�������ϸ�˽�hbase�İ�װ��http://abloz.com/hbase/book.html ����http://hbase.apache.org/
1. ���ٵ�����װ
�ڵ�����װHbase�ķ�������������ͨ��shell����һ����������һ�У�Ȼ��ɾ���������ֹͣHbase��ֻҪ10���ӾͿ���������µIJ�����
1.1���ؽ�ѹ���°汾
������Ҫ��װ��Ⱥ�����ϵ�hadoop������ע��ѡ����hadoop��Ӧ�İ汾��
ѡ�� Hadoop �汾��HBase����ܹؼ����±���ʾ��ͬHBase֧�ֵ�Hadoop�汾��Ϣ������HBase�汾��Ӧ��ѡ����ʵ�Hadoop�汾������û�а� Hadoop ���а�ѡ���Դ�Apacheʹ�� Hadoop ���а棬���˽�һ��Hadoop�����̲�Ʒ��http://wiki.apache.org/hadoop/Distributions%20and%20Commercial%20Support
Table2.1.Hadoop version support matrix
| HBase-0.92.x | HBase-0.94.x | HBase-0.96 |
|---|
| Hadoop-0.20.205 | S | X | X |
| Hadoop-0.22.x | S | X | X |
| Hadoop-1.0.x | S | S | S |
| Hadoop-1.1.x | NT | S | S |
| Hadoop-0.23.x | X | S | NT |
| Hadoop-2.x | X | S | S |
| S = supported and tested,֧�� |
| X = not supported,��֧�� |
| NT = not tested enough.�������е����Բ���� |
���� HBase ���� Hadoop������������һ��Hadoop jar �ļ�������lib�¡�����װjar�����ڶ���ģʽ���ڷֲ�ʽģʽ�£�Hadoop�汾�����HBase�µİ汾һ�¡��������еķֲ�ʽHadoop�汾jar�ļ��滻HBase libĿ¼�µ�Hadoop jar�ļ����Ա���汾��ƥ�����⡣ȷ���滻�˼�Ⱥ������HBase�µ�jar�ļ���Hadoop�汾��ƥ�������в�ͬ���֣�������������ҵ��ˡ�
��װ��
$ tar xfz hbase-0.90.4.tar.gz
$ cd hbase-0.90.4 �������Ѿ���������Hbase�ˡ������������Ҫ�ȱ༭conf/hbase-site.xmlȥ����hbase.rootdir����ѡ��Hbase������д���ĸ�Ŀ¼ .
�������ã�ֻ��Ҫ��������hbase-site.xml��
<xml version="1.0"><xml-stylesheet type="text/xsl" href="configuration.xsl"><configuration> <property> <name>hbase.rootdir</name> <value>file:///DIRECTORY/hbase</value> </property></configuration>
��DIRECTORY�滻��������д�ļ���Ŀ¼. Ĭ��hbase.rootdir��ָ��/tmp/hbase-${user.name}��Ҳ��˵�����������ʧ����(������ʱ�����ϵͳ������/tmpĿ¼)
1.2.���� HBase
��������Hbase:
$ ./bin/start-hbase.sh
starting Master, logging to logs/hbase-user-master-example.org.out
���������е��ǵ���ģʽ��Hbaes�����Եķ���������һ��JVM�ϣ�����Hbase��Zookeeper��Hbase����־����logsĿ¼,���������������ʱ���Լ�������־��
1.3.Hbase Shell ��ϰ
��shell�������Hbase
$ ./bin/hbase shell
HBase Shell; enter 'help<RETURN>' for list of supported commands.
