一、flume配置
flume要求1.6以上版本
flume-conf.properties文件配置内容,sinks的输出作为kafka的product
-
a1.sources=r1
-
a1.sinks=k1
-
a1.channels=c1
-
-
#Describe/configurethesource
-
a1.sources.r1.type=exec
-
a1.sources.r1.command=tail-F/home/airib/work/log.log
-
-
#Describethesink
-
#a1.sinks.k1.type=logger
-
a1.sinks.k1.type=org.apache.flume.sink.kafka.KafkaSink
-
a1.sinks.k1.topic=test
-
a1.sinks.k1.brokerList=localhost:9092
-
a1.sinks.k1.requiredAcks=1
-
a1.sinks.k1.batchSize=20
-
-
#Useachannelwhichbufferseventsinmemory
-
a1.channels.c1.type=memory
-
a1.channels.c1.capacity=1000
-
a1.channels.c1.transactionCapacity=100
-
-
#Bindthesourceandsinktothechannel
-
a1.sources.r1.channels=c1
-
a1.sinks.k1.channel=c1
flume启动
bin/flume-ng agent --conf conf --conf-file conf/flume-conf.properties --name a1 -Dflume.root.logger=INFO,console
二 kafka的消费者java源代码
-
packagecom.hgp.kafka.kafka;
-
-
importjava.util.HashMap;
-
importjava.util.List;
-
importjava.util.Map;
-
importjava.util.Properties;
-
-
importkafka.consumer.ConsumerConfig;
-
importkafka.consumer.ConsumerIterator;
-
importkafka.consumer.KafkaStream;
-
importkafka.javaapi.consumer.ConsumerConnector;
-
importkafka.serializer.StringDecoder;
-
importkafka.utils.VerifiableProperties;
-
-
publicclassKafkaConsumer{
-
-
privatefinalConsumerConnectorconsumer;
-
-
privateKafkaConsumer(){
-
Propertiesprops=newProperties();
-
//zookeeper配置
-
props.put("zookeeper.connect","localhost:2181");
-
-
//group代表一个消费组
-
props.put("group.id","jd-group");
-
-
//zk连接超时
-
props.put("zookeeper.session.timeout.ms","4000");
-
props.put("zookeeper.sync.time.ms","200");
-
props.put("auto.commit.interval.ms","1000");
-
props.put("auto.offset.reset","smallest");
-
//序列化类
-
props.put("serializer.class","kafka.serializer.StringEncoder");
-
-
ConsumerConfigconfig=newConsumerConfig(props);
-
-
consumer=kafka.consumer.Consumer.createJavaConsumerConnector(config);
-
}
-
-
voidconsume(){
-
Map<String,Integer>topicCountMap=newHashMap<String,Integer>();
-
topicCountMap.put("test",newInteger(1));
-
-
StringDecoderkeyDecoder=newStringDecoder(newVerifiableProperties());
-
StringDecodervalueDecoder=newStringDecoder(newVerifiableProperties());
-
-
Map<String,List<KafkaStream<String,String>>>consumerMap=
-
consumer.createMessageStreams(topicCountMap,keyDecoder,valueDecoder);
-
KafkaStream<String,String>stream=consumerMap.get("test").get(0);
-
ConsumerIterator<String,String>it=stream.iterator();
-
while(it.hasNext())
-
System.out.println(it.next().message());
-
}
-
-
publicstaticvoidmain(String[]args){
-
newKafkaConsumer().consume();
-
}
-
}
kafka启动命令
启动Zookeeper server:
bin/zookeeper-server-start.shconfig/zookeeper.properties&
启动Kafka server:
bin/kafka-server-start.shconfig/server.properties&
运行producer:
