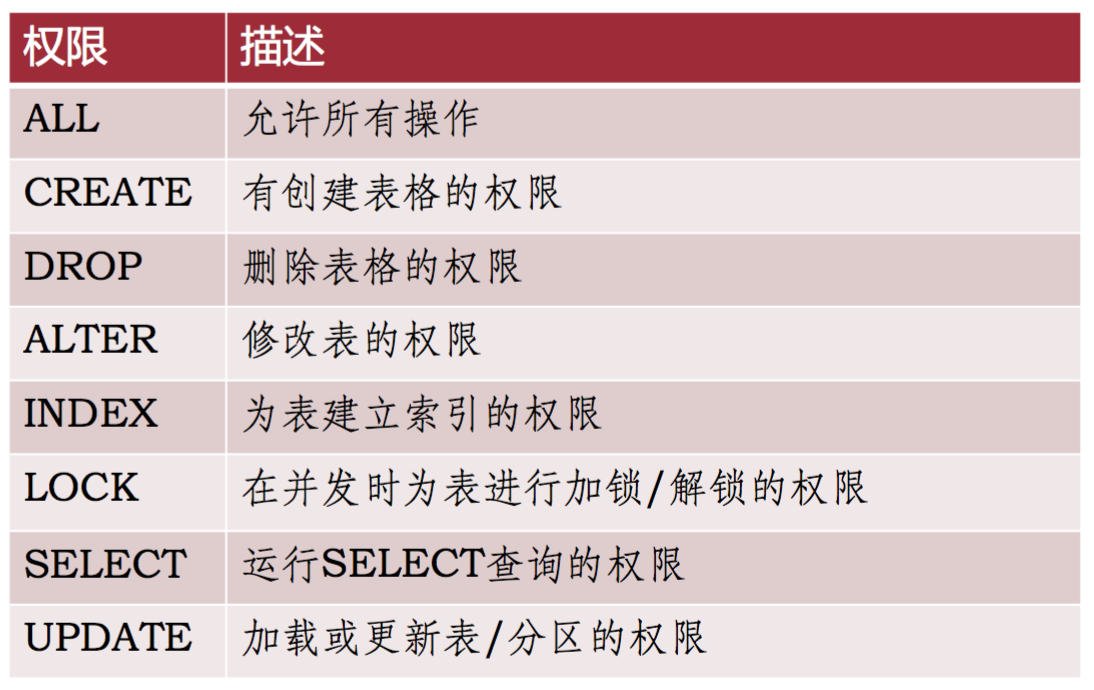
�������: Hive��֧�ֵ��������ʾ������: X AND Y / X && Y, X OR Y / X
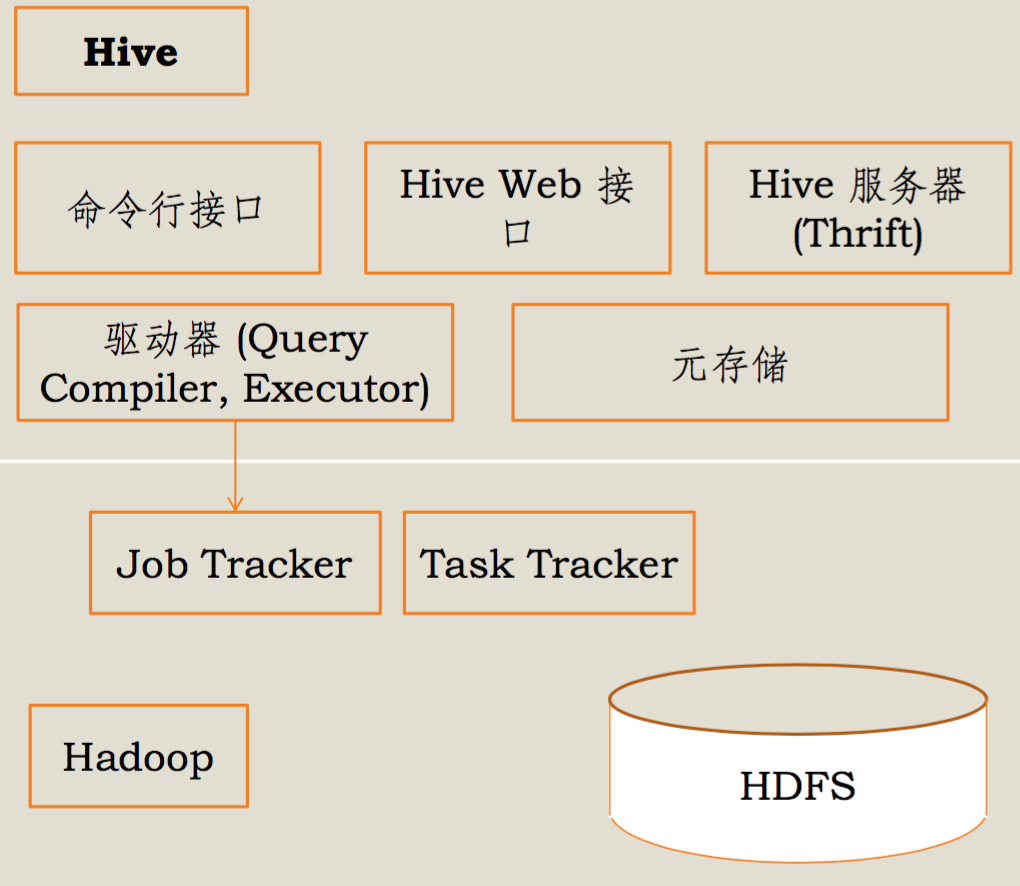
Hive �ڽ�����
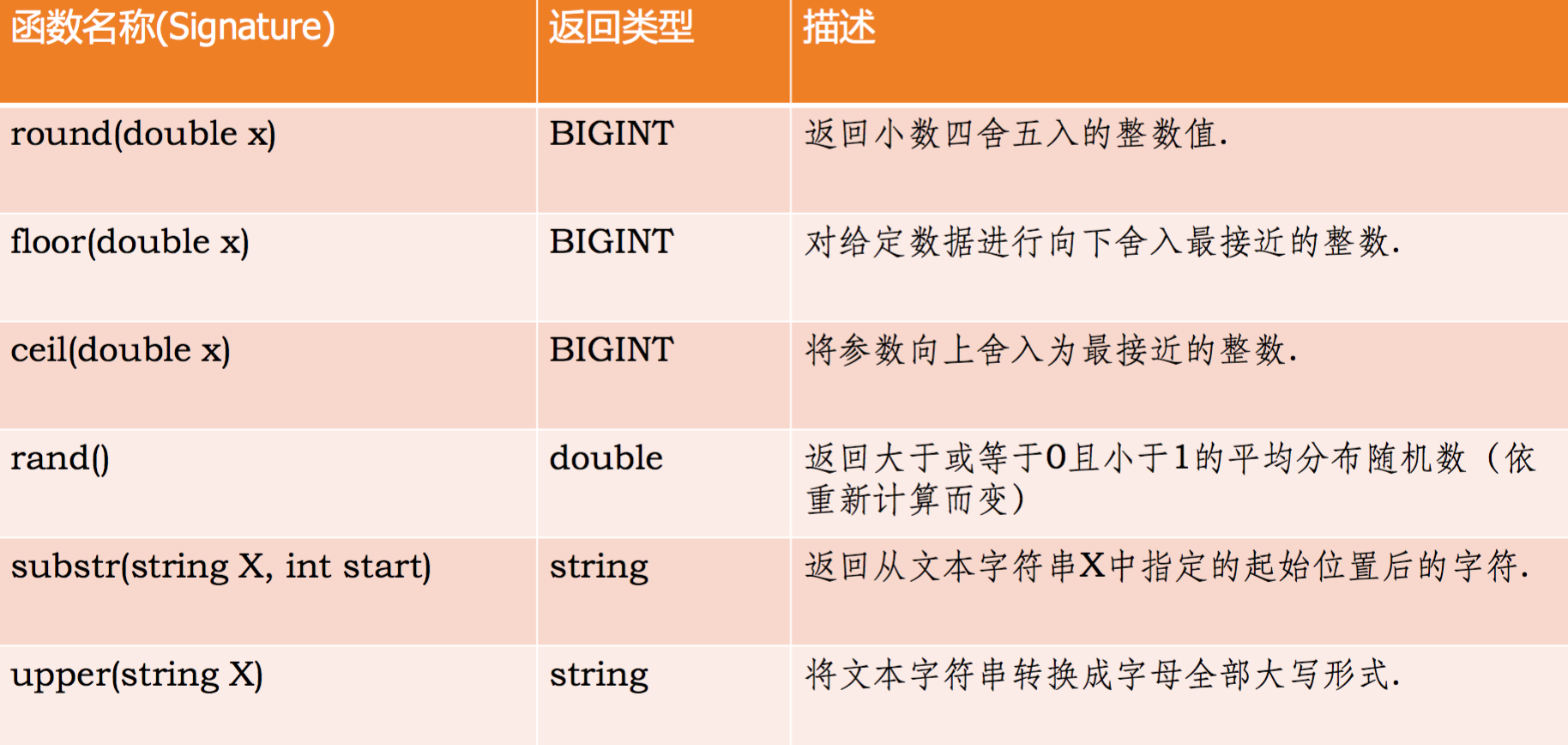
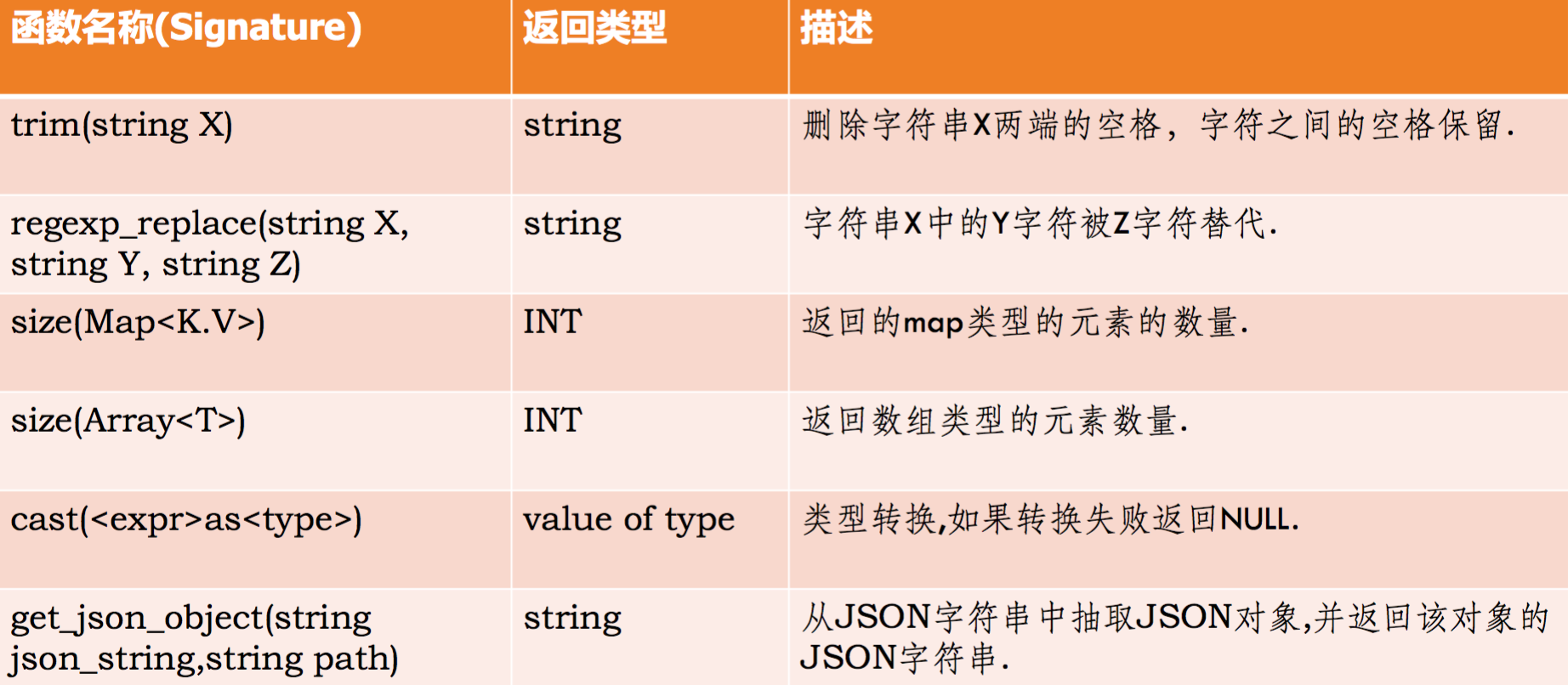
Hive���õ�����
��������t��Ϊ�еķָ�����
create table tradedetail (id bigint,income double,expenses double,time string) row formate delimited fields terminated by 't';
create table userinfo(id bigint, account string, name string, age int) row format delimited fields terminated by 't';
�ڴ������ĵ�ͬʱ���и�ֵ��
create table result row format delimited fields terminated by 't' as select t1.account, t1.income, t1.expenses, t1.surplus, t2.name