Type "exit<RETURN>" to leave the HBase Shell
Version: 0.90.0, r1001068, Fri Sep 24 13:55:42 PDT 2010
hbase(main):001:0>
����helpȻ��<RETURN>���Կ���һ��shell�������İ�������ϸ��Ҫע����DZ������к�����Ҫ�����š�
����һ����Ϊtest�ı��������ֻ��һ��column family Ϊcf�������г����еı�����鴴�������Ȼ�����Щֵ��
hbase(main):003:0> create 'test', 'cf'
0 row(s) in 1.2200 seconds
hbase(main):003:0> list 'table'
test
1 row(s) in 0.0550 seconds
hbase(main):004:0> put 'test', 'row1', 'cf:a', 'value1'
0 row(s) in 0.0560 seconds
hbase(main):005:0> put 'test', 'row2', 'cf:b', 'value2'
0 row(s) in 0.0370 seconds
hbase(main):006:0> put 'test', 'row3', 'cf:c', 'value3'
0 row(s) in 0.0450 seconds
�������Ƿֱ������3�С���һ����keyΪrow1, ��Ϊcf:a�� ֵ��value1��Hbase�е������� column familyǰ���е�������ɵģ���ð�ż����������һ�е���������a.
���������.
Scan���������������
hbase(main):007:0> scan 'test'
ROW COLUMN+CELL
row1 column=cf:a, timestamp=1288380727188, value=value1
row2 column=cf:b, timestamp=1288380738440, value=value2
row3 column=cf:c, timestamp=1288380747365, value=value3
3 row(s) in 0.0590 seconds
Getһ�У���������
hbase(main):008:0> get 'test', 'row1'
COLUMN CELL
cf:a timestamp=1288380727188, value=value1
1 row(s) in 0.0400 seconds
disable �� drop ���ű������������ոյIJ���
hbase(main):012:0> disable 'test'
0 row(s) in 1.0930 seconds
hbase(main):013:0> drop 'test'
0 row(s) in 0.0770 seconds
�ر�shell
1.4.ֹͣ HBase
����ֹͣ�ű���ֹͣHBase.
$ ./bin/stop-hbase.sh
stopping hbase...............
1��Java����hadoop�Ѿ���װ�ˣ�
2��Hadoop 0.20.x/ Hadoop-2.x�Ѿ���ȷ��װ�����ҿ������� HDFS ϵͳ, �ɲο���Hadoop��װ�ĵ���Hadoop��Ⱥ���ã���ȫ���ܽᣩhttp://blog.csdn.net/hguisu/article/details/7237395
3��ssh ���밲װssh��sshdҲ�������У�����Hadoop�Ľű��ſ���Զ�̲ٿ�������Hadoop��Hbase���̡�ssh֮����붼��ͨ���������붼���Ե�¼����ϸ�������� Googleһ�� ("ssh passwordless login").
4��NTP����Ⱥ��ʱ��Ҫ��֤������һ�¡����в�һ���ǿ������̵ģ����Ǻܴ�IJ�һ�»� �����ֵ���Ϊ�� ����NTP��������ʲô������ͬ�����ʱ��.
������ѯ��ʱ�������������ֵĹ��ϣ����Լ��һ��ϵͳʱ���Ƿ���ȷ!
���ü�Ⱥ�����ڵ�ʱ�ӣ�date -s��2012-02-13 14:00:00��
5��ulimit��nproc:
Base�����ݿ⣬����ͬһʱ��ʹ�úܶ���ļ�����������linuxϵͳʹ�õ�Ĭ��ֵ1024�Dz�������ģ��ᵼ��FAQ: Why do I see "java.io.IOException...(Too manyopen files)" in my logs�쳣�������ܻᷢ���������쳣
2010-04-06 03:04:37,542 INFO org.apache.hadoop.hdfs.DFSClient: ExceptionincreateBlockOutputStream java.io.EOFException
2010-04-06 03:04:37,542 INFO org.apache.hadoop.hdfs.DFSClient:Abandoning block blk_-6935524980745310745_1391901
��������Ҫ���������ļ�������ơ��������õ�10k. �㻹��Ҫ�� hbase �û��� nproc��������ͻ���� OutOfMemoryError�쳣�� [2] [3].
