一、第一代hadoop组成与结构
第一代Hadoop,由分布式存储系统HDFS和分布式计算框架MapReduce组成,其中,HDFS由一个NameNode和多个DataNode组成,MapReduce由一个JobTracker和多个TaskTracker组成,对应Hadoop版本为Hadoop 1.x和0.21.X,0.22.x。
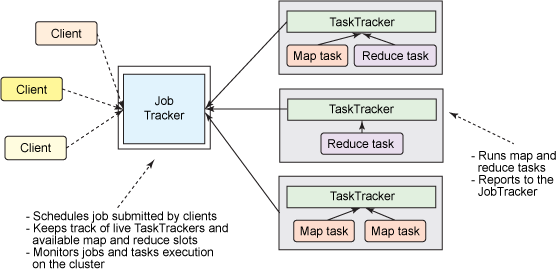
1、MapReduce角色分配
Client :作业提交发起者。
JobTracker: 初始化作业,分配作业,与TaskTracker通信,协调整个作业。
TaskTracker:保持JobTracker通信,在分配的数据片段上执行MapReduce任务。
2、MapReduce执行流程
(1)提交作业
在作业提交之前,需要对作业进行配置
程序代码,主要是自己书写的MapReduce程序。
输入输出路径
其他配置,如输出压缩等。
配置完成后,通过JobClinet来提交
(2)作业的初始化
客户端提交完成后,JobTracker会将作业加入队列,然后进行调度,默认的调度方法是FIFO调试方式。
(3)任务的分配
TaskTracker和JobTracker之间的通信与任务的分配是通过心跳机制完成的。
TaskTracker会主动向JobTracker询问是否有作业要做,如果自己可以做,那么就会申请到作业任务,这个任务可以使Map也可能是Reduce任务。
(4)任务的执行
申请到任务后,TaskTracker会做如下事情:
拷贝代码到本地
拷贝任务的信息到本地
启动JVM运行任务
(5)状态与任务的更新
任务在运行过程中,首先会将自己的状态汇报给TaskTracker,然后由TaskTracker汇总告之JobTracker。
任务进度是通过计数器来实现的。
(6)作业的完成
JobTracker是在接受到最后一个任务运行完成后,才会将任务标志为成功。
此时会做删除中间结果等善后处理工作。
3、经典 MapReduce的局限性
经典MapReduce最严重的限制:可伸缩性、资源利用、对不同工作负载的支持
在 MapReduce 框架中,作业执行受两种类型的进程控制:
- 一个称为 JobTracker 的主要进程,它协调在集群上运行的所有作业,分配要在 TaskTracker 上运行的 map 和 reduce 任务。
- 许多称为 TaskTracker 的下级进程,它们运行分配的任务并定期向 JobTracker 报告进度。
Apache Hadoop 的经典版本 (MRv1)

大型的 Hadoop 集群显现出了由单个 JobTracker 导致的可伸缩性瓶颈。依据 Yahoo!,在集群中有 5,000 个节点和 40,000 个任务同时运行时,这样一种设计实际上就会受到限制。由于此限制,必须创建和维护更小的、功能更差的集群。
此外,较小和较大的 Hadoop 集群都从未最高效地使用他们的计算资源。在 Hadoop MapReduce 中,每个从属节点上的计算资源由集群管理员分解为固定数量的 map 和 reduce slot,这些 slot 不可替代。设定 map slot 和 reduce slot 的数量后,节点在任何时刻都不能运行比 map slot 更多的 map 任务,即使没有 reduce 任务在运行。这影响了集群的利用率,因为在所有 map slot 都被使用(而且我们还需要更多)时,我们无法使用任何 reduce slot,即使它们可用,反之亦然。
解决可伸缩性问题
在Hadoop MapReduce中,JobTracker具有两种不同的职责:
- 管理集群中的计算资源,这涉及到维护活动节点列表、可用和占用的 map 和 reduce slots 列表,以及依据所选的调度策略将可用 slots 分配给合适的作业和任务
