版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/bocai8058/article/details/81464103
@Author : Spinach | GHB
@Link : http://blog.csdn.net/bocai8058
概念
LSM树全称是基于日志结构的合并树(Log-Structured Merge-Tree)。
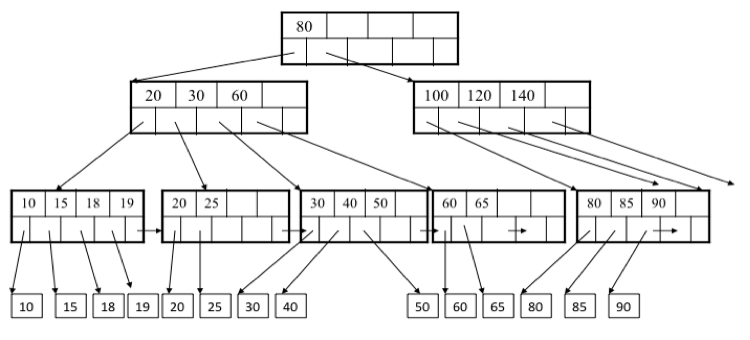
No-SQL数据库一般采用LSM树作为数据结构,HBase也不例外。众所周知,RDBMS一般采用B+树作为索引的数据结构,如图1。RDBMS中的B+树一般是3层n路的平衡树。B+树的节点对应于磁盘数据块。因此对于RDBMS,数据更新操作需要5次磁盘操作(从B+树3次找到记录所在数据块,再加上一次读和一次写)。
B+树
在RDBMS中,数据随机无序写在磁盘块中,如果没有B+树,读性能会很低。B+树对于数据读操作能很好地提高性能,但对于数据写,效率不高。对于大型分布式数据系统,B+树还无法与LSM树相抗衡。
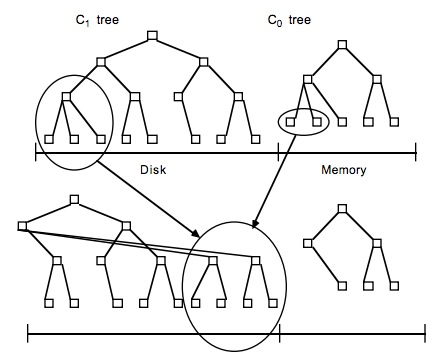
LSM树
随着NoSQL系统尤其是类BigTable系统的流行,LSM的文件系统越来越让人熟知。
- LSM主要用于为那些长期具有很高记录更新(插入和删除)频率的文件提供低成本的索引机制。
- LSM树实现了所有的索引值对于所有的查询来说都可以通过内存组件或某个磁盘组件进行访问。
- LSM减少了磁盘磁壁的移动次数降低了进行数据插入时磁盘磁壁的开销。
- LSM在进行需要即时响应的操作时会损失I/O效率,最适用于索引插入比查询操作多的情况。
核心思想的核心就是放弃部分读能力,换取写入的最大化能力。LSM树主题思想是划分两个部分:一部分在磁盘,一部分在内存。
主要原理
- 输入的数据首先会插入到内存中的树;
- 同时为了防止数据丢失,写内存的同时需要暂时持久化到磁盘(即输入数据时数据会以完全有序的形式先存储在日志文件中(对应HBase的MemStore和HLog));
- 当日志文件被修改时,对应的更新会被先保存在内存中来加速查询。
- 当内存空间逐渐被占满之后,LSM会把这些有序的键刷新到磁盘,同时和磁盘中的LSM树合并成一个文件。
- 合并操作会从左至右遍历内存中的叶子节点与磁盘中树的叶子节点进行合并;
- 当合并的数据量达到磁盘的存储页的大小时,会将合并的数据持久化到磁盘;
- 同时更新父亲节点对叶子节点的指针。
LSM树的读写
LSM树的读写
数据写
- 数据首先顺序写如HLog (WAL), 然后同步写到MemStore;