bin/kafka-console-producer.sh--broker-listlocalhost:9092--topictest
运行consumer:
bin/kafka-console-consumer.sh--zookeeperlocalhost:2181--topictest--from-beginning
二、示例
-
packagecom.hgp.kafka.kafka;
-
-
importjava.util.Arrays;
-
importjava.util.HashMap;
-
importjava.util.Iterator;
-
importjava.util.Map;
-
importjava.util.Map.Entry;
-
importjava.util.concurrent.atomic.AtomicInteger;
-
-
importorg.apache.commons.logging.Log;
-
importorg.apache.commons.logging.LogFactory;
-
-
importstorm.kafka.BrokerHosts;
-
importstorm.kafka.KafkaSpout;
-
importstorm.kafka.SpoutConfig;
-
importstorm.kafka.StringScheme;
-
importstorm.kafka.ZkHosts;
-
importbacktype.storm.Config;
-
importbacktype.storm.LocalCluster;
-
importbacktype.storm.StormSubmitter;
-
importbacktype.storm.generated.AlreadyAliveException;
-
importbacktype.storm.generated.InvalidTopologyException;
-
importbacktype.storm.spout.SchemeAsMultiScheme;
-
importbacktype.storm.task.OutputCollector;
-
importbacktype.storm.task.TopologyContext;
-
importbacktype.storm.topology.OutputFieldsDeclarer;
-
importbacktype.storm.topology.TopologyBuilder;
-
importbacktype.storm.topology.base.BaseRichBolt;
-
importbacktype.storm.tuple.Fields;
-
importbacktype.storm.tuple.Tuple;
-
importbacktype.storm.tuple.Values;
-
-
publicclassMyKafkaTopology{
-
-
publicstaticclassKafkaWordSplitterextendsBaseRichBolt{
-
-
privatestaticfinalLogLOG=LogFactory.getLog(KafkaWordSplitter.class);
-
privatestaticfinallongserialVersionUID=886149197481637894L;
-
privateOutputCollectorcollector;
-
-
-
publicvoidprepare(MapstormConf,TopologyContextcontext,
-
OutputCollectorcollector){
-
this.collector=collector;
-
}
-
-
-
publicvoidexecute(Tupleinput){
-
Stringline=input.getString(0);
-
LOG.info("RECV[kafka->splitter]"+line);
-
String[]words=line.split("\\s+");
-
for(Stringword:words){
-
LOG.info("EMIT[splitter->counter]"+word);
-
collector.emit(input,newValues(word,1));
-
}
-
collector.ack(input);
-
}
-
-
-
publicvoiddeclareOutputFields(OutputFieldsDeclarerdeclarer){
-
declarer.declare(newFields("word","count"));
-
}
-
-
}
-
-
publicstaticclassWordCounterextendsBaseRichBolt{
-
-
privatestaticfinalLogLOG=LogFactory.getLog(WordCounter.class);
-
privatestaticfinallongserialVersionUID=886149197481637894L;
-
privateOutputCollectorcollector;
-
privateMap<String,AtomicInteger>counterMap;
-
-
-
publicvoidprepare(MapstormConf,TopologyContextcontext,
-
OutputCollectorcollector){
-
this.collector=collector;
-
this.counterMap=newHashMap<String,AtomicInteger>();
-
}
-
-
-
publicvoidexecute(Tupleinput){
-
Stringword=input.getString(0);
-
intcount=input.getInteger(1);
-
LOG.info("RECV[splitter->counter]"+word+":"+count);
-
AtomicIntegerai=this.counterMap.get(word);
-
if(ai==null){
-
ai=newAtomicInteger();
-
this.counterMap.put(word,ai);
