ת������������� http://blog.csdn.net/zwto1/article/details/47066523 ��
��ʼ�����HBase֮�ã�
���
HBase �CHadoop Database,��һ���߿ɿ��ԡ������ܡ������С��������ķֲ�ʽ�洢ϵͳ������HBse������������PC Server�ϴ����ģ�ṹ���洢��Ⱥ��HBase����Hadoop HDFS��Ϊ�ļ��洢ϵͳ������Hadoop MapReduce������HBase�еĺ������ݣ�����Zookeeper��ΪЭ�����ߡ�
HBase(NoSQL)������ģ��
HBase �洢����վҳ������ʾ��
���潲�¹���HBase��������ʺ��
HBase(NoSQL)������ģ��
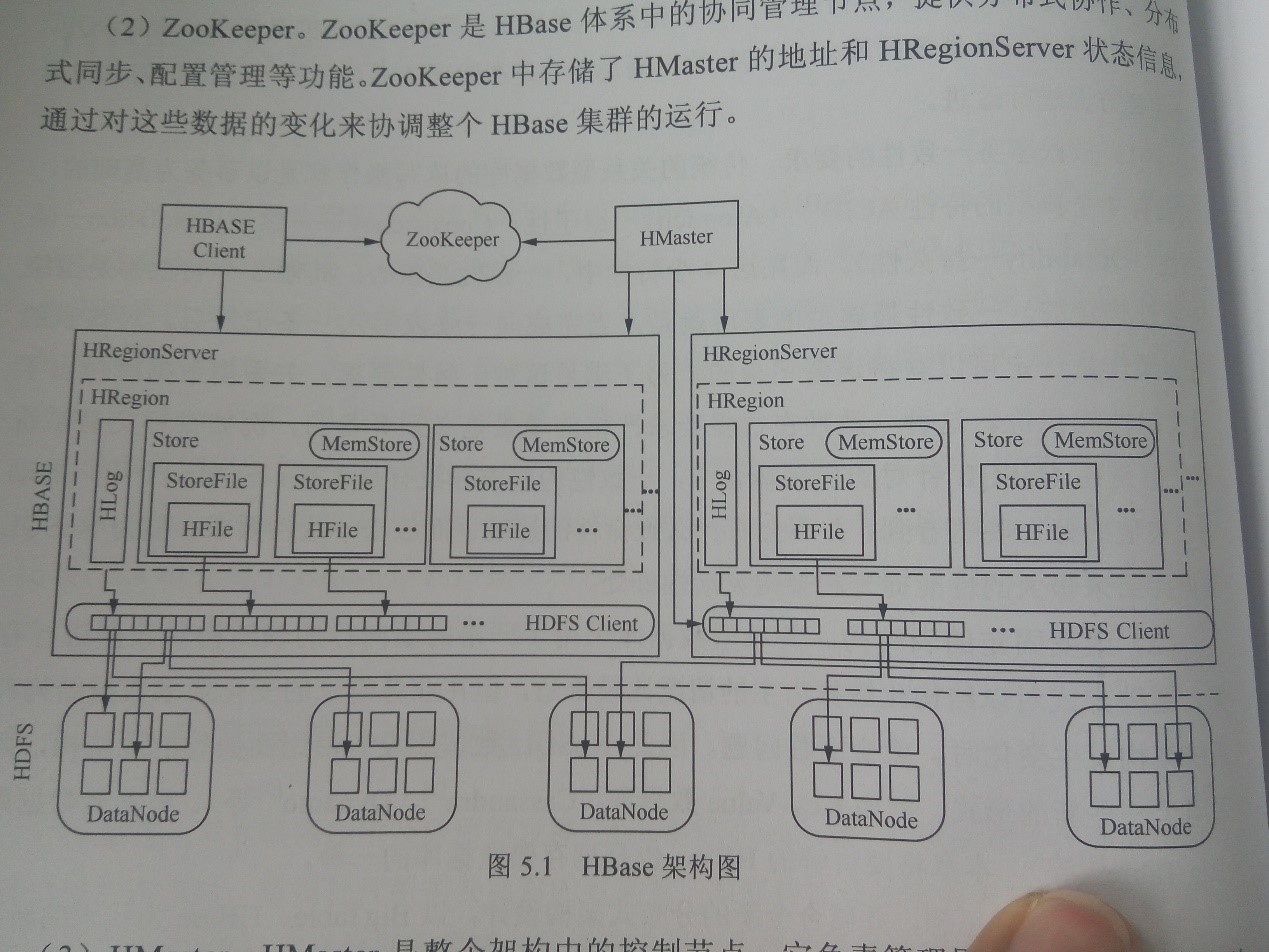
HBase�ܹ�ͼ
Hbase�ʺϺ������ݣ���20PB�����뼶��ѯ�����ݿ⡣ Hbase����ϵ�ṹ�� HRegionServer: Zookeeper:
Client����hbase�����ݵĹ��̲�����Ҫmaster���룬Ѱַ����zookeeper �� region server,���ݶ�д����regionserver��HRegionServer��Ҫ������Ӧ�û�I/O����,��HDFS�ļ�ϵͳ�ж�д���ݣ���HBase������ĵ�ģ�顣
Client�����û�����֮ǰ��Ҫ���ȷ���zookeeper,Ȼ�����-ROOT-�������ŷ���.META.�����������ҵ��û����ݵ�λ�÷��ʡ�
HBaseα�ֲ���װ��
��ѹ���������������û�������
��$HBASE_HOME/conf/hbase-env.sh�����������£�
export JAVA_HOME=/usr/local/jdk
export HBASE_MANAGES_ZK=true ��$HBASE_HOME/conf/hbase-site.xml�����������£�
<property >
<name > hbase.rootdir</name >
<value > hdfs://hadoop:9000/hbase</value >
</property >
<property >
<name > hbase.cluster.distributed</name >
<value > true</value >
</property >
<property >
<name > hbase.zookeeper.quorum</name >
<value > hadoop</value >
</property >
<property >
<name > dfs.replication</name >
<value > 1</value >
</property > (��ѡ)�ļ�regionservers�����ݸ�Ϊhadoop
����hbase��ִ������start-hbase.sh
��֤��(1)ִ��jps��������������3��java ���̣��ֱ���HMaster��HRegionServer��HQuorumPeer��֤����װ�ɹ��� http://hadoop:60010 �鿴webUI.
HBase��Ⱥ�
1.hbase�ļ�Ⱥ�����(��ԭ����hadoop�ϵ�hbaseα�ֲ������Ͻ��д)
(2)��hbase-site.xml�ļ���hbase.zookeeper.quorum��ֵΪhadoop0,hadoop1,hadoop2����dfs.replicationg��Ϊ3����ʾ������Ϊ3��
���ֵ����⼰����취��
��Ϊ�ڴ��Ⱥ��ʱ��hbase������״̬�£�����������ɣ�
��������ѧϰ��HBase�µ�shell������
HBase Shell
����hbase shell���նˣ�
hbase shell hbase shell������ ������ �� create �������ơ�, ����������1��,����������2��,����������N�� ���Ӽ�¼ �� put �������ơ�, �������ơ�, ��������:��, ��ֵ�� �鿴��¼ : get �������ơ�, �������ơ� �鿴���еļ�¼���� : count �������ơ� ɾ��һ�ű� : ��Ҫ���θñ������ܶԸñ�����ɾ���� �鿴���м�¼ : scan �������ơ� �鿴ij����ij�������������� : scan �������ơ� {COLUMNS=>����������:�����ơ�} ���¼�¼ : ������дһ����и���
eg:
create 'users' ,'user_id' ,'address' ,'info' �г�ȫ����
list �õ���������
describe 'users' ɾ������
disable ��user��
drop ��user ���Ӽ�¼��
put 'users' ,'xiaoming' ,'info:age' ,'24' ��ȡһ����¼
get 'users' ,'xiaoming' 2.��ȡһ��id��һ���������������
get 'users' ,'xiaoming' ,'info' 3.��ȡһ��id��һ��������һ���е� ��������
get 'users' ,'xiaoming' ,'info:age' ���¼�¼
