版权声明:本博客文章均由博主从互联网及各类书本资料收集加以自己理解、整理,如需转载请注明出处! https://blog.csdn.net/feloxx/article/details/70788209
消息队列,kafka 我们使用的是最新版0.10.2.0 其中的很多使用方法与api已经迭代,与老版本(0.8、0.9)有很大差距
因为在后续的flume采集,spark计算时,都有kafka的操作,需要稍微对kafka基础用法介绍介绍
详细学习可以去http://www.orchome.com/kafka/index
这里就做些简单快速的基础介绍
此文只将了创建topic,删除topic,和一些简单的对接,后续会再出一篇关于实际场景使用调优。
kafka简单介绍
摘抄一段我觉得解释kafka特别不错的话
Apache kafka是消息中间件(也叫消息队列)的一种,我发现很多人不知道消息中间件是什么,在开始学习之前,我这边就先简单的解释一下什么是消息中间件,只是粗略的讲解,目前kafka已经可以做更多的事情。
举个例子,生产者消费者,生产者生产鸡蛋,消费者消费鸡蛋,生产者生产一个鸡蛋,消费者就消费一个鸡蛋,假设消费者消费鸡蛋的时候噎住了(系统宕机了),生产者还在生产鸡蛋,那新生产的鸡蛋就丢失了。再比如生产者很强劲(大交易量的情况),生产者1秒钟生产100个鸡蛋,消费者1秒钟只能吃50个鸡蛋,那要不了一会,消费者就吃不消了(消息堵塞,最终导致系统超时),消费者拒绝再吃了,"鸡蛋"又丢失了,这个时候我们放个篮子在它们中间,生产出来的鸡蛋都放到篮子里,消费者去篮子里拿鸡蛋,这样鸡蛋就不会丢失了,都在篮子里,而这个篮子就是"kafka"。
鸡蛋其实就是"数据流",系统之间的交互都是通过"数据流"来传输的(就是tcp、http什么的),也称为报文,也叫"消息"。
消息队列满了,其实就是篮子满了,"鸡蛋" 放不下了,那赶紧多放几个篮子,其实就是kafka的扩容。
各位现在知道kafka是干什么的了吧,它就是那个"篮子"。
kafka名词介绍
后面大家会看到一些关于kafka的名词,比如topic、producer、consumer、broker,我这边来简单说明一下。
producer:生产者,就是它来生产"鸡蛋"的。
consumer:消费者,生出的"鸡蛋"它来消费。
topic:你把它理解为标签,生产者每生产出来一个鸡蛋就贴上一个标签(topic),消费者可不是谁生产的"鸡蛋"都吃的,这样不同的生产者生产出来的"鸡蛋",消费者就可以选择性的"吃"了。
broker:就是篮子了。
大家一定要学会抽象的去思考,上面只是属于业务的角度,如果从技术角度,topic标签实际就是队列,生产者把所有"鸡蛋(消息)"都放到对应的队列里了,消费者到指定的队列里取。
咱们这套流程的角色担当
生产者 -> flume
队列 -> kafka topic
消费者 -> spark streaming
第一步 基础命令
1.1 创建topic
kafka-topics.sh --create --zookeeper hadoop1:2181 --replication-factor 1 --partitions 1 --topic filetest1
主要的三个参数
--replication-factor 翻译过来是复制因子,数据的备份个数(假如这里配置3,我集群是5台kafka的话,这个topic会在5台中选取3台来生成数据文件,详情见下图)
--partitions 分区数,将topic分成指定数量的区
--zookeeper 多个zk地址,逗号分隔,写一个也可以(目的是连接zk,一个和多个的效果最终一样)
我们先来测试下副本数
[hadoop1@hadoop1 1]$ kafka-topics.sh --create --zookeeper hadoop1:2181 --replication-factor 3 --partitions 1 --topic filetest13
Created topic "filetest13".