-
}
-
ai.addAndGet(count);
-
collector.ack(input);
-
LOG.info("CHECKstatisticsmap:"+this.counterMap);
-
}
-
-
-
publicvoidcleanup(){
-
LOG.info("Thefinalresult:");
-
Iterator<Entry<String,AtomicInteger>>iter=this.counterMap.entrySet().iterator();
-
while(iter.hasNext()){
-
Entry<String,AtomicInteger>entry=iter.next();
-
LOG.info(entry.getKey()+"\t:\t"+entry.getValue().get());
-
}
-
-
}
-
-
-
publicvoiddeclareOutputFields(OutputFieldsDeclarerdeclarer){
-
declarer.declare(newFields("word","count"));
-
}
-
}
-
-
publicstaticvoidmain(String[]args)throwsAlreadyAliveException,InvalidTopologyException,InterruptedException{
-
Stringzks="localhost:2181";
-
Stringtopic="test";
-
StringzkRoot="/storm";//defaultzookeeperrootconfigurationforstorm
-
Stringid="word";
-
-
BrokerHostsbrokerHosts=newZkHosts(zks);
-
SpoutConfigspoutConf=newSpoutConfig(brokerHosts,topic,zkRoot,id);
-
spoutConf.scheme=newSchemeAsMultiScheme(newStringScheme());
-
spoutConf.forceFromStart=true;
-
spoutConf.zkServers=Arrays.asList(newString[]{"localhost"});
-
spoutConf.zkPort=2181;
-
-
TopologyBuilderbuilder=newTopologyBuilder();
-
builder.setSpout("kafka-reader",newKafkaSpout(spoutConf),5);//Kafka我们创建了一个5分区的Topic,这里并行度设置为5
-
builder.setBolt("word-splitter",newKafkaWordSplitter(),2).shuffleGrouping("kafka-reader");
-
builder.setBolt("word-counter",newWordCounter()).fieldsGrouping("word-splitter",newFields("word"));
-
-
Configconf=newConfig();
-
-
Stringname=MyKafkaTopology.class.getSimpleName();
-
if(args!=null&&args.length>0){
-
//Nimbushostnamepassedfromcommandline
-
conf.put(Config.NIMBUS_HOST,args[0]);
-
conf.setNumWorkers(3);
-
StormSubmitter.submitTopologyWithProgressBar(name,conf,builder.createTopology());
-
}else{
-
conf.setMaxTaskParallelism(3);
-
LocalClustercluster=newLocalCluster();
-
cluster.submitTopology(name,conf,builder.createTopology());
-
Thread.sleep(60000);
-
cluster.shutdown();
-
}
-
}
-
}
pom.xml代码
-
<projectxmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
-
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0http://maven.apache.org/xsd/maven-4.0.0.xsd">
-
<modelVersion>4.0.0</modelVersion>
-
-
-
<groupId>com.ymm</groupId>
-
<artifactId>TestStorm</artifactId>
-
<version>0.0.1-SNAPSHOT</version>
-
<packaging>jar</packaging>
-
-
-
<name>TestStorm</name>
-
<url>http://maven.apache.org</url>
-
-
-
<properties>
-
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
-
</properties>
-
-
-
<dependencies>
-
<dependency>
-
<groupId>junit</groupId>
-
<artifactId>junit</artifactId>
-
<version>3.8.1</version>
-
<scope>test</scope>
-
</dependency>
-
<dependency>
-
<groupId>org.apache.storm</groupId>
-
<artifactId>storm-core</artifactId>
-
<version>0.10.0</version>
-
<scope>provided</scope>
-
</dependency>
-
-
-
<dependency>
