版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/wen_fei/article/details/84923094
大数据求索(6): 使用Flume进行数据采集
大数据最好的学习资料是官方文档。
Flume官方文档地址http://flume.apache.org/
Flume简单介绍
Flume是一种分布式的、可靠的且可用的服务,用于高效收集、聚合和移动大量日志数据。它具有基于流式数据的简单灵活架构。它具有可靠性机制和许多故障转移和恢复机制,具有强大的容错能力。它使用简单的可扩展数据模型,允许在线分析应用程序。
基本架构
它包括三个基本组件:
重要名词
Event:消息,事件,在Flume中数据传输的单位是“event”,Flume将解析的日志数据、接收到的TCP数据等分装成events在内部Flow中传递。
Agent:临近数据源(比如logs文件)的、部署在宿主机器上的Flume进程,通常用于收集、过滤、分拣数据,Flume Agent通常需要对源数据进行“修饰”后转发给远端的Collector。
设计目标
1. 可靠性
当节点出现故障时,日志能够被传送到其他节点上而不会丢失。Flume提供了两种级别的可靠性保障,分别为:
- end-to-end:收集数据的agent首先将event写到磁盘上,当数据传送成功后,再删除;如果传送失败,可以重新发送。
- 事务:Sources和Sinks在存储、检索的操作都会分别分装在由Channel提供的事务中,这可以确保一组消息在Flow内部点对点传递的可靠性(source->channel->sink)。即使在多级Flows模式中,上一级的sink和下一级的source之间的数据传输也运行在各自的事务中,以确保数据可以安全的被存储在下一级的channel中。
2. 可扩展性
Flume采用了三层架构,分别为source、channel和sink,每一层均可以水平扩展。三个组件构成一个Agent,不同Agent之间又可以连接起来,形成数据之间的流通。
重要名词概念解释
- agent:Flume内部组件之一,用于解析原始数据并封装成event、或者是接收Client端发送的Flume Events;对于Flume进程而言,source是整个数据流(Data Flow)的最前端,用于“产生”events。说白了,这其实是一个“读”行为。
- Flume内部组件之一,用于“传输”events的通道,Channel通常具备“缓存”数据、“流量控制”等特性;Channel的upstream端是Source,downstream为Sink。这个一般放在内存中。
- Sink:Flume内部组件之一,用于将内部的events通过合适的协议发送给第三方组件,比如Sink可以将events写入本地磁盘文件、基于Avro协议通过TCP方式发给其他Flume,可以发给kafka等其他数据存储平台等;Sink最终将events从内部数据流中移除。这其实是一个“写”行为。
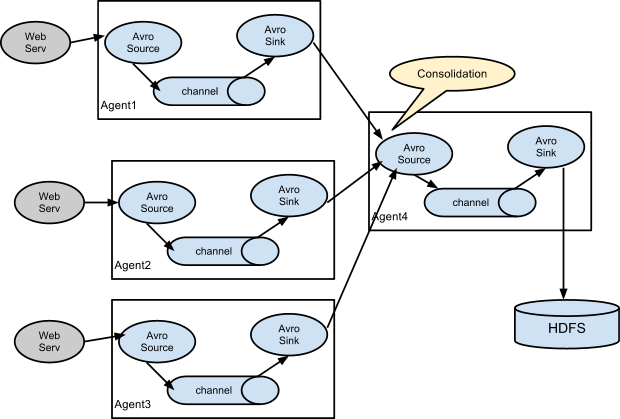
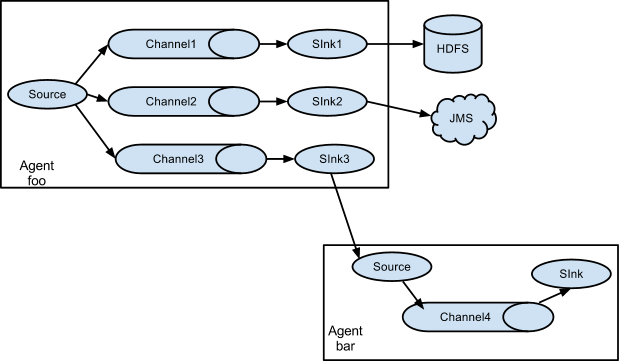
常见架构:
3. 容错性
Flume支持持久类型的FileChannel,即Channel的消息可以被保存在本地的文件系统中,这种Channel支持数据恢复。此外,还支持MemoryChannel,它是基于内存的队列,效率很高但是当Agent进程失效后,那些遗留在Channel中的消息将会丢失(而无法恢复)。
Flume安装
依赖
Flume基于java开发,需要jdk支持,最新的Flume1.8.0需要jdk1.8+。
下载
这里使用的是1.6.0的cdh5.7.0版本,下载地址
wget http://archive.cloudera.com/cdh5/cdh/5/flume-ng-1.6.0-cdh5.7.0.tar.gz
解压
tar -zxvf flume-ng-1.6.0-cdh5.7.0.tar.gz
配置环境变量
vim ~/.bashrc
export FLUME_HOME=/home/hadoop/hadoop/APP/Hadoop/apache-flume-1.6.0-cdh5.7.0-bin
export PATH=$FLUME_HOME/bin:$PATH
source ~/.bashrc
Flume实战
一、单机Flume:监听一个端口收集数据并打印
使用Flume的关键就是写配置文件
在conf目录下修改example.conf文件,内容如下:
a1.sources = r1
a1.sinks = k1
a1.channels = c1
a1.sources.r1.type = netcat
a1.sources.r1.bind = wds
a1.sources.r1.port = 44444
a1.sinks.k1.type = logger
a1.channels.c1.type = memory
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
很多写法都是固定的,配置好文件以后就可以启动:
flume-ng agent \
--name a1 \
--conf $FLUME_HOME/conf \
--conf-file $FLUME_HOME/conf/example.conf \
-Dflume.root.logger=INFO,console
启动以后使用Telnet进行测试
telnet wds 44444
输出结果如下:
...