- 协调在集群上运行的所有任务,这涉及到指导 TaskTracker 启动 map 和 reduce 任务,监视任务的执行,重新启动失败的任务,推测性地运行缓慢的任务,计算作业计数器值的总和,等等
为单个进程安排大量职责会导致重大的可伸缩性问题,尤其是在较大的集群上,JobTracker 必须不断跟踪数千个 TaskTracker、数百个作业,以及数万个 map 和 reduce 任务。下图演示了这一问题。相反,TaskTracker 通常仅运行十来个任务,这些任务由勤勉的 JobTracker 分配给它们。
大型 Apache Hadoop 集群 (MRv1) 上繁忙的 JobTracker

为了解决可伸缩性问题,一个简单而又绝妙的想法应运而生:我们减少了单个 JobTracker 的职责,将部分职责委派给 TaskTracker,因为集群中有许多 TaskTracker。在新设计中,这个概念通过将 JobTracker 的双重职责(集群资源管理和任务协调)分开为两种不同类型的进程来反映。
不再拥有单个 JobTracker,一种新方法引入了一个集群管理器,它惟一的职责就是跟踪集群中的活动节点和可用资源,并将它们分配给任务。对于提交给集群的每个作业,会启动一个专用的、短暂的 JobTracker来控制该作业中的任务的执行。有趣的是,短暂的 JobTracker 由在从属节点上运行的TaskTracker启动。因此,作业的生命周期的协调工作分散在集群中所有可用的机器上。得益于这种行为,更多工作可并行运行,可伸缩性得到了显著提高。
二、第二代hadoop组成与结构
第二代Hadoop,为克服Hadoop 1.0中HDFS和MapReduce存在的各种问题而提出的。针对Hadoop 1.0中的单NameNode制约HDFS的扩展性问题,提出了HDFS Federation,它让多个NameNode分管不同的目录进而实现访问隔离和横向扩展;针对Hadoop 1.0中的MapReduce在扩展性和多框架支持方面的不足,提出了全新的资源管理框架YARN(Yet Another Resource Negotiator),它将JobTracker中的资源管理和作业控制功能分开,分别由组件ResourceManager和ApplicationMaster实现,其中,ResourceManager负责所有应用程序的资源分配,而ApplicationMaster仅负责管理一个应用程序。对应Hadoop版本为Hadoop 0.23.x和2.x。
YARN的架构
- ResourceManager 代替集群管理器
- ApplicationMaster 代替一个专用且短暂的 JobTracker
- NodeManager 代替 TaskTracker
- 一个分布式应用程序代替一个 MapReduce 作业
YARN的架构

YARN总体上仍然是master/slave结构,在整个资源管理框架中,resourcemanager为master,nodemanager是slave。Resourcemanager负责对各个nademanger上资源进行统一管理和调度。当用户提交一个应用程序时,需要提供一个用以跟踪和管理这个程序的ApplicationMaster,它负责向ResourceManager申请资源,并要求NodeManger启动可以占用一定资源的任务。由于不同的ApplicationMaster被分布到不同的节点上,因此它们之间不会相互影响。
YARN的基本组成结构,YARN主要由ResourceManager、NodeManager、ApplicationMaster和Container等几个组件构成。