-
<groupId>org.apache.storm</groupId>
-
<artifactId>storm-kafka</artifactId>
-
<version>0.10.0</version>
-
</dependency>
-
-
-
<dependency>
-
<groupId>org.apache.kafka</groupId>
-
<artifactId>kafka_2.9.2</artifactId>
-
<version>0.8.1.1</version>
-
<exclusions>
-
<exclusion>
-
<groupId>org.apache.zookeeper</groupId>
-
<artifactId>zookeeper</artifactId>
-
</exclusion>
-
<exclusion>
-
<groupId>log4j</groupId>
-
<artifactId>log4j</artifactId>
-
</exclusion>
-
</exclusions>
-
-
-
</dependency>
-
-
-
<dependency>
-
<groupId>commons-logging</groupId>
-
<artifactId>commons-logging</artifactId>
-
<version>1.1.1</version>
-
</dependency>
-
-
</dependencies>
-
</project>
-
<p><spanstyle="color:rgb(85,85,85);font-family:Consolas,'BitstreamVerasansMono','Couriernew',Courier,monospace;font-size:14px;line-height:15.3906px;white-space:pre;">1)打jar包mvncleanpackage</span>
-
</p><p><spanstyle="color:rgb(85,85,85);font-family:Consolas,'BitstreamVerasansMono','Couriernew',Courier,monospace;font-size:14px;line-height:15.3906px;text-indent:28px;white-space:pre;">2)上传storm集群stormjarxxx.jarcom.sss.class</span></p>
1. ZooKeeper
安装参考
2. Kafka
2.1 解压安装
tar -xf kafka_2.11-0.9.0.1.tgz
cd kafka_2.11-0.9.0.1
mkdir logs
vim ~/.bash_profile
export KAFKA_HOME=/home/zkpk/kafka_2.11-0.9.0.1
export PATH=$PATH:$KAFKA_HOME/bin
source ~/.bash_profile
2.2 配置
2.2.1 server.properties
只设置了以下4项,其他使用默认值
broker.id=0
host.name=hsm01
log.dirs=/home/zkpk/kafka_2.11-0.9.0.1/logs
zookeeper.connect=hsm01:2181,hss01:2181,hss02:2181/kafka
2.2.2 复制到其他节点
scp -r ~/kafka_2.11-0.9.0.1/ hss01:~/
scp -r ~/kafka_2.11-0.9.0.1/ hss02:~/
# 修改broker.id与host.name
# 配置环境变量
2.3 启动
kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties
2.4 测试
-. -- -- --- -- --
--. --- --
--. -- -- ---
-. -- --
-. -- -- --
-. -- -- --
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
2.5 参考
Kafka【第一篇】Kafka集群搭建
3. Flume
3.1 解压安装
tar -xf apache-flume-1.6.0-bin.tar.gz
mv apache-flume-1.6.0-bin/ flume-1.6.0
vim .bash_profile
export FLUME_HOME=/home/zkpk/flume-1.6.0
export PATH=$PATH:$FLUME_HOME/bin
3.2 配置(与kafka整合)
kafkasink只有在1.6.0以上的flume版本才有。
3.2.1 flume-env.sh
JAVA_HOME=/opt/jdk1.8.0_45
3.2.2 kafka-sogolog.properties
# configure agent
a1.sources = f1
a1.channels = c1
a1.sinks = k1
# configure the source
a1.sources.f1.type = netcat
a1.sources.f1.bind = localhost
a1.sources.f1.port = 3333
# configure the sink (kafka)
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.topic = sogolog
a1.sinks.k1.brokerList = hsm01:9092,hss01:9092/kafka
a1.sinks.k1.requiredAcks = 0
a1.sinks.k1.batchSize = 20
# configure the channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# bind the source and sink to the channel
a1.sources.f1.channels = c1
a1.sinks.k1.channel = c1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