Event: { headers:{} body: 68 65 6C 6C 6F 0D hello. }
证明启动成功!
Event是Flume数据传输的基本单元
Event = 可选的header + byte array
二、监控文件,实时采集文件新增的数据
-
写配置文件
Agent类型为exec source + memory channel + logger sink
配置文件如下:
a1.sources = r1
a1.sinks = k1
a1.channels = c1
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/hadoop/hadoop/data/flumetest.log
a1.sources.r1.shell = /bin/sh -c
a1.sinks.k1.type = logger
a1.channels.c1.type = memory
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
-
启动
flume-ng agent \
--name a1 \
--conf $FLUME_HOME/conf \
--conf-file $FLUME_HOME/conf/exec-memory-logger.conf \
-Dflume.root.logger=INFO,console
-
测试
echo hello >> flumetest.log
echo world >> flumetest.log
可以看到控制台有数据输出,证明配置成功。
三、跨机器收集数据
跨节点一般采用avro source和avro sink
exec-memory-avro.sources = exec-source
exec-memory-avro.sinks = avro-sink
exec-memory-avro.channels = memory-channel
exec-memory-avro.sources.exec-source.type = exec
exec-memory-avro.sources.exec-source.command = tail -F /home/hadoop/hadoop/data/flumetest.log
exec-memory-avro.sources.exec-source.shell = /bin/sh -c
exec-memory-avro.sinks.avro-sink.type = avro
exec-memory-avro.sinks.avro-sink.hostname = wds002
exec-memory-avro.sinks.avro-sink.port = 44444
exec-memory-avro.channels.memory-channel.type = memory
exec-memory-avro.sources.exec-source.channels = memory-channel
exec-memory-avro.sinks.avro-sink.channel = memory-channel
第二台机器wds002:avro source + memory channel + logger sink
配置文件avro-memory-logger.conf如下:
avro-memory-logger.sources = avro-source
avro-memory-logger.sinks = logger-sink
avro-memory-logger.channels = memory-channel
avro-memory-logger.sources.avro-source.type = avro
avro-memory-logger.sources.avro-source.bind = wds002
avro-memory-logger.sources.avro-source.port = 44444
avro-memory-logger.sinks.logger-sink.type = logger
avro-memory-logger.channels.memory-channel.type = memory
avro-memory-logger.sources.avro-source.channels = memory-channel
avro-memory-logger.sinks.logger-sink.channel = memory-channel
-
启动:
先启动avro-memory-logger
flume-ng agent \
--name avro-memory-logger \
--conf $FLUME_HOME/conf \
--conf-file $FLUME_HOME/conf/avro-memory-logger.conf \
-Dflume.root.logger=INFO,console
再启动exec-memory-avro
flume-ng agent \
--name exec-memory-avro \
--conf $FLUME_HOME/conf \
--conf-file $FLUME_HOME/conf/exec-memory-avro.conf \
-Dflume.root.logger=INFO,console
echo hello >> flumetest.log
echo world >> flumetest.log
可以看到第二台机器控制台有输出。
最后
Flume基于灵活的配置,所有配置都可以在官方文档查到,比如监控Http、监控文件、监控log4j日志等,按照固定的写法写就可以。
参考资料
- 官方文档http://flume.apache.org/FlumeUserGuide.html
- 博客https://shift-alt-ctrl.iteye.com/blog/2363884