检查我5台机器中的生成情况
[hadoop1@hadoop1 ~]$ ll /home/hadoop1/softs/kafka-2.11-0.10.2.0/kafka-logs/ | grep filetest13
[hadoop1@hadoop2 ~]$ ll /home/hadoop1/softs/kafka-2.11-0.10.2.0/kafka-logs/ | grep filetest13
drwxrwxr-x 2 hadoop1 hadoop1 4096 Apr 13 15:21 filetest13-0
[hadoop1@hadoop3 ~]$ ll /home/hadoop1/softs/kafka-2.11-0.10.2.0/kafka-logs/ | grep filetest13
[hadoop1@hadoop4 work]$ ll /home/hadoop1/softs/kafka-2.11-0.10.2.0/kafka-logs/ | grep filetest13
drwxrwxr-x 2 hadoop1 hadoop1 4096 Apr 13 15:21 filetest13-0
[hadoop1@hadoop5 work]$ ll /home/hadoop1/softs/kafka-2.11-0.10.2.0/kafka-logs/ | grep filetest13
drwxrwxr-x 2 hadoop1 hadoop1 4096 Apr 13 15:21 filetest13-0
选择了2 4 5号机来生成了3个副本(这里的生成3个副本,是也把自己也包括进去了,3副本是相当于【主,备1,备2】,而不是一个主加3个备份)
filetest13-0后面的0,是代表分区数
接着我们测试下分区数
[hadoop1@hadoop1 1]$ kafka-topics.sh --create --zookeeper hadoop1:2181 --replication-factor 3 --partitions 3 --topic filetest14
Created topic "filetest14".
[hadoop1@hadoop1 1]$ ll /home/hadoop1/softs/kafka-2.11-0.10.2.0/kafka-logs/ | grep filetest14
drwxrwxr-x 2 hadoop1 hadoop1 4096 Apr 13 15:26 filetest14-0
drwxrwxr-x 2 hadoop1 hadoop1 4096 Apr 13 15:26 filetest14-1
drwxrwxr-x 2 hadoop1 hadoop1 4096 Apr 13 15:26 filetest14-2
[hadoop1@hadoop2 testdata]$ ll /home/hadoop1/softs/kafka-2.11-0.10.2.0/kafka-logs/ | grep filetest14
drwxrwxr-x 2 hadoop1 hadoop1 4096 Apr 13 15:26 filetest14-1
drwxrwxr-x 2 hadoop1 hadoop1 4096 Apr 13 15:26 filetest14-2
[hadoop1@hadoop3 0]$ ll /home/hadoop1/softs/kafka-2.11-0.10.2.0/kafka-logs/ | grep filetest14
drwxrwxr-x 2 hadoop1 hadoop1 4096 Apr 13 15:26 filetest14-2
[hadoop1@hadoop4 work]$ ll /home/hadoop1/softs/kafka-2.11-0.10.2.0/kafka-logs/ | grep filetest14
drwxrwxr-x 2 hadoop1 hadoop1 4096 Apr 13 15:26 filetest14-0
[hadoop1@hadoop5 work]$ ll /home/hadoop1/softs/kafka-2.11-0.10.2.0/kafka-logs/ | grep filetest14
drwxrwxr-x 2 hadoop1 hadoop1 4096 Apr 13 15:26 filetest14-0
drwxrwxr-x 2 hadoop1 hadoop1 4096 Apr 13 15:26 filetest14-1
这里很明显能看出来了
副本数如果是3,那是最多在3台机器中有存放0号分区
但是如果分区数也是3的话,会将topic分成0 1 2三个分区,具体的存放规则得看源码了,后续我补上这段地方的源码规则实现。
这里主要明白什么呢?我到底改怎么设计topic的副本数和分区数!
副本数好理解,一般3副本就可以了,中规中矩。
那分区数,怎么确定呢?