3.3 启动
启动ZooKeeper服务
$ZOOKEEPER_HOME/bin/zkServer.sh start
启动kafka
--. - .
-. -- -- --- -- --
--. -- -- ---
启动flume
flume-ng agent -n a1 -c conf -f conf/kafka-sogolog.properties -Dflume.root.logger=DEBUG,console
注:命令中的a1表示配置文件中的Agent的Name,如配置文件中的a1。flume-conf.properties表示配置文件所在配置,需填写准确的配置文件路径。
3.4 测试
telnet输入
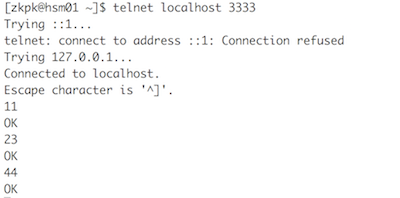
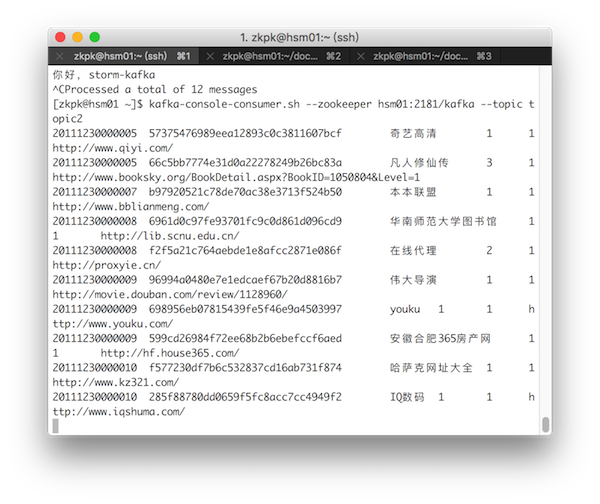
flume采集数据
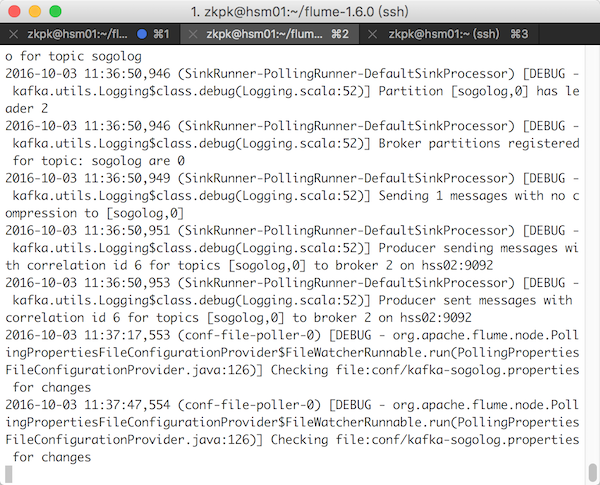
kafka接收数据

3.5 参考
高可用Hadoop平台-Flume NG实战图解篇
linux安装flume及问题
Flume ng1.6 + kafka 2.11 整合
Flume自定义Hbase Sink的EventSerializer序列化类
Flume 1.6.0 User Guide
org/apache/flume/tools/GetJavaProperty
4. Storm
4.1 安装
Storm安装
4.2 简单测试
4.2.1 pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>bigdata-demo</artifactId>
<groupId>com.zw</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>storm-demo</artifactId>
<packaging>jar</packaging>
<name>storm-demo</name>
<url>http://maven.apache.org</url>
<repositories>
<repository>
<id>github-releases</id>
<url>http://oss.sonatype.org/content/repositories/github-releases</url>
</repository>
<repository>
<id>clojars.org</id>
<url>http://clojars.org/repo</url>
</repository>
<repository>
<id>twitter4j</id>
<url>http://twitter4j.org/maven2</url>
</repository>
</repositories>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<storm.version>0.9.7</storm.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>${storm.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.googlecode.json-simple</groupId>
<artifactId>json-simple</artifactId>
<version>1.1.1</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass></mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>com.theoryinpractise</groupId>
<artifactId>clojure-maven-plugin</artifactId>
<version>1.3.8</version>
<extensions>true</extensions>
<configuration>
<sourceDirectories>
<sourceDirectory>src/clj</sourceDirectory>
</sourceDirectories>
</configuration>
<executions>
<execution>
<id>compile</id>
<phase>compile</phase>
<goals>
<goal>compile</goal>
</goals>
</execution>
<execution>
<id>test</id>
<phase>test</phase>
<goals>
<goal>test</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.5.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>${project.build.sourceEncoding}</encoding>
</configuration>
</plugin>
</plugins>
</build>
</project>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
注意storm-core依赖的scope
4.2.2 HelloWorldSpout.java
package com.zw.storm.helloworld;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichSpout;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.utils.Utils;
import java.util.Map;
import java.util.Random;
/**
* Spout起到和外界沟通的作用,他可以从一个数据库中按照某种规则取数据,也可以从分布式队列中取任务
* <p>
* 生成一个随机数生成的Tuple
* </p>
*
* Created by zhangws on 16/10/3.