- 在MemStore中,数据是一个2层B+树(下图中的C0树)。MemStore上的树达到一定大小之后,需要flush到HRegion磁盘中(一般是Hadoop DataNode),这样MemStore就变成了DataNode上的磁盘文件StoreFile,定期HRegionServer对DataNode的数据做merge操作,彻底删除无效空间,多棵小树在这个时机合并成大树,来增强读性能。
- 在storefile中,数据是3层B+树(下图中的C1树),并针对顺序磁盘操作进行优化。
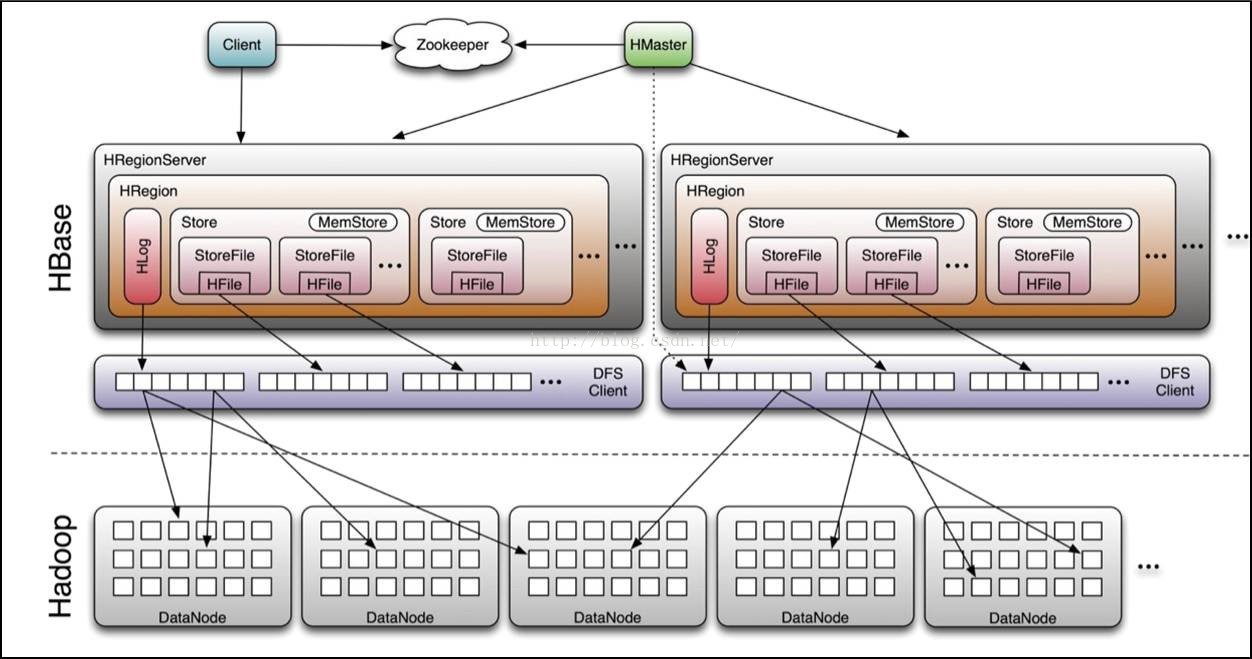
数据读
- 首先搜索MemStore,如果不在MemStore中,则到storefile中寻找。
数据删除
- 不会去磁盘上删除数据,而是为数据添加一个删除标记。在随后的major compaction中,被删除的数据和删除标记才会真的被删除。
补充:hbase在实现中,是把整个内存在一定阈值后,flush到disk中,形成一个file,这个file的存储也就是一个小的B+树,因为hbase一般是部署在hdfs上,hdfs不支持对文件的update操作,所以hbase这么整体内存flush,而不是和磁盘中的小树merge update,这个设计也就能讲通了。内存flush到磁盘上的小树,定期也会合并成一个大树。整体上hbase就是用了lsm tree的思路。
LSM树的优化方式
Bloom filter
就是个带随即概率的bitmap,可以快速的告诉你,某一个小的有序结构里有没有指定的那个数据的。于是就可以不用二分查找,而只需简单的计算几次就能知道数据是否在某个小集合里啦。效率得到了提升,但付出的是空间代价。
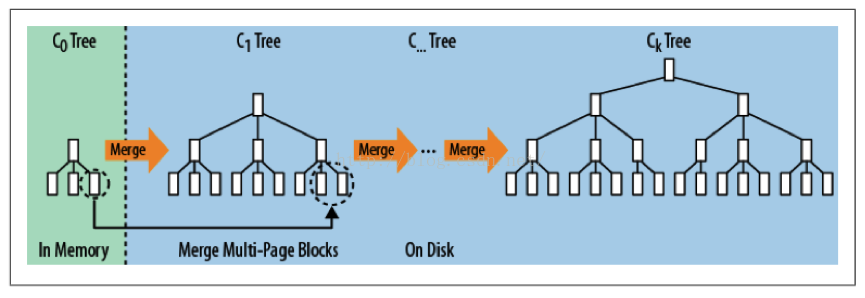
compact
小树合并为大树:因为小树他性能有问题,所以要有个进程不断地将小树合并到大树上,这样大部分的老数据查询也可以直接使用log2N的方式找到,不需要再进行(N/m)*log2n的查询了.
关于LSM最本质原理的3个问题
- 首先说说为什么要有WAL(Write Ahead Log)?
因为数据是先写到内存中,如果断电,内存中的数据会丢失,因此为了保护内存中的数据,需要在磁盘上先记录logfile,
当内存中的数据flush到磁盘上时,就可以抛弃相应的Logfile。
- 什么是memstore,storefile?
LSM树就是一堆小树,在内存中的小树即memstore,每次flush,内存中的memstore变成磁盘上一个新的storefile。
- 为什么会有compact?
随着小树越来越多,读的性能会越来越差,因此需要在适当的时候,对磁盘中的小树进行merge,多棵小树变成一颗大树。
B树与LSM树的适应场景
LSM-Tree比较适合的应用场景是:insert数据量大,读数据量和update数据量不高且读一般,针对最新数据。
B-Tree比较适合的应用场景:insert数据量小,读数据量比较高。