put 'users' ,'xiaoming' ,'info:age' ,'29'
get 'users' ,'xiaoming' ,'info:age'
put 'users' ,'xiaoming' ,'info:age' ,'30'
get 'users' ,'xiaoming' ,'info:age' ��ȡ��Ԫ�����ݵİ汾����
get 'users' ,'xiaoming' ,{COLUMN=>'info:age' ,VERSIONS=>1 }
get 'users' ,'xiaoming' ,{COLUMN=>'info:age' ,VERSIONS=>2 }
get 'users' ,'xiaoming' ,{COLUMN=>'info:age' ,VERSIONS=>3 } ��ȡ��Ԫ�����ݵ�ij���汾����
get 'users' ,'xiaoming' ,{COLUMN=>'info:age' ,TIMESTAMP=>1364874937056 } ȫ��ɨ��
scan 'users' �������ж��Ǹ����н����жϵ�
HBase �в������ݵķ�ʽ ��
ɾ��xiaomingֵ�ġ�info:age���ֶ�
delete 'users' ,'xiaoming' ,'info:age'
get 'users' ,'xiaoming' HBase�У�put��̬���� delete��̬����
deleteall 'users' ,'xiaoming' ͳ�Ʊ�������
count 'users' ��ձ�
truncate 'users' ����£��������ǿ��¹���Java���HBase�IJ��������ʱ��java ����ԱӦ���˷ܲ��ǣ�����
HBase��Java_API����
package hbase;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
public class HBaseApp {private static final String TABLE_NAME = "table1" ;
private static final String FAMILY_NAME = "family1" ;
private static final String ROW_KEY = "rowkey1" ;
public static void main (String[] args) throws Exception {
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.rootdir" , "hdfs://hadoop:9000/hbase" );
conf.set("hbase.zookeeper.quorum" , "hadoop" );
final HBaseAdmin hBaseAdmin = new HBaseAdmin(conf);
createTable(hBaseAdmin);
final HTable hTable = new HTable(conf, TABLE_NAME);
scanTable(hTable);
}
private static void scanTable (final HTable hTable) throws IOException {
Scan scan = new Scan();
final ResultScanner scanner = hTable.getScanner(scan);
for (Result result : scanner) {
final byte [] value = result.getValue(FAMILY_NAME.getBytes(),"age" .getBytes());
System.out.println(result + "\t" + new String(value));
}
}
private static void getRecord (final HTable hTable) throws IOException {
Get get = new Get(ROW_KEY.getBytes());
final Result result = hTable.get(get);
final byte [] value = result.getValue(FAMILY_NAME.getBytes(),"age" .getBytes());
System.out.println(result + "\t" + new String(value));
}
private static void putRecord (final HTable hTable) throws IOException {
Put put = new Put(ROW_KEY.getBytes());
put.add(FAMILY_NAME.getBytes(), "age" .getBytes(), "25" .getBytes());
hTable.put(put);
hTable.close();
}
private static void deleteTable (final HBaseAdmin hBaseAdmin)
throws IOException {
hBaseAdmin.disableTable(TABLE_NAME);
hBaseAdmin.deleteTable(TABLE_NAME);
}
private static void createTable (final HBaseAdmin hBaseAdmin)
throws IOException {
if (!hBaseAdmin.tableExists(TABLE_NAME)){
HTableDescriptor descriptor = new HTableDescriptor(TABLE_NAME);