*/
public class HelloWorldSpout extends BaseRichSpout {
private SpoutOutputCollector collector;
private int referenceRandom;
private static final int MAX_RANDOM = 10;
public HelloWorldSpout() {
final Random rand = new Random();
referenceRandom = rand.nextInt(MAX_RANDOM);
}
/**
* 定义字段id,该id在简单模式下没有用处,但在按照字段分组的模式下有很大的用处。
* <p>
* 该declarer变量有很大作用,我们还可以调用declarer.declareStream();
* 来定义stramId,该id可以用来定义更加复杂的流拓扑结构
* </p>
* @param outputFieldsDeclarer
*/
@Override
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
outputFieldsDeclarer.declare(new Fields("sentence"));
}
/**
* 初始化collector
*
* @param map
* @param topologyContext
* @param spoutOutputCollector
*/
@Override
public void open(Map map, TopologyContext topologyContext,
SpoutOutputCollector spoutOutputCollector) {
this.collector = spoutOutputCollector;
}
/**
* 每调用一次就可以向storm集群中发射一条数据(一个tuple元组),该方法会被不停的调用
*/
@Override
public void nextTuple() {
Utils.sleep(100);
final Random rand = new Random();
int instanceRandom = rand.nextInt(MAX_RANDOM);
if (instanceRandom == referenceRandom) {
collector.emit(new Values("Hello World"));
} else {
collector.emit(new Values("Other Random Word"));
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
4.2.3 HelloWorldBolt.java
package com.zw.storm.helloworld;
import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.tuple.Tuple;
/**
* 接收喷发节点(Spout)发送的数据进行简单的处理后,发射出去。
* <p>
* 用于读取已产生的Tuple并实现必要的统计逻辑
* </p>
*
* Created by zhangws on 16/10/4.
*/
public class HelloWorldBolt extends BaseBasicBolt {
private int myCount;
@Override
public void execute(Tuple tuple, BasicOutputCollector collector) {
String test = tuple.getStringByField("sentence");
if ("Hello World".equals(test)) {
myCount++;
System.out.println("==========================: " + myCount);
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
4.2.4 HelloWorldTopology.java
package com.zw.storm.helloworld;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.StormSubmitter;
import backtype.storm.topology.TopologyBuilder;
import backtype.storm.utils.Utils;
/**
* mvn compile exec:java -Dexec.classpathScope=compile -Dexec.mainClass=com.zw.storm.helloworld.HelloWorldTopology
* Created by zhangws on 16/10/4.
*/
public class HelloWorldTopology {
public static void main(String[] args) throws Exception {
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("randomHelloWorld", new HelloWorldSpout(), 1);
builder.setBolt("HelloWorldBolt", new HelloWorldBolt(), 2)
.shuffleGrouping("randomHelloWorld");
Config config = new Config();
config.setDebug(true);
if (args != null && args.length > 0) {
config.setNumWorkers(1);
StormSubmitter.submitTopology(args[0], config, builder.createTopology());
} else {
config.setMaxTaskParallelism(1);
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("test", config, builder.createTopology());
Utils.sleep(10000);
cluster.killTopology("test");
cluster.shutdown();
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
4.2.5 运行
mvn compile exec:java -Dexec.classpathScope=compile -Dexec.mainClass=com.zw.storm.helloworld.HelloWorldTopology
修改storm-core依赖的scope为compile
结果
...
34568 [Thread-15-HelloWorldBolt] INFO backtype.storm.daemon.executor - Processing received message source: randomHelloWorld:3, stream: default, id: {}, [Other Random Word]
34671 [Thread-11-randomHelloWorld] INFO backtype.storm.daemon.task - Emitting: randomHelloWorld default [Hello World]
34671 [Thread-15-HelloWorldBolt] INFO backtype.storm.daemon.executor - Processing received message source: randomHelloWorld:3, stream: default, id: {}, [Hello World]
==========================: 5
34776 [Thread-11-randomHelloWorld] INFO backtype.storm.daemon.task - Emitting: randomHelloWorld default [Other Random Word]
34776 [Thread-15-HelloWorldBolt] INFO backtype.storm.daemon.executor - Processing received message source: randomHelloWorld:3, stream: default, id: {}, [Other Random Word]
34880 [Thread-11-randomHelloWorld] INFO backtype.storm.daemon.task - Emitting: randomHelloWorld default [Other Random Word]
...
