��Ȩ����������Ϊ����ԭ�����£���ӭת�أ�SuperMap�����ʴ����� http://ask.supermap.com https://blog.csdn.net/supermapsupport/article/details/83783192
HBase��һ�����Hadoop�ļ�ϵͳ֮�ϵĿ�Դ�ķֲ�ʽ�����е����ݿ⣬���ú�����չ�ܹ���HBase��һ������ģ�ͣ������ڹȸ�Ĵ����ƣ������ṩ����������ʺ����ṹ�����ݣ���������Hadoop���ļ�ϵͳ��HDFS���ṩ���ݴ�������HBase��ΪHadoop�ļ�ϵͳ��һ���֣��ṩ�˶����ݵ����ʵʱ��/д���ʡ����ǿ���ͨ��HBase�Դ����ݽ��������ʵʱ��/д���ʡ�
��3̨���������װubuntu-15.10����ϵͳ��һ̨��Ϊ��Ⱥ�����ڵ㣨master����������̨��Ϊ�����ڵ㣨worker��������ʹ�õ���̨�豸��IP�ֱ�Ϊ��
��ÿ̨�豸�а�װJDK�����ص�ַΪhttps://www.oracle.com/technetwork/java /java se/downloads/index.html�����Ľ���������װjdk-8u111-linux-x64.tar.gz���������£�
��ѹtar -zxvf jdk-8u111-linux-x64.tar.gz
�ƶ���ָ��Ŀ¼����ѡ����
���û���������
ʹ�ĵ�����������Ч��
����汾�鿴������ɼ���Ƿ�װ�ɹ���
��etc/hostname�����ø��ڵ��Լ���hostname���������ڵ��IP��hostname���ӵ����ڵ��etc/hosts�ļ��С�
�������ܵ�¼
��master�ڵ��а�װHadoop����ȡHadoop�ĵ�ַ��http://archive.apache.org/dist/hadoop/core/ ��ѹ�����Ľ�Hadoop��ѹ��/home/Hbase/hadoop-2.7.3����������./�����Ŀ¼�����ɸ���ʵ��������е�����
��hadoop-2.7.3�ļ��������½�4���ļ��У��ֱ�Ϊ��
���� hadoop
����mapred-site.xml.template�ļ���������Ϊmapred-site.xml��
�༭mapred-site.xml��
����yarn-site.xml��
����slaves�ļ���
����masters�ļ���
����hadoop�Ļ���������ͬJDK���ơ����ȱ༭�����ļ���
����������hadoop����worker1��worker2�ڵ��е���ͬĿ¼�У�
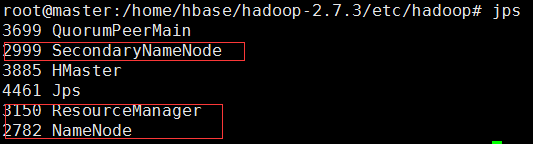
��ʼ��hadoop
����hadoop
��֤��Ⱥ�Ƿ��ɹ�http://192.168.13.105:50070 ���������½��棬hadoop��Ⱥ��ɹ���
����HBaseĿ¼
ZooKeeper��һ��Ϊ�ֲ�ʽӦ���ṩһ���Է������������Hadoop��Hbase����Ҫ�������ܹ�ͼ���£�
����zookeeper����ѹ�����Ľ�ѹĿ¼��/home/hbase
��zookeeper�������ļ�������������Ŀ¼����־Ŀ¼����Ŀ¼��/home/hbase��
����master��zookeeper-3.4.10��worker1��worker2�ϣ�
�ֱ���worker1��worker2��myid��ֵΪ2��3
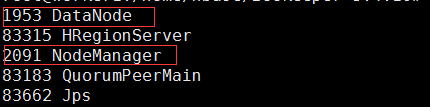
�ֱ�����master��worker1��worker2�ϵ�zookeeper
�鿴zookeeper��״̬
��֤zookeeper��Ⱥ
��ѹ��hbase�������������Ľ�ѹĿ¼Ϊ��/home/hbase��ʹ�����
���û�������
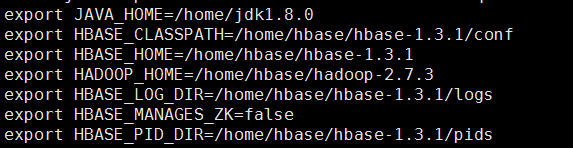
����hbase������Ŀ¼����hbase-env.sh�ļ���·����./hbase-1.3.1/conf��
�༭hbase-site.xml �����������ļ���
�༭����Ŀ¼������ļ�regionservers. ���
��HBase���Ƶ������������������£�����/home/hbaseĿ¼�£�
��master��������hbase�����������£�
����iServer���ڻ�����hosts�ļ�������HBase��Ⱥ������ip�Ͷ˿ڣ�����Ϊ��
����geomesa-hbase-distributed-runtime_2.11-2.0.2.jar��������HBase��Ⱥ��װĿ¼./lib�£�����HBase��Ⱥ�����ص�ַ��https://mvnrepository.com/artifact/org.locationtech.geomesa/geomesa-hbase-distributed-runtime_2.11/2.0.2
��ѹiServer����ע��HBase���ݿ�����ע���hbase���ݿ������༭��ע��ɹ�������ͼ��ʾ��
�����ݵ��뵽hbase�С����ȣ���Ҫ���÷ֲ�ʽ���������ò���ο�https://blog.csdn.net/supermapsupport/article/details/81740689����ʹ�����ݿ������ܣ������ݵ��뵽HBase�С�����ɹ�������ͼ��ʾ��
����hbase�е�����ΪiServer ����ѡ����ٷ���->HBase����->��д�����ַ�����ݿ��ַ->��һ��->ѡ��Ҫ�����ķ���
�������hbase�е�����Ϊ��ͼ�����������õ�ͼstyle