出自《HBase不睡觉书》,转载请注明出处。
当我们使用传统的关系型数据库的时候,如果有一些作业对性能要求比较高,并且需求不会经常变动,我们往往会采用存储过程来实现;还有一些作业我们需要当数据达到某种条件的时候自动触发,我们往往会采用触发器来实现。在HBase中也有类似存储过程和触发器的功能,它叫协处理器)(0.92版本之后)。
HBase的协处理器涵盖了两种类似关系型数据库中的应用场景:存储过程和触发器。协处理器也分两种:用来实现存储过程的中断程序(EndPoint)和用来实现触发器功能的观察者(Obsevers)。
=================================================
需求:
当插入数据时,如果遇到单元格为mycf:name=JACK,则在mycf:message这个列插入一句话:Hello World! Welcome back!。这个需求在关系型数据库中使用触发器来实现。在HBase中我们使用协处理器来实现。
step1
新建maven项目,打包方式选择jar。原生版本只需添加hbase-server依赖(不要同时添加hbase-client依赖)。而cdh版本需要同时添加hbase-server、hbase-client,hbase-common以及guava包。
pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.idayan</groupId>
<artifactId>coprocessor</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<name>coprocessor</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>1.2.0-cdh5.8.0</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>1.2.0-cdh5.8.0</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-common</artifactId>
<version>1.2.0-cdh5.8.0</version>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>12.0.1</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
</dependencies>
</project>
step 2
新建类:HelloWorldObserver虽然所有的协处理器都要实现接口Coprocessor,但是实现接口需要实现很多不必要的方法。所以我选择直接继承BaseRegionObserver类,这样很多方法都有了基本你的实现,我们只需要重写需要的方法即可。
step 3
编码:
HelloWorldObserver.java
package com.idayan;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.client.Durability;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.coprocessor.BaseRegionObserver;
import org.apache.hadoop.hbase.coprocessor.ObserverContext;
import org.apache.hadoop.hbase.coprocessor.RegionCoprocessorEnvironment;
import org.apache.hadoop.hbase.regionserver.wal.WALEdit;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
import java.util.List;
/**
* @author: xianghu.wang
* @Date: 2018/3/15
* @Description:
*/
public class HelloWorldObserver extends BaseRegionObserver{
public static final String JACK = "JACK";
/**
* 重写prePut方法。
* 这个方法会在Put动作之前进行操作
* @param e
* @param put
* @param edit
* @param durability
* @throws IOException
*/
@Override
public void prePut(ObserverContext<RegionCoprocessorEnvironment> e,
Put put, WALEdit edit, Durability durability) throws IOException {
//获取mycf:name的单元格
List<Cell> name = put.get(Bytes.toBytes("mycf"),Bytes.toBytes("name"));
//如果该put中不存在mycf:name,则不作操作,这个单元格直接返回
if (name == null || name.size() == 0) {
return;
}
//如果该put中存在mycf:name,则判断mycf:name是否为JACK
if (JACK.equals(Bytes.toString(CellUtil.cloneva lue(name.get(0))))) {
//如果mycf:name是JACK,则在mycf:message中添加一句话
put.addColumn(Bytes.toBytes("mycf"),Bytes.toBytes("message"),Bytes.toBytes("Hello World! Welcome back !"));
}
}
}
step 4
打包,放到HDFS上。我的jar包名是coprocessor-1.0-SNAPSHOT.jar,上传到HDFS目录下。
[maxiu@idayan00 hadoop-2.6.0-cdh5.8.0]$ bin/hdfs dfs -put /home/maxiu/myData/coprocessor-1.0-SNAPSHOT.jar /user/maxiu
18/03/15 11:09:20 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
[maxiu@idayan00 hadoop-2.6.0-cdh5.8.0]$ bin/hdfs dfs -ls /user/maxiu
18/03/15 11:10:03 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 1 items
-rw-r--r-- 1 maxiu supergroup 2844 2018-03-15 11:09 /user/maxiu/coprocessor-1.0-SNAPSHOT.jar
我的jar:链接:https://pan.baidu.com/s/1vUw66lCjypE0EO8O3aO-5Q 密码:8wdm
step5
在HBase中启用这个观察者,登录服务器,使用hbase shell 执行以下命令:
hbase(main):002:0> create 'mytable','mycf' //创建表
0 row(s) in 1.5240 seconds
=> Hbase::Table - mytable
hbase(main):003:0> alter 'mytable' , METHOD =>'table_att','coprocessor'=>'hdfs://idayan00//user/maxiu/coprocessor-1.0-SNAPSHOT.jar|com.idayan.HelloWorldObserver||'
Updating all regions with the new schema... //启用协处理器
1/1 regions updated.
Done.
0 row(s) in 2.5410 seconds
hbase(main):004:0> desc 'mytable' //查看表属性
Table mytable is ENABLED
mytable, {TABLE_ATTRIBUTES => {coprocessor$1 => 'hdfs://idayan00//user/maxiu/coprocessor-1.0-SNAPSHOT.jar|com.idayan.HelloWorldObserver||'}
COLUMN FAMILIES DESCRIPTION
{NAME => 'mycf', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'
}
1 row(s) in 0.0490 seconds
hbase(main):005:0>
- table_att是固定词组,意思就是调用setValue()方法给表设置属性
- 属性名为 coprocessor,就是协处理器的意思
- 属性值为<包所在路径>|<协处理器类全名>||,并且中间不能有空格。
如果想删除该协处理器可以执行以下命令:
hbase(main):005:0> alter 'mytable',METHOD =>'table_att_unset',NAME => 'coprocessor$1'
Updating all regions with the new schema...
1/1 regions updated.
Done.
0 row(s) in 2.5900 seconds
测试协处理器
现在尝试用Java API来添加包含有mycf:name=JACK的数据
Put put = new Put(Bytes.toBytes("row1"));
put.addColumn(Bytes.toBytes("mycf"),Bytes.toBytes("name"),Bytes.toBytes("JACK"));
table.put(put);
查看结果:

通过hbase shell 添加数据:
put 'mytable','row2','mycf:name','JACK'
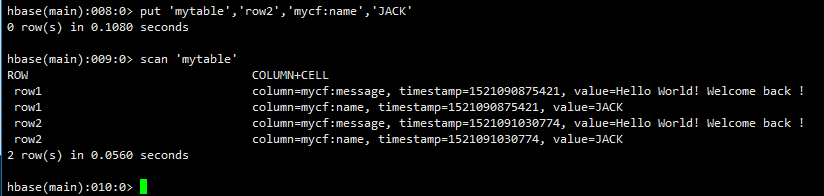
可以看到通过java api 和hbase shell添加数据 协处理器都生效了。
下面我们再添加一条名字不是JACK的
put 'mytable','row3','mycf:name','MAXIU'
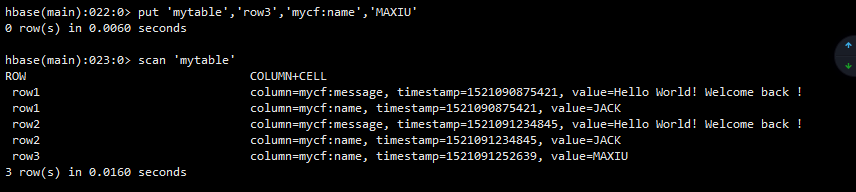
可以看到第三行只有一条记录,并没有在message那一列添加数据。