4.3 与Kafka集成
4.3.1 pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>bigdata-demo</artifactId>
<groupId>com.zw</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>kafka2storm</artifactId>
<packaging>jar</packaging>
<name>kafka2storm</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<storm.version>0.9.7</storm.version>
<kafka.version>0.9.0.1</kafka.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>${storm.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-kafka</artifactId>
<version>${storm.version}</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.11</artifactId>
<version>${kafka.version}</version>
<exclusions>
<exclusion>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
</exclusion>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
<exclusion>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
4.3.2 MessageScheme.java
package com.zw.kafka.storm;
import backtype.storm.spout.Scheme;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import java.io.UnsupportedEncodingException;
import java.util.List;
/**
* 对kafka出来的数据转换成字符串
* <p>
* KafkaSpout是Storm中自带的Spout,
* 使用KafkaSpout时需要子集实现Scheme接口,它主要负责从消息流中解析出需要的数据
* </p>
*
* Created by zhangws on 16/10/2.
*/
public class MessageScheme implements Scheme {
public List<Object> deserialize(byte[] bytes) {
try {
String msg = new String(bytes, "UTF-8");
return new Values(msg);
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
return null;
}
public Fields getOutputFields() {
return new Fields("msg");
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
4.3.3 SequenceBolt.java
package com.zw.kafka.storm;
import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;
import java.io.DataOutputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
/**
* 把输出保存到一个文件中
* <p>
* 把输出的消息放到文件kafkastorm.out中
* </p>
*
* Created by zhangws on 16/10/2.
*/
public class SequenceBolt extends BaseBasicBolt {
/**
* Process the input tuple and optionally emit new tuples based on the input tuple.
* <p>
* All acking is managed for you. Throw a FailedException if you want to fail the tuple.
*
* @param input
* @param collector
*/
public void execute(Tuple input, BasicOutputCollector collector) {
String word = (String) input.getValue(0);
System.out.println("==============" + word);
try {
DataOutputStream out_file = new DataOutputStream(new FileOutputStream("/home/zkpk/kafkastorm.out"));
out_file.writeUTF(word);
out_file.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
collector.emit(new Values(word));
}
/**
* Declare the output schema for all the streams of this topology.
*
* @param declarer this is used to declare output stream ids, output fields, and whether or not each output stream is a direct stream
*/
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("message"));
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
4.3.4 KafkaTopology.java
package com.zw.kafka.storm;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.StormSubmitter;
import backtype.storm.spout.SchemeAsMultiScheme;
import backtype.storm.topology.TopologyBuilder;
import backtype.storm.utils.Utils;
import storm.kafka.BrokerHosts;
import storm.kafka.KafkaSpout;
import storm.kafka.SpoutConfig;
import storm.kafka.ZkHosts;
import storm.kafka.bolt.KafkaBolt;
import java.util.HashMap;
import java.util.Map;
/**
* 配置kafka提交topology到storm的代码
* <p>
* topic1的含义kafka接收生产者过来的数据所需要的topic;
* topic2是KafkaBolt也就是storm中的bolt生成的topic,当然这里topic2这行配置可以省略,
* 是没有任何问题的,类似于一个中转的东西
* </p>
* Created by zhangws on 16/10/2.