要确定分区怎么选择,首先得理解分区是什么:
Kafka可以将主题划分为多个分区(Partition),会根据分区规则选择把消息存储到哪个分区中,只要如果分区规则设置的合理,那么所有的消息将会被均匀的分布到不同的分区中,这样就实现了负载均衡和水平扩展。
简单介绍了分区,我们详细的来讲讲,各角色对分区的操作:
Kafka的生产者和消费者都可以多线程地并行操作,而每个线程处理的是一个分区的数据。因此分区实际上是调优Kafka并行度的最小单元。
对于producer而言,它实际上是用多个线程并发地向不同分区所在的broker发起Socket连接同时给这些分区发送消息;
而consumer呢,同一个消费组内的所有consumer线程都被指定topic的某一个分区进行消费;
如果一个topic分区越多,理论上整个集群所能达到的吞吐量就越大。
但是分区是不是越多越好呢?显然不是,因为没个分区都有自己的资源占用开销,分区多了,资源占用同样也多了,反而更占资源了。
分区的几个限制地方:
分区数,限制了consumer的并行度,即限制了并行consumer消息的线程数不能大于分区数;
分区数,限制了producer发送消息是指定的分区(如创建topic时分区设置为1,producer发送消息时通过自定义的分区方法指定分区为2或以上的数都会出错的);
分区与偏移量(Offset)、消费线程、消费者组(group.id)的关系:
一组(类)消息通常由某个topic来归类,我们可以把这组消息"分发"给若干个分区(partition),每个分区的消息各不相同;
每个分区都维护着他自己的偏移量(Offset),记录着该分区的消息此时被消费的位置;
一个消费线程可以对应若干个分区,但一个分区只能被具体某一个消费线程消费;
group.id用于标记某一个消费组,每一个消费组都会被记录他在某一个分区的Offset,即不同consumer group针对同一个分区,都有"各自"的偏移量。
大概概念差不多是这些,不能扯太远了,最后我们总结一下:
1.分区数限制了上下游的线程数,可以理解整体的并行度吧
2.分区数是为了实现负载均衡
3.分区设计需要考虑各角色的资源占用,副本数,文件句柄数,等等
最后网上习得一个公式
创建一个只有1个分区的topic
然后测试这个topic的producer吞吐量和consumer吞吐量。
假设它们的值分别是Tp和Tc,单位可以是MB/s。
然后假设总的目标吞吐量是Tt,那么分区数 = Tt / max(Tp, Tc)
Tp表示producer的吞吐量。测试producer通常是很容易的,因为它的逻辑非常简单,就是直接发送消息到Kafka就好了。
Tc表示consumer的吞吐量。测试Tc通常与应用的关系更大, 因为Tc的值取决于你拿到消息之后执行什么操作,因此Tc的测试通常也要麻烦一些。
(如果觉得麻烦,也可以就先3个试水,具体来根据自己的业务和数据量来调整)
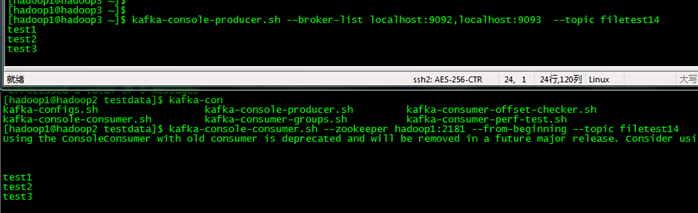
1.2 控制台生产&消费测试
创建了个topic,怎么着也得来个测试生产和消费嘛
首先执行下topic检查
kafka-topics --list --zookeeper hadoop1:2181
确定创建的topic是否存在
启动消费者
kafka-console-consumer.sh --zookeeper hadoop1:2181 --from-beginning --topic filetest14
再启动生产者
kafka-console-producer --broker-list hadoop1:9092 --topic filetest14
测试生产消息,消费消息
1.3 删除topic
在配置文件中把删除确定打开

[hadoop1@hadoop1 ~]$ kafka-topics.sh --zookeeper hadoop1:2181 --delete --topic filetest14
Topic filetest14 is marked for deletion.
Note: This will have no impact if delete.topic.enable is not set to true.