ResourceManager是Master上一个独立运行的进程,负责集群统一的资源管理、调度、分配等等;NodeManager是Slave上一个独立运行的进程,负责上报节点的状态;App Master和Container是运行在Slave上的组件,Container是yarn中分配资源的一个单位,包涵内存、CPU等等资源,yarn以Container为单位分配资源。
Client向ResourceManager提交的每一个应用程序都必须有一个Application Master,它经过ResourceManager分配资源后,运行于某一个Slave节点的Container中,具体做事情的Task,同样也运行与某一个Slave节点的Container中。RM,NM,AM乃至普通的Container之间的通信,都是用RPC机制。
1、Resourcemanager
RM是一个全局的资源管理器,集群只有一个,负责整个系统的资源管理和分配,包括处理客户端请求、启动/监控APP master、监控nodemanager、资源的分配与调度。它主要由两个组件构成:调度器(Scheduler)和应用程序管理器(Applications Manager,ASM)。
(1) 调度器
调度器根据容量、队列等限制条件(如每个队列分配一定的资源,最多执行一定数量的作业等),将系统中的资源分配给各个正在运行的应用程序。需要注意的是,该调度器是一个“纯调度器”,它不再从事任何与具体应用程序相关的工作,比如不负责监控或者跟踪应用的执行状态等,也不负责重新启动因应用执行失败或者硬件故障而产生的失败任务,这些均交由应用程序相关的ApplicationMaster完成。调度器仅根据各个应用程序的资源需求进行资源分配,而资源分配单位用一个抽象概念“资源容器”(Resource Container,简称Container)表示,Container是一个动态资源分配单位,它将内存、CPU、磁盘、网络等资源封装在一起,从而限定每个任务使用的资源量。此外,该调度器是一个可插拔的组件,用户可根据自己的需要设计新的调度器,YARN提供了多种直接可用的调度器,比如Fair Scheduler和Capacity Scheduler等。
(2) 应用程序管理器
应用程序管理器负责管理整个系统中所有应用程序,包括应用程序提交、与调度器协商资源以启动ApplicationMaster、监控ApplicationMaster运行状态并在失败时重新启动它等。
2.ApplicationMaster(AM)
管理YARN内运行的应用程序的每个实例。
功能:
数据切分
为应用程序申请资源并进一步分配给内部任务。
任务监控与容错
负责协调来自resourcemanager的资源,并通过nodemanager监视容易的执行和资源使用情况。
3. NodeManager(NM)
Nodemanager整个集群有多个,负责每个节点上的资源和使用。
功能:
单个节点上的资源管理和任务。
处理来自于resourcemanager的命令。
处理来自域app master的命令。
Nodemanager管理着抽象容器,这些抽象容器代表着一些特定程序使用针对每个节点的资源。
Nodemanager定时地向RM汇报本节点上的资源使用情况和各个Container的运行状态(cpu和内存等资源)
4.Container
Container是YARN中的资源抽象,它封装了某个节点上的多维度资源,如内存、CPU、磁盘、网络等,当AM向RM申请资源时,RM为AM返回的资源便是用Container表示的。YARN会为每个任务分配一个Container,且该任务只能使用该Container中描述的资源。需要注意的是,Container不同于MRv1中的slot,它是一个动态资源划分单位,是根据应用程序的需求动态生成的。目前为止,YARN仅支持CPU和内存两种资源,且使用了轻量级资源隔离机制Cgroups进行资源隔离。