*/
public class KafkaTopology {
private static final String BROKER_ZK_LIST = "hsm01:2181,hss01:2181,hss02:2181";
private static final String ZK_PATH = "/kafka/brokers";
public static void main(String[] args) throws Exception {
BrokerHosts brokerHosts = new ZkHosts(BROKER_ZK_LIST, ZK_PATH);
SpoutConfig spoutConfig = new SpoutConfig(brokerHosts, "sogolog", "/kafka", "kafka");
Config conf = new Config();
Map<String, String> map = new HashMap<String, String>();
map.put("metadata.broker.list", "hsm01:9092");
map.put("serializer.class", "kafka.serializer.StringEncoder");
conf.put("kafka.broker.properties", map);
conf.put("topic", "topic2");
spoutConfig.scheme = new SchemeAsMultiScheme(new MessageScheme());
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("kafka-spout", new KafkaSpout(spoutConfig), 1);
builder.setBolt("kafka-bolt", new SequenceBolt()).shuffleGrouping("kafka-spout");
builder.setBolt("kafka-bolt2", new KafkaBolt<String, Integer>()).shuffleGrouping("kafka-bolt");
String name = KafkaTopology.class.getSimpleName();
if (args != null && args.length > 0) {
conf.put(Config.NIMBUS_HOST, args[0]);
conf.setNumWorkers(2);
StormSubmitter.submitTopology(name, conf, builder.createTopology());
} else {
conf.setMaxTaskParallelism(3);
LocalCluster cluster = new LocalCluster();
cluster.submitTopology(name, conf, builder.createTopology());
Utils.sleep(60000);
cluster.killTopology(name);
cluster.shutdown();
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
4.3.5 拷贝kafka依赖jar包到storm lib
cp ~/kafka_2.11-0.9.0.1/libs/kafka_2.11-0.9.0.1.jar ~/storm-0.9.7/lib/
cp ~/kafka_2.11-0.9.0.1/libs/scala-library-2.11.7.jar ~/storm-0.9.7/lib/
cp ~/kafka_2.11-0.9.0.1/libs/metrics-core-2.2.0.jar ~/storm-0.9.7/lib/
cp ~/kafka_2.11-0.9.0.1/libs/log4j-1.2.17.jar ~/storm-0.9.7/lib/
cp ~/kafka_2.11-0.9.0.1/libs/jopt-simple-3.2.jar ~/storm-0.9.7/lib/
4.3.2 运行
启动ZooKeeper与storm集群。
启动kafka
kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties
运行kafkatopology
storm jar /home/zkpk/doc/kafka2storm-1.0-SNAPSHOT-jar-with-dependencies.jar com.zw.kafka.storm.KafkaTopology hsm01
创建一个订阅者
--. -- -- ---
启动kafka生产者
kafka-console-producer.sh --broker-list hsm01:9092 --topic sogolog
结果
[zkpk@hsm01 ~]$ kafka-console-producer.sh --broker-list hsm01:9092 --topic sogolog
nihao
hello storm-kafka
你好,storm-kafka
[zkpk@hsm01 ~]$ kafka-console-consumer.sh --zookeeper hsm01:2181/kafka --topic topic2 --from-beginning
nihao
hello storm-kafka
你好,storm-kafka
4.4 参考
storm-starter IDE 下的调试经历
kafka与storm集成测试问题小结
Storm集成Kafka应用的开发
KafkaSpout 引起的 log4j 的问题
<dependencies>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>1.0.2</version>
<!--
由于storm环境中有该jar,所以不用pack到最终的task.jar中
-->
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-kafka</artifactId>
<version>1.0.2</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.3.2</version>
</dependency>
<!-- kafka目前已经有2.10了,但是我用了,任务执行报错,目前只能用kafka_2.9.2,我kafka服务端也是用最新的2.10版本
-->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.9.2</artifactId>
<version>0.8.2.2</version>
<!--
排除以下jar,由于storm服务端有log4j,避免冲突报错-->
<exclusions>
<exclusion>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
</exclusion>
<exclusion>
<groupId>log4j</groupId>
<artifactId>log4j<artifactId>
</exclusion>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>1.4.4</version>
<exclusions>
<exclusion>
<groupId>log4j</groupId>
<artifactId>log4j<artifactId>
</exclusion>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<encoding>utf-8</encoding>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<archive>
<manifest><manifest>
</archive>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<encoding>utf-8</encoding>
</configuration>
</plugin>
</plugins>
</build>
5. Flume、Kafka与Storm集成测试
# 启动经过storm处理的订阅者
kafka-console-consumer.sh --zookeeper hsm01:2181/kafka --topic topic2
# 运行kafkatopology
storm jar /home/zkpk/doc/kafka2storm-1.0-SNAPSHOT-jar-with-dependencies.jar com.zw.kafka.storm.KafkaTopology hsm01
# 启动flume
flume-ng agent -n a1 -c conf -f /home/zkpk/flume-1.6.0/conf/kafka-sogolog.properties -Dflume.root.logger=DEBUG,console
# 复制文件到flume监视目录
cp test.log flume/