from userinfo t2 join (select account, sum(income) as income, sum(expenses) as expenses, sum(income-expenses) as surplus from tradedetail group by account) t1 on(t1.account = t2.account);
���ر����ļ������ݱ��У�
load data local inpath '/home/hadoop/data/student.txt' overwrite into table student;
load data local inpath '/home/hadoop/data/userinfo.doc' overwrite into table userinfo;
HiveQL ��ѯ�����������SELECT��䣬����SELECT���֮�⣬��һ����Ҫ��HiveQL ��ѯ���������Ʋ�ѯ,Ƕ�ײ�ѯ, CASE��WHEN��THEN ��ѯ, LIKE��RLIKE ��ѯ, GROUP BY ��ѯ�ȡ�������ṹ��Mysql����ṹʮ�����ơ�
Select ��䣺
SELECT <column1>, <column2> FROM <tablename>;
�����в�ѯ�����ַ�����ͷ�ļ�¼��
SELECT string FROM <tablename>;
����������ѯ��
SELECT FROM <tablename> limit 10;
Ƕ�ײ�ѯ��
SELECT FROM <tablename> where <condition> <compares> (SELECT <column> FROM <tablename>);
CASE��WHEN��THEN ��ѯ��
SELECT <column1>, CASE WHEN <condition1> THEN <option1>, WHEN <condition2> THEN <option2>, ELSE <option3> END AS <column2> FROM <tablename>;
LIKE �� RLIKE ģ����ѯ��
SELECT FROM <tablename> WHERE <column1> LIKE ��%string%��; SELECT FROM <tablename> WHERE <column2> RLIKE ��.(string).��;
GROUP BY ��ѯ��
SELECT <column1>, <column2> FROM <tablename> GROUP BY <column1>;
HAVING ��ѯ��
SELECT <column1>, <column2> FROM <tablename> GROUP BY <column1> HAVING <column1=value1> OR <column1=value2>;