��Ҫ����ģ���������������Բ���ϵͳ�ģ�����Hbase�����ġ���һ�������Ĵ�����Hbase���е��û������������ֵ���û�����һ���û�����Hbase������ʱ��һ����־������ulimit��Ϣ����������ü��һ�¡�
�����Ȳ鿴��ǰ�û�ulimit��
ulimit -n
����ulimit:
�����ʹ�õ���Ubuntu,�������������:
���ļ�/etc/security/limits.conf����һ�У���:
hadoop - nofile32768
����hadoop�滻��������Hbase��Hadoop���û���������������û��������Ҫ��������������nproc hard �� softlimits. ��:
hadoop soft/hard nproc 32000
��/etc/pam.d/common-session������һ��:
session requiredpam_limits.so
������/etc/security/limits.conf�ϵ����ò�����Ч.
����ע���ٵ�¼����Щ���ò�����Ч!
7 ����Hadoop HDFS Datanodeͬʱ�����ļ������ޣ�dfs.datanode.max.xcievers
һ�� Hadoop HDFS Datanode ��һ��ͬʱ�����ļ�������. ���������xcievers(Hadoop�����߰��������ƴ����). �������֮ǰ����ȷ��������û����������ļ�conf/hdfs-site.xml�����xceivers����������Ҫ��4096:
<property>
<name>dfs.datanode.max.xcievers</name>
<value>4096</value>
</property>
����HDFS������Ҫ�ǵ�����.
���û����һ�����ã�����ܻ�������ֵ�ʧ�ܡ������Datanode����־�п���xcievers exceeded���������������ᱨ missing blocks��������:02/12/1220:10:31 INFO hdfs.DFSClient: Could not obtain blockblk_XXXXXXXXXXXXXXXXXXXXXX_YYYYYYYY from any node: java.io.IOException: No livenodes contain current block.Will get new block locations from namenode andretry...
8���̳�hadoop��װ��˵����
ÿ������/etc/hosts
10.64.56.74 node2 ��master��
10.64.56.76 node1 ��slave��
10.64.56.77 node3 ��slave��
9) ����ʹ��hadoop�û���װ
Chown �CR hadoop /usr/local/hbase
3.1����conf/hbase-env.sh
# exportJAVA_HOME=/usr/java/jdk1.6.0/
exportJAVA_HOME=/usr/lib/jvm/java-6-sun-1.6.0.26
# Tell HBase whether it should manage it'sown instance of Zookeeper or not.
export HBASE_MANAGES_ZK=true
������ʲôģʽ���㶼��Ҫ�༭conf/hbase-env.sh����֪Hbasejava�İ�װ·��.������ļ����㻹��������Hbase�����л��������� heapsize������JVM�йص�ѡ��, ����Log�ļ���ַ���ȵ�. ����JAVA_HOMEָ��java��װ��·��.
һ���ֲ�ʽ���е�Hbase����һ��zookeeper��Ⱥ�����еĽڵ�Ϳͻ��˶������ܹ�����zookeeper��Ĭ�ϵ������Hbase�����һ��zookeep��Ⱥ�������Ⱥ������Hbase����������������Ȼ����Ҳ�����Լ�����һ��zookeeper��Ⱥ������Ҫ����Hbase������Ҫ��conf/hbase-env.sh�����HBASE_MANAGES_ZK���л������ֵĬ����true�ģ���������Hbase������ʱ��ͬʱҲ����zookeeper.
��Hbaseʹ��һ�����еIJ���Hbase�йܵ�Zookeep��Ⱥ����Ҫ����conf/hbase-env.sh�ļ��е�HBASE_MANAGES_ZK����Ϊ false