功能:
对task环境的抽象
描述一系列信息
任务运行资源的集合(cpu、内存、io等)
任务运行环境
一个可运行任何分布式应用程序的集群
ResourceManager、NodeManager 和容器都不关心应用程序或任务的类型。所有特定于应用程序框架的代码都转移到它的 ApplicationMaster,以便任何分布式框架都可以受 YARN 支持 ― 只要有人为它实现了相应的 ApplicationMaster。
得益于这个一般性的方法,Hadoop YARN 集群运行许多不同工作负载的梦想才得以实现。想像一下:您数据中心中的一个 Hadoop 集群可运行 MapReduce、Giraph、Storm、Spark、Tez/Impala、MPI 等。
单一集群方法明显提供了大量优势,其中包括:
- 更高的集群利用率,一个框架未使用的资源可由另一个框架使用
- 更低的操作成本,因为只有一个 “包办一切的” 集群需要管理和调节
- 更少的数据移动,无需在 Hadoop YARN 与在不同机器集群上运行的系统之间移动数据
管理单个集群还会得到一个更环保的数据处理解决方案。使用的数据中心空间更少,浪费的硅片更少,使用的电源更少,排放的碳更少,这只是因为我们在更小但更高效的 Hadoop 集群上运行同样的计算。
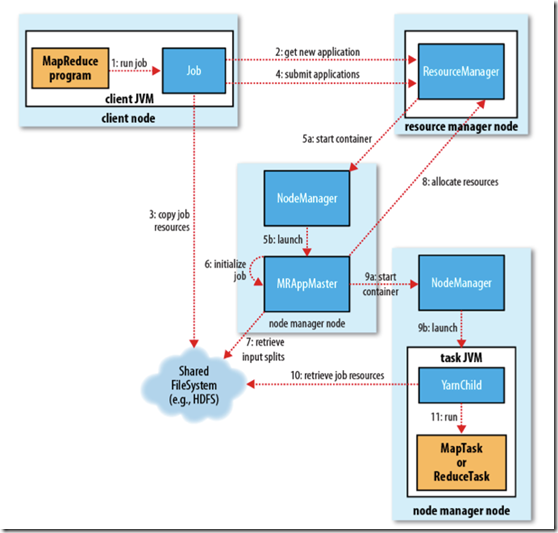
图2 MR2工作原理图
工作流程主要分为以下6步执行:
1作业的提交
1)、客户端向ResourceManager请求一个新的作业ID,ResourceManager收到后,回应一个ApplicationID,见第2步
2)、计算作业的输入分片,将运行作业所需要的资源(包括jar文件、配置文件和计算得到的输入分片)复制到一个(HDFS),见第3步
3)、告知ResourceManager作业准备执行,并且调用submitApplication()提交作业,见第4步
2作业的初始化
4)、ResourceManager收到对其submitApplication()方法的调用后,会把此调用放入一个内部队列中,交由作业调度器进行调度,并对其初始化,然后为该其分配一个contain容器,见第5步
5)、并与对应的NodeManager通信见第5a步,要求它在Contain中启动ApplicationMaster见第5b步
6)、ApplicationMaster启动后,会对作业进行初始化,并保持作业的追踪见第6步.
7)、ApplicationMaster从HDFS中共享资源,,接受客户端计算的输入分片为每个分片。见第7步
3任务的分配
8)、ApplicationMaster想ResourceManager注册,这样就可以直接通过RM查看应用的运行状态,然后为所有的map和reduce任务获取资源,见第8步
4任务的执行
9)、ApplicationMaster申请到资源后,与NodeManager进行交互,要求它在Contain容器中启动执行任务。见第9a、9b步
5进度和状态的更新
10)、各个任务通过RPC协议umbilical接口向ApplicationMaster汇报自己的状态和进度,方便ApplicationMaster随时掌握各个任务的运行状态。用户也可以向ApplicationMaster查询运行状态。
6作业的完成
11)、应用完成后,ApplicationMaster向ResourceManager注销并关闭自己。
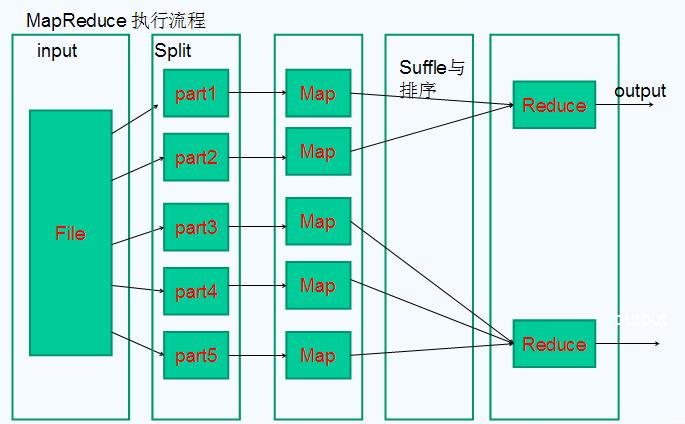
三、shuffle
shuffle详细讲解
四、hadoop实现的数据类型
https://blog.csdn.net/zhang0558/article/details/53444533