HColumnDescriptor family = new HColumnDescriptor(FAMILY_NAME);
descriptor.addFamily(family);
hBaseAdmin.createTable(descriptor);
}
}
}2 >:
hdfs�����������뵽hbase��
create 'wlan_log' , 'cf'
package hbase;
import java.text.SimpleDateFormat;
import java.util.Date;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.mapreduce.TableOutputFormat;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Counter;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
public class BatchImport {class BatchImportMapper extends Mapper <LongWritable , Text , LongWritable , Text >{new SimpleDateFormat("yyyyMMddHHmmss" );
Text v2 = new Text();
protected void map(LongWritable key, Text value, Context context) throws java.io.IOException ,InterruptedException {
final String[] splited = value.toString().split("\t" );
try {
final Date date = new Date(Long.parseLong(splited[0 ].trim()));
final String dateFormat = dateformat1.format(date);
String rowKey = splited[1 ]+":" +dateFormat;
v2.set(rowKey+"\t" +value.toString());
context.write(key, v2);
} catch (NumberFormatException e) {
final Counter counter = context.getCounter("BatchImport" , "ErrorFormat" );
counter.increment(1 L);
System.out.println("������" +splited[0 ]+" " +e.getMessage());
}
};
}
static class BatchImportReducer extends TableReducer <LongWritable , Text , NullWritable >{protected void reduce(LongWritable key, java.lang.Iterable<Text> values, Context context) throws java.io.IOException ,InterruptedException {
for (Text text : values) {
final String[] splited = text.toString().split("\t" );
final Put put = new Put(Bytes.toBytes(splited[0 ]));
put.add(Bytes.toBytes("cf" ), Bytes.toBytes("date" ), Bytes.toBytes(splited[1 ]));
put.add(Bytes.toBytes("cf" ), Bytes.toBytes("msisdn" ), Bytes.toBytes(splited[2 ]));
context.write(NullWritable.get(), put);
}
};
}
public static void main(String[] args) throws Exception {
final Configuration configuration = new Configuration();
configuration.set("hbase.zookeeper.quorum" , "hadoop" );
configuration.set(TableOutputFormat.OUTPUT_TABLE, "wlan_log" );
configuration.set("dfs.socket.timeout" , "180000" );
final Job job = new Job(configuration, "HBaseBatchImport" );
job.setMapperClass(BatchImportMapper.class );
job.setReducerClass(BatchImportReducer.class );
job.setMapOutputKeyClass(LongWritable.class );
job.setMapOutputValueClass(Text.class );
job.setInputFormatClass(TextInputFormat.class );
job.setOutputFormatClass(TableOutputFormat.class );
FileInputFormat.setInputPaths(job, "hdfs://hadoop:9000/input" );
job.waitForCompletion(true );
}
}