# Tell HBase whether it should manage it's own instanceof Zookeeper or not.
exportHBASE_MANAGES_ZK=false
3.2 ����conf/hbase-site.xml
<configuration> <property> <name>hbase.rootdir</name> <value>hdfs://node1:49002/hbase</value> <description>The directory shared byRegionServers. </description> </property> <property> <name>hbase.cluster.distributed</name> <value>true</value> <description>The mode the clusterwill be in. Possible values are false: standalone and pseudo-distributedsetups with managed Zookeeper true: fully-distributed with unmanagedZookeeper Quorum (see hbase-env.sh) </description> </property> <property> <name>hbase.zookeeper.property.clientPort</name> <value>2222</value> <description>Property fromZooKeeper's config zoo.cfg. The port at which the clients willconnect. </description> </property> <property> <name>hbase.zookeeper.quorum</name> <value>node1,node2,node3</value> <description>Comma separated listof servers in the ZooKeeper Quorum. For example,"host1.mydomain.com,host2.mydomain.com,host3.mydomain.com". By default this is set to localhost forlocal and pseudo-distributed modes of operation. For a fully-distributedsetup, this should be set to a full list of ZooKeeper quorum servers. IfHBASE_MANAGES_ZK is set in hbase-env.sh this is the list of servers which we willstart/stop ZooKeeper on. </description> </property> <property> <name>hbase.zookeeper.property.dataDir</name> <value>/home/hadoop/zookeeper</value> <description>Property fromZooKeeper's config zoo.cfg. The directory where the snapshot isstored. </description> </property> </configuration>
Ҫ��������ȫ�ֲ�ʽģʽ����һ������hbase.cluster.distributed����ΪtrueȻ���hbase.rootdir����ΪHDFS��NameNode��λ�á� ���磬���namenode������node1���˿���49002 ��������Ŀ¼��/hbase,ʹ�����µ����ã�hdfs://node1:49002/hbase
hbase.rootdir�����Ŀ¼��region server�Ĺ���Ŀ¼�������־û�Hbase��URL��Ҫ��'��ȫ��ȷ'�ģ���Ҫ�����ļ�ϵͳ��scheme�����磬Ҫ��ʾhdfs�е�'/hbase'Ŀ¼��namenode ������node1��49002�˿ڡ�����Ҫ����Ϊhdfs://node1:49002/hbase��Ĭ�������Hbase��д��/tmp�ġ�����������ã����ݻ���������ʱ��ʧ��Ĭ��:file:///tmp/hbase-${user.name}/hbase
hbase.cluster.distributed ��Hbase������ģʽ��false�ǵ���ģʽ��true�Ƿֲ�ʽģʽ����Ϊfalse,Hbase��Zookeeper��������ͬһ��JVM���档
Ĭ��:false
��hbase-site.xml����zookeeper��
��Hbase����zookeeper��ʱ�������ͨ����zoo.cfg������zookeeper��
һ�����Ӽķ�������conf/hbase-site.xml������zookeeper�����á�Zookeeer����������Ϊpropertyд��hbase-site.xml����ġ�
����zookeepr��������������Ҫ��hbase-site.xml���г�zookeepr��ensemble servers��������ֶ���hbase.zookeeper.quorum. ������ֶε�Ĭ��ֵ��localhost�����ֵ���ڷֲ�ʽӦ����Ȼ�Dz����Ե�. (Զ��������ʹ��)��
hbase.zookeeper.property.clientPort��ZooKeeper��zoo.conf�е����á� �ͻ������ӵĶ˿ڡ�
hbase.zookeeper.quorum��Zookeeper��Ⱥ�ĵ�ַ�б����ö��ŷָ���磺"host1.mydomain.com,host2.mydomain.com,host3.mydomain.com".Ĭ����localhost,�Ǹ�α�ֲ�ʽ�õġ�Ҫ�IJ�������ȫ�ֲ�ʽ�������ʹ�á������hbase-env.sh������HBASE_MANAGES_ZK����ЩZooKeeper�ڵ�ͻ��Hbaseһ��������
Ĭ��:localhost
����һ��zookeeperҲ�ǿ��Եģ����������������У�����ò���3��5��7���ڵ㡣�����Խ�࣬�ɿ��Ծ�Խ�ߣ���Ȼֻ�ܲ�����������ż�����Dz����Եġ�����Ҫ��ÿ��zookeeper 1G���ҵ��ڴ棬������ܵĻ�������ж����Ĵ��̡� (�������̿���ȷ��zookeeper�Ǹ����ܵġ�).�����ļ�Ⱥ���غ��أ���Ҫ��Zookeeper��RegionServer������ͬһ̨�������档����DataNodes �� TaskTrackersһ��
hbase.zookeeper.property.dataDir��ZooKeeper��zoo.conf�е����á� ���յĴ洢λ��
��ZooKeeper�������ݵ�Ŀ¼��ַ�ĵ���Ĭ��ֵ��/tmp��������������ʱ��ᱻ����ϵͳɾ�����������ĵ�/home/hadoop/zookeeper (���·��hadoop�û�ӵ�в���Ȩ��)
���ڶ�����Zookeeper��Ҫָ��Zookeeper��host�Ͷ˿ڡ�������hbase-site.xml������, Ҳ������Hbase��CLASSPATH�����һ��zoo.cfg�����ļ��� HBase �����ȼ���zoo.cfg��������ã���hbase-site.xml����ĸ��ǵ�.
