conf);
}
- 关闭连接
public static void closeConnection() throws IOException {
connection.close();
}
- 判断表是否存在
public static boolean isExitTable(String tableName) throws IOException {
HBaseAdmin admin = (HBaseAdmin) connection.getAdmin();
if (admin.tableExists(TableName.valueOf(tableName))) {
return true;
} else {
System.out.println("查询不到表");
return false;
}
}
public static void main(String[] args) throws IOException {
connect();
isExitTable("table1");
closeConnection();
}
- 创建表
public static void createTable(String tableName, String... column_Family) throws IOException {
HBaseAdmin admin = (HBaseAdmin) connection.getAdmin();
if (admin.tableExists(TableName.valueOf(tableName))) {
System.out.println("表已存在,请输入其它表名");
} else {
HTableDescriptor hTableDescriptor = new HTableDescriptor(TableName.valueOf(tableName));
for (String column : column_Family) {
hTableDescriptor.addFamily(new HColumnDescriptor(column));
}
admin.createTable(hTableDescriptor);
System.out.println("表已创建成功!");
}
}
public static void main(String[] args) throws IOException {
connect();
createTable("even", "info", "info1");
closeConnection();
}
- 删除表
public static void deleteTable(String tableName) throws IOException {
HBaseAdmin admin = (HBaseAdmin) connection.getAdmin();
if (isExitTable(tableName)) {
admin.disableTable(TableName.valueOf(tableName));
admin.deleteTable(TableName.valueOf(tableName));
System.out.println("删除表成功");
}
}
- 添加数据
public static void putData(String tableName, String rowKey, String columnFamily, String column, String value) throws IOException {
HBaseAdmin admin = (HBaseAdmin) connection.getAdmin();
if (isExitTable(tableName)) {
HTableDescriptor tableDescriptor = admin.getTableDescriptor(TableName.valueOf(tableName));
HColumnDescriptor[] columnFamilies = tableDescriptor.getColumnFamilies();
boolean isExit = false;
for (HColumnDescriptor hColumnDescriptor : columnFamilies) {
String s = hColumnDescriptor.getNameAsString();
if (columnFamily.endsWith(s)) {
isExit = true;
break;
}
}
if (isExit) {
Put p = new Put(Bytes.toBytes(rowKey));
p.addColumn(Bytes.toBytes(columnFamily), Bytes.toBytes(column), Bytes.toBytes(value));
Table table = connection.getTable(TableName.valueOf(tableName));
table.put(p);
System.out.println("数据插入成功!");
} else
System.out.println("不存在的列族!");
}
}
- 删除指定rowkey的数据
public static void deleteByRowKey(String tableName, String rowKey) throws IOException {
if (isExitTable(tableName)) {
Table table = connection.getTable(TableName.valueOf(tableName));
if (table.exists(new Get(Bytes.toBytes(rowKey))))
table.delete(new Delete(Bytes.toBytes(rowKey)));
else
System.out.println("不存在的rowKey数据,请输入正确的rowKey");
}
}
- 删除多个rowkey的数据
public static void deleteByRowKeys(String tableName, String... rowKey) throws IOException {
if (isExitTable(tableName)) {
Table table = connection.getTable(TableName.valueOf(tableName));
List<Delete> deletes = new ArrayList<>();
for (String row : rowKey) {
if (table.exists(new Get(Bytes.toBytes(row))))
deletes.add(new Delete(Bytes.toBytes(row)));
}
table.delete(deletes);
System.out.println("删除数据成功!");
}
}
- 扫描表
public static void scanAll(String tableName) throws IOException {
if (isExitTable(tableName)) {
Table table = connection.getTable(TableName.valueOf(tableName));
ResultScanner scanner = table.getScanner(new Scan());
for (Result next : scanner) {
Cell[] cells = next.rawCells();
for (Cell c : cells) {
System.out.println("行键为:" + Bytes.toString(CellUtil.cloneRow(c)));
System.out.println("列族为:" + Bytes.toString(CellUtil.cloneFamily(c)));
System.out.println("值为:" + Bytes.toString(CellUtil.cloneva lue(c)));
System.out.println(c);
}
}
}
}
- 根据rowkey扫描表
public static void scanByRowKey(String tableName, String rowKey) throws IOException {
if (isExitTable(tableName)) {
Table table = connection.getTable(TableName.valueOf(tableName));
Get get = new Get(Bytes.toBytes(rowKey));
get.addFamily(Bytes.toBytes("info"));
get.addColumn(Bytes.toBytes("info"), Bytes.toBytes("id"));
Result result = table.get(get);
Cell[] cells = result.rawCells();
for (Cell c : cells) {
System.out.println(c);
System.out.println("行键为:" + Bytes.toString(CellUtil.cloneRow(c)));
System.out.println("列族为:" + Bytes.toString(CellUtil.cloneFamily(c)));
System.out.println("值为:" + Bytes.toString(CellUtil.cloneva lue(c)));
}
}
}
总结
本文对HBase的构架,安装部署以及使用进行了简单的介绍。HBase的技术来源于Fay Change撰写的Goole论文“Bigtable:一个结构化数据的分布式存储系统”。与Hive相比,因HBase的读写分离(两个缓存区处理读写操作)令它的读/写速度更实时,而Hive只适合用来对一段时间内的数据进行分析查询。
HBase构建于HDFS之上的,所以,它也可以认为是一个类型于数据库的存储层,适用于结构化的存储,并且是一种的分布式数据库。更多内容请查看HBase官方文档。
参考资料
HBase官方文档:http://hbase.apache.org/book.html