这里虽然会提示是已标记删除,实际上已经物理删除了,只是提醒要把配置文件中的删除确认打开
1.4 查看topic数据偏移量
这是kafka0.10后的版本的改动,查看偏移度的其他工具类操作都改到了kafka-run-class这个脚本来执行了。
这里也顺便介绍一下kafka-run-class这个脚本中的套路。
这个脚本主要是调用kafka中的工具类所设计的。大部分是起到了监控作用。
官方文档页面https://cwiki.apache.org/confluence/display/KAFKA/System+Tools(使用科学上网,获得更好的学习体验)
我认为比较重要的一个就是查看topic偏移度,比如我们从flume采集那接收了多少数据,就可以通过查偏移度来判断。
看看官方的解释
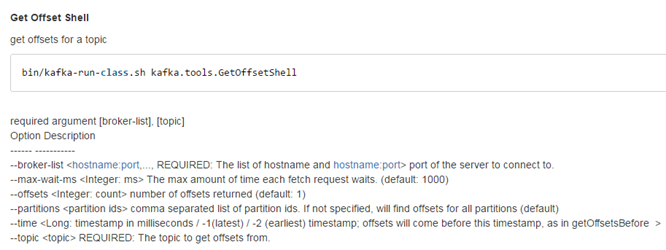
或者我们直接来运行一下命令,看看效果

参数解释:
--time -1 表示从最新的时间的offset中得到数据条数
输出结果每个字段分别表示
topic、partition、结束数据偏移度untilOffset
其他的工具使用大家可以自行啃官方文档了。
第二步 对接flume
2.1 对接讲解
kafka的配置主要是创建topic即可,重要的配置是在flume中。
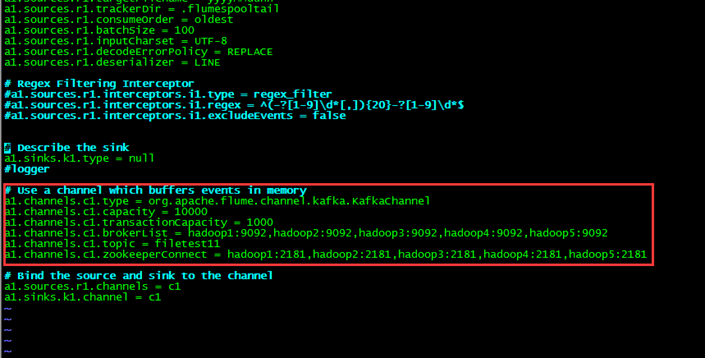
org.apache.flume.channel.kafka.KafkaChannel 这个包在flume1.6中已经带了,我们这只需配置上直接使用即可
关于flume的配置,以及flume对接kafka测试,我们会在下一篇flume的文章中详细介绍到。
第三步 对接spark
3.1对接讲解spark消费主要是在spark中需要引入以下包
以KafkaUtils.createDirectStream
direct spark方式创建DStream流来进行计算。
顺便讲讲spark消费kafka中的套路
Spark Streaming获取Kafka数据的两种方式:
Receiver方式 (被动接收方式消费)
Direct方式 (直接地选择偏移量消费)
Receiver方式,是通过Receiver从kafka获取数据。(WAL)
Receiver方是使用Kafka的高层次Consumer API来实现的。
Receiver从Kafka中获取的数据都是存储在Spark Executor的内存中的,然后Spark启动job来处理这些数据。
在默认的配置下,这种方式可能会因为底层的失败(spark意外退出之类)而丢失数据。
如果要启用高可靠机制,让数据零丢失,就必须启用Spark Streaming的预写日志机制(Write Ahead Log,WAL)。
该机制会同步地将接收到的Kafka数据写入分布式文件系统(比如HDFS)上的预写日志中,这样会造成一定的系统开销,但是也保证不了一条数据只处理一次。
会出现的问题
如果在写入到外部存储的数据还没有将offset更新到zookeeper就挂掉,这些数据将会被反复消费。同时,降低了程序的吞吐量。
Direct方式,没有使用Receiver,是使用Kakfa的简单API(Simple Consumer API)获取数据
Spark Streaming自己就负责追踪消费的offset,并保存在checkpoint中。(也可以保存在zk中,这套流程是将偏移度保存在zk中了)
这样就能保证这个过程是同步的,因此可以保证数据是消费一次且仅处理一次。
Direct的方式简化了并行读取,不需要创建多个DStream再进行union操作,可以实现Kafka partition和RDD partition之间一一对应。
Direct的方式不需要开启预写日志机制,减少了写入开销。(最重要就是这一点,WAL是将数据多缓存了一次,而direce是保存偏移度就几个字节,数据量差别很大)
Kafka direct API 的运行方式,将不再使用receiver来读取数据,也不用使用WAL机制。 同时保证了exactly-once语义,不会在WAL中消费重复数据。
不过需要自己完成将offset写入zk的过程,在官方文档中都有相应介绍。
官方文档地址:http://spark.apache.org/docs/latest/streaming-kafka-integration.html 我使用的spark-streaming-kafka-0-10 or higher
在后续的spark streaming 消费 kafka 实现数据零丢失,保证消费高可用中,会详细介绍Direct套路的代码。