�μ�http://www.yankay.com/wp-content/hbase/book.html#hbase_default_configurations���Բ���hbase.zookeeper.propertyǰ���ҵ�����zookeeper�����á�
3.3 ����conf/regionservers
Node1
Node2
��ȫ�ֲ�ʽģʽ�Ļ���Ҫ��conf/regionservers.�������г�����ϣ�����е�ȫ��HRegionServer��һ��дһ��host (����Hadoop�����slavesһ��). ���������server�����ż�Ⱥ����������������Ⱥ��ֹͣ��ֹͣ.
3.4 �滻hadoop��jar��
hbase�������������ˡ�
�鿴hbase��libĿ¼�¡�
ls lib |grep hadoop
hadoop-annotations-2.1.0-beta.jar
hadoop-auth-2.1.0-beta.jar
hadoop-client-2.1.0-beta.jar
hadoop-common-2.1.0-beta.jar
hadoop-hdfs-2.1.0-beta.jar
hadoop-hdfs-2.1.0-beta-tests.jar
hadoop-mapreduce-client-app-2.1.0-beta.jar
hadoop-mapreduce-client-common-2.1.0-beta.jar
hadoop-mapreduce-client-core-2.1.0-beta.jar
hadoop-mapreduce-client-jobclient-2.1.0-beta.jar
hadoop-mapreduce-client-jobclient-2.1.0-beta-tests.jar
hadoop-mapreduce-client-shuffle-2.1.0-beta.jar
hadoop-yarn-api-2.1.0-beta.jar
hadoop-yarn-client-2.1.0-beta.jar
hadoop-yarn-common-2.1.0-beta.jar
hadoop-yarn-server-common-2.1.0-beta.jar
hadoop-yarn-server-nodemanager-2.1.0-beta.jar
�������ǻ���hadoop2.1.0�ģ�����������Ҫ�����ǵ�hadoop2.2.0�µ�jar�����滻2.1�ģ���֤�汾��һ���ԣ�hadoop�µ�jar��������$HADOOP_HOME/share/hadoop�µ�.
������cd �� /home/hadoop/hbase-0.96.0-hadoop2/lib��������� rm -rf hadoop*.jarɾ�����е�hadoop��ص�jar����Ȼ�����У�
find /home/hadoop/hadoop-2.2.0/share/hadoop -name "hadoop*jar" | xargs -i cp {}/home/hadoop/hbase-0.96.0-hadoop2/lib/
��������hadoop2.2.0�µ�jar��hbase�½���hadoop�汾��ͳһ
4. ���к�ȷ�ϰ�װ
4.1��Hbase�й�ZooKeeper��ʱ��
��Hbase�й�ZooKeeper��ʱ��Zookeeper��Ⱥ��������Hbase�����ű���һ����
����ȷ�����HDFS�������ŵġ����������HADOOP_HOME�е�bin/start-hdfs.sh������HDFS.�����ͨ��put���������Է�һ���ļ���Ȼ����get������������ļ���ͨ�������Hbase�Dz�������mapreduce�ġ����ԱȲ���Ҫ�����Щ��
��������������Hbase:
bin/start-hbase.sh
����ű���HBASE_HOMEĿ¼���档
�������Ѿ�����Hbase�ˡ�Hbase��log����logs��Ŀ¼����. ��Hbase�����������ʱ���Կ���Log.
HbaseҲ��һ�����棬������г���Ҫ�����ԡ�Ĭ������Master��60010�˿���H (HBase RegionServers ��Ĭ�ϰ� 60020�˿ڣ��ڶ˿�60030����һ��չʾ��Ϣ�Ľ��� ).���Master������node1���˿���Ĭ�ϵĻ�����������������http://node:60010����������. .
