相关知识
数据存入hbase表时会按照rowkey落在不同的region中,每个region都有边界(除非你只有一个region)startrow和endrow,rowkey在表中是按照ASCⅡ码排序的。
例如下图中的region情况,如果有一个rowkey是006123456,它在0050和0100之间,因此它会被放在第二个region中。

region被regionserver管理,Hbase可以自动将region balance到各个regionserver上,使得每台regionserver上region的个数均匀分布。当某一个regionserver停止服务,它所管理的region会transit到其他regionserver上。regionserver又重新启动后,balancer会再次自动平衡region。
避免region分布倾斜

这里有一个参数需要调整,默认情况下,hbase的balancer是regionserver级别,与表无关,可以想象极端情况下整个每个regionserver下的region个数一样多,但一张表的所有region可能都在一台机器上,这也算是一种数据倾斜,可以通过hbase.master.loadbalance.bytable设置表级别均衡。

避免rowkey分布倾斜
上面描述的Hbase机制保证了region能够均匀的分布在各个节点上,但细化到rowkey粒度就需要我们自己来控制了,书中和网络上有很多rowkey设计的文章谈到不同场景下rowkey的设计,比如用Hash、Salt、Reverse,这里就不再赘述。
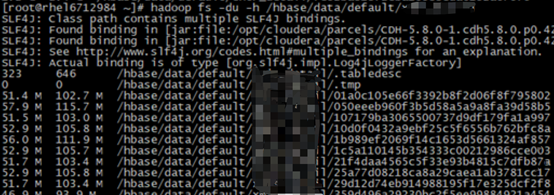
这里给出一个判断数据分布倾斜的方法,就是在hbase目录下表中文件夹大小,每个文件夹就对应着一个region,第一列是三备份前大小,文件夹名就是HbaseWebUI的TableDetail页中regionname的最后一部分(见图)。装入数据后,如果每个文件夹大小都差不多,并在合理的大小范围内,那说明切分的比较好。如果某个文件夹特别大,就要考虑是否有未想到的数据情况,或是rowkey设计不合理。尤其要注意一些特殊值,比如数据是从关系型数据库抽取而来的,那么要提前做好数据探查,了解生成rowkey用的字段是否有为空或者大量特殊值情况,以避免数据倾斜。