һ��Hbase���������Կ�����ν������������ݣ�scan��ı�������disable�������������ɾ����
������Hbase ShellֹͣHbase
$./bin/stop-hbase.sh
stoppinghbase...............
ֹͣ������ҪһЩʱ�䣬��ļ�ȺԽ��ͣ��ʱ����ܻ�Խ�����������������һ���ֲ�ʽ�IJ�����Ҫȷ����Hbase����ֹ֮ͣǰ��Hadoop����ͣ.
4.2������zookeeper������
��������habse��
ִ�У�bin/start-hbase.sh����habse
����Ҫ�Լ�ȥ����zookeeper��
${HBASE_HOME}/bin/hbase-daemons.sh {start,stop} zookeeper
�������������������ZooKeeper��������Hbase.HBASE_MANAGES_ZK��ֵ��false�� ���������Hbase������ʱ������ZooKeeper,�����������
5. ����
����ʹ��jps�鿴���̣���master�ϣ�
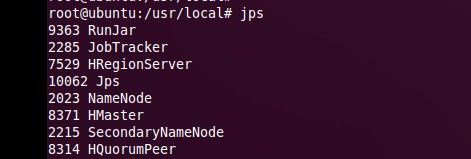
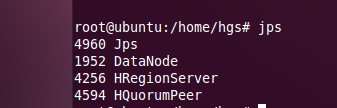
��node2��node3��slave�ڵ㣩��
ͨ��������鿴60010�˿ڣ�
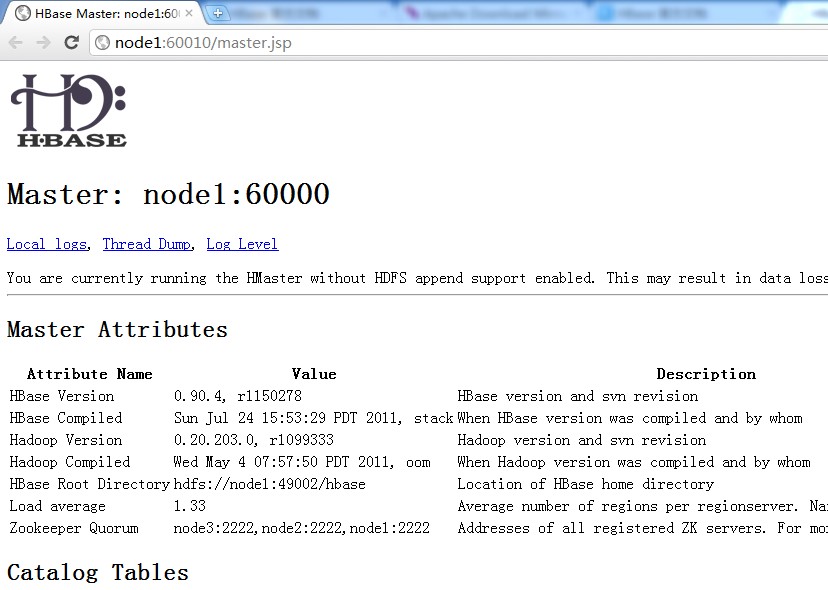
1 ��
��./start-hbase.sh����HBase��ִ��hbase shell
# bin/hbase shell
HBase Shell; enter 'help<RETURN>' for list of supported commands.
Version: 0.20.6, rUnknown, Thu Oct 28 19:02:04 CST 2010
���Ŵ�����ʱ��������������hbase(main):001:0> create 'test',''c
NativeException: org.apache.hadoop.hbase.MasterNotRunningException: null
jps�£��������ڵ���HMasterû������������HBase log��logs/hbase-hadoop-master-ubuntu.log�����������쳣��
FATAL org.apache.hadoop.hbase.master.HMaster: Unhandled exception. Starting shutdown.
java.io.IOException: Call to node1/10.64.56.76:49002 failed on local exception: java.io.EOFException
�����
��hadoop_home/����cpһ��hadoop/hadoop-core-0.20.203.0.jar��hbase_home/lib�¡�
��ΪHbase������Hadoop֮�ϣ��������õ���hadoop.jar,���Jar�� lib ���档���jar��hbase�Լ�����branch-0.20-append ������hadoop.jar. Hadoopʹ�õ�hadoop.jar��Hbaseʹ�õ� ���� һ�¡���������Ҫ�� Hbaselib Ŀ¼�µ�hadoop.jar�滻��Hadoop������Ǹ�����ֹ�汾��ͻ���ȷ�˵CDH�İ汾û��HDFS-724��branch-0.20-append�����У����HDFS-724��������RPCЭ�顣������滻���ͻ��а汾��ͻ���̶�������صij�����Hadoop�ῴ�������ˡ�
����./start-hbase.sh����HBase��jps�£��������ڵ���HMaster����û����������HBase log���������쳣��
FATAL org.apache.hadoop.hbase.master.HMaster: Unhandled exception. Starting shutdown.
java.lang.NoClassDefFoundError: org/apache/commons/configuration/Configuration
�����
��NoClassDefFoundError,ȱ�� org/apache/commons/configuration/Configuration
���ϸ�����һ��commons-configuration����
��hadoop_home/lib����cpһ��hadoop/lib/commons-configuration-1.6.jar��hbase_home/lib�¡�
����Ⱥ�����л��ӵ�hbase���ö���Ҫһ����
������������
ERROR: java.io.IOException: Table Namespace Manager not ready yet, try again later
at org.apache.hadoop.hbase.master.HMaster.getNamespaceDescriptor(HMaster.java:3101)
at org.apache.hadoop.hbase.master.HMaster.createTable(HMaster.java:1738)
at org.apache.hadoop.hbase.master.HMaster.createTable(HMaster.java:1777)
at org.apache.hadoop.hbase.protobuf.generated.MasterProtos$MasterService$2.callBlockingMethod(MasterProtos.java:38221)
at org.apache.hadoop.hbase.ipc.RpcServer.call(RpcServer.java:2146)
at org.apache.hadoop.hbase.ipc.RpcServer$Handler.run(RpcServer.java:1851)
�����
1�� �鿴��Ⱥ�����л����ϣ�
HRegionServer��HQuorumPeer�����Ƿ�������
2���鿴��Ⱥ�����л�����logs�Dz����д�����Ϣ��
tail -fhbase-hadoop-regionserver-XXX..log
2 ע�����
1����������hadoop���ٿ���hbase
2����ȥ��hadoop�İ�ȫģʽ��hadoop dfsadmin -safemode leave
3������/etc/hosts���ubuntu��IP��Ϊ��������ǰ��IP
4) ��ȷ��hbase��hbase-site.xml��
<name>hbase.rootdir</name>
<value>hdfs://node��49002/hbase</value> ��hadoop��core-site.xml��
<name>fs.default.name</name>
<value>hdfs://node��49002/hbase</value> ���ֲ��ֱ���һ��
<value>hdfs://localhost:8020/hbase</value>
������java.lang.RuntimeException: HMaster Aborted
6)������ִ��./start-hbase.sh֮ǰ����kill����ǰ��hbase��zookeeper����
7��hostsע��˳��
192.168.1.214 master
192.168.1.205 node1
192.168.1.207 node2
192.168.1.209 node3
192.168.1.205 T205.joy.cc
PS����������ʱ���Ȳ鿴logs�����а�����
HBase �ٷ��ĵ���ȫ�����hbase��װ���ã�
http://www.yankay.com/wp-content/hbase/book.html#hbase_default_configurations
��ã� �������һ��ʹ�� **Markdown�༭��** ��չʾ�Ļ�ӭҳ���������ѧϰ���ʹ��Markdown�༭��, ������ϸ�Ķ���ƪ���£��˽�һ��Markdown�Ļ����֪ʶ��
���Ƕ�Markdown�༭��������һЩ������չ���֧�֣����˱���Markdown�༭�����ܣ��������������¼����¹��ܣ�����������д���ͣ�

