1�����
1.1��Kafka Consumer�ṩ��2��API��high level��low level��SimpleConsumer����
1��Read a message multiple times
2��Consume only a subset of the partitions in a topic in a process
3��Manage transactions to make sure a message is processed once and only once
2��Flink�Ŀ�����
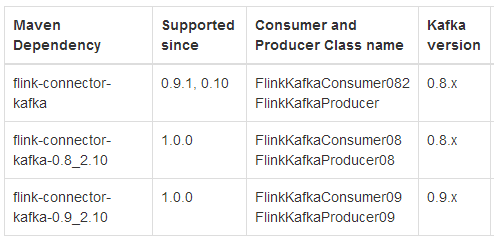
Flink�ṩ��high level��API������kafka�����ݣ�flink-connector-kafka-0.8_2.10��ע�⣬�����0.8��������kafka�İ汾�������ͨ��maven������kafka���������������£�
�������kafka��װ�汾�ǡ�kafka_2.10-0.8.2.1��,���˰汾����scala2.10��д��kafka�������汾��0.8.2.1.�Ǵ�ʱ����Ҫ�������µ����ݵ�maven��pom.xml�ļ��У�
<dependency >
<groupId > org.apache.flink</groupId >
<artifactId > flink-connector-kafka-0.8_2.10</artifactId >
<version > ${flink.version}</version >
</dependency > ע�⣺
<properties >
<project.build.sourceEncoding > UTF-8</project.build.sourceEncoding >
<flink.version > 1.0.0</flink.version >
</properties > 3����Ⱥ������
������Ҫ�ǽ�����Flink��Ⱥ��kafka��Ⱥ�Ĵ��
3.1��Flink��Ⱥ���ã�standalone��û����zookeeper��HA��
3.1.1����������
export FLINK_HOME=/usr/local/flink/flink-1.0 .3
export PATH=.:${JAVA_HOME} /bin:${SCALA_HOME} /bin:${HADOOP_HOME} /bin:${HADOOP_HOME} /sbin:${ZOOKEEPER_HOME} /bin:${KAFKA_HOME} /bin:${FLINK_HOME} /bin:$PATH
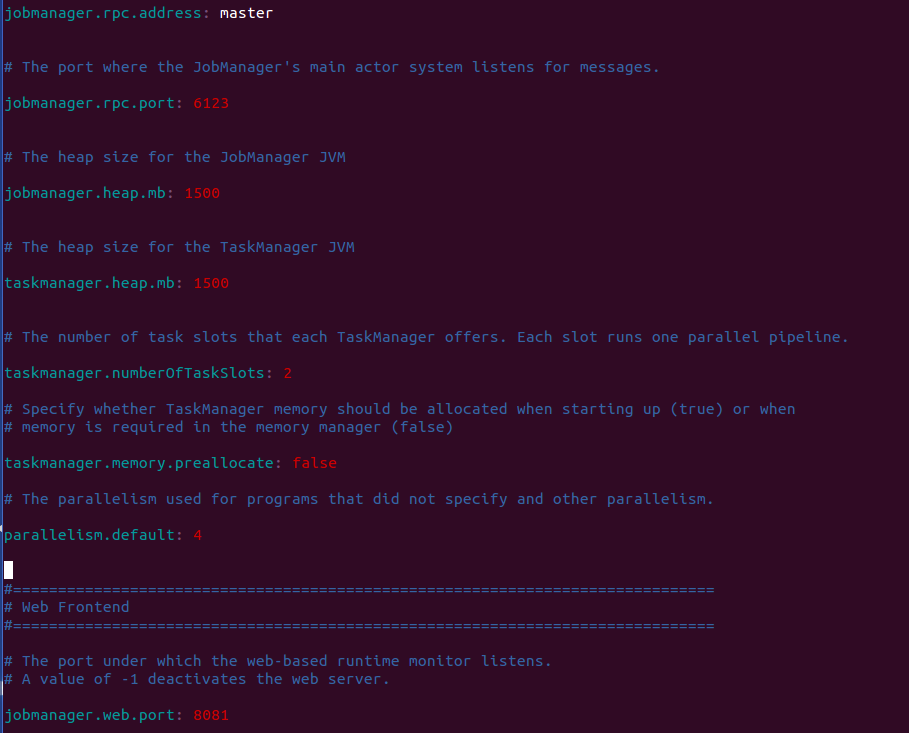
export CLASS_PATH=.:${JAVA_HOME} /lib:${JRE_HOME} /lib3.1.2����conf/flink-conf.yaml
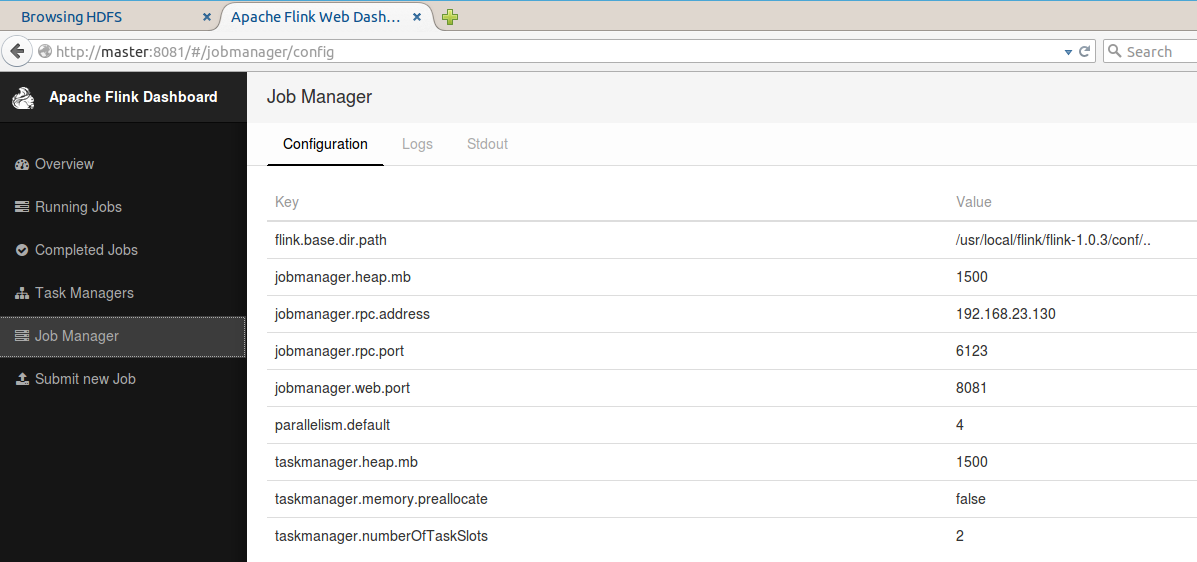
�⼸����������÷�ʽ�ˣ���Ҫע��Ҫ��jobmanager.rpc.addressΪ��Ⱥ��jobManager��IP��hostname�������Լ�HA�IJ�����û�����á�
3.1.3��slaves�ļ�
����ļ��д�ŵ���Ϣ��taskmanager��hostname��
3.1.4������flinkĿ¼�Լ�.bashrc�ļ�����Ⱥ�������Ļ�������ʹbashrc��Ч
root@master :/usr/local/flink
root@master :/usr/local/flink
root@master :/usr/local/flink
root@master :/usr/local/flink
root@worker1 :~
root@worker2 :~ 3.2��kafka��Ⱥ����
3.2.1����������
3.2.2������config/zookeeper.properties
3.2.3������config/server.properties
broker.id=0
listeners=PLAINTEXT :// :9092 broker.id��kafka��Ⱥ��ÿ̨�����϶���һ����������3̨��Ⱥ�ֱ���0��1��2.
zookeeper.connect=master :2181 ,worker1 :2181 ,worker2 :2181
zookeeper.connection.timeout.ms=6000
zookeeper.connectҪ����kafka��Ⱥ��������zookeeper��Ⱥ����Ϣ��hostname:port��
3.2.4������kafka·������������������kafka��Ⱥ�Ļ���������server.properties�е�broker_id.
3.3������kafka��Ⱥ+Flink��Ⱥ
3.3.1����������zookeeper��Ⱥ��3̨zookeeper������Ҫ��������
root@master :/usr/local/zookeeper/zookeeper- 3.4 .6 /bin
root@worker1 :/usr/local/zookeeper/zookeeper- 3.4 .6 /bin
root@worker2 :/usr/local/zookeeper/zookeeper- 3.4 .6 /bin��֤zookeeper��Ⱥ��
root@master :/usr/local/zookeeper/zookeeper- 3.4 .6 /bin
3295 QuorumPeerMain
root@master :/usr/local/zookeeper/zookeeper- 3.4 .6 /bin
JMX enabled by default
Using config: /usr/local/zookeeper/zookeeper-3.4 .6 /bin/../conf/zoo.cfg
Mode : follower
root@master :/usr/local/zookeeper/zookeeper- 3.4 .6 /bin
root@worker1 :/usr/local/zookeeper/zookeeper- 3.4 .6 /bin
JMX enabled by default
Using config: /usr/local/zookeeper/zookeeper-3.4 .6 /bin/../conf/zoo.cfg
Mode : follower
root@worker1 :/usr/local/zookeeper/zookeeper- 3.4 .6 /bin
root@worker2 :/usr/local/zookeeper/zookeeper- 3.4 .6 /bin
JMX enabled by default
Using config: /usr/local/zookeeper/zookeeper-3.4 .6 /bin/../conf/zoo.cfg
Mode : leader
root@worker2 :/usr/local/zookeeper/zookeeper- 3.4 .6 /bin3.3.2������kafka��Ⱥ��3̨��Ҫ������
root@master :/usr/local/kafka/kafka_2 .10 -0 .8.2 .1 /bin
root@worker1 :/usr/local/kafka/kafka_2 .10 -0 .8.2 .1 /bin
root@worker2 :/usr/local/kafka/kafka_2 .10 -0 .8.2 .1 /bin��֤��
3512 Kafka3.3.3������hdfs��master���������ɣ�
root@master :/usr/local/hadoop/hadoop- 2.6 .0 /sbin��֤�����̼�webUI
root@master :/usr/local/hadoop/hadoop- 2.6 .0 /sbin
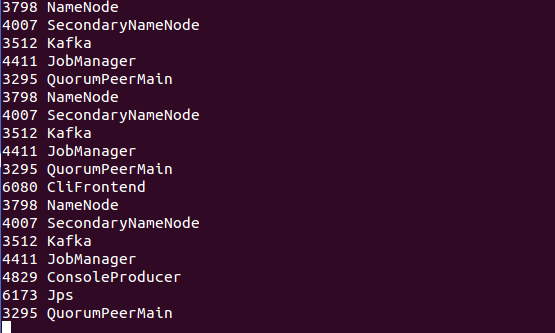
3798 NameNode
4007 SecondaryNameNode
root@worker1 :/usr/local/hadoop/hadoop- 2.6 .0 /sbin
3843 DataNode
root@worker2 :/usr/local/hadoop/hadoop- 2.6 .0 /sbin
3802 DataNode webUI��50070��Ĭ�Ͽ�����
3.3.4������Flink��Ⱥ��master���ɣ�
root@master :/usr/local/flink/flink- 1.0 .3 /bin��֤�����̼�WebUI
root@master :/usr/local/flink/flink- 1.0 .3 /bin
4411 JobManager
root@worker1 :/usr/local/flink/flink- 1.0 .3 /bin
4151 TaskManager
root@worker2 :/usr/local/flink/flink- 1.0 .3 /bin
4110 TaskManager WebUI��8081��Ĭ�ϣ������ã�
4����дFlink����ʵ��consume kafka�����ݣ�demo��
4.1������
import java .util .Properties
import org.apache .flink .streaming .api .{CheckpointingMode, TimeCharacteristic}
import org.apache .flink .streaming .api .scala .StreamExecutionEnvironment
import org.apache .flink .streaming .connectors .kafka .FlinkKafkaConsumer 08
import org.apache .flink .streaming .util .serialization .SimpleStringSchema
import org.apache .flink .streaming .api .scala ._
object ReadingFromKafka {
private val ZOOKEEPER_HOST = "master:2181,worker1:2181,worker2:2181"
private val KAFKA_BROKER = "master:9092,worker1:9092,worker2:9092"
private val TRANSACTION_GROUP = "transaction"
def main(args : Array[String]){
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic (TimeCharacteristic.EventTime )
env.enableCheckpointing (1000 )
env.getCheckpointConfig .setCheckpointingMode (CheckpointingMode.EXACTLY _ONCE)
// configure Kafka consumer
val kafkaProps = new Properties()
kafkaProps.setProperty ("zookeeper.connect" , ZOOKEEPER_HOST)
kafkaProps.setProperty ("bootstrap.servers" , KAFKA_BROKER)
kafkaProps.setProperty ("group.id" , TRANSACTION_GROUP)
//topicd��������new��schemaĬ��ʹ��SimpleStringSchema()����
val transaction = env
.addSource (
new FlinkKafkaConsumer08[String]("new" , new SimpleStringSchema(), kafkaProps)
)
transaction.print ()
env.execute ()
}
}4.2�������
mvn clean package
4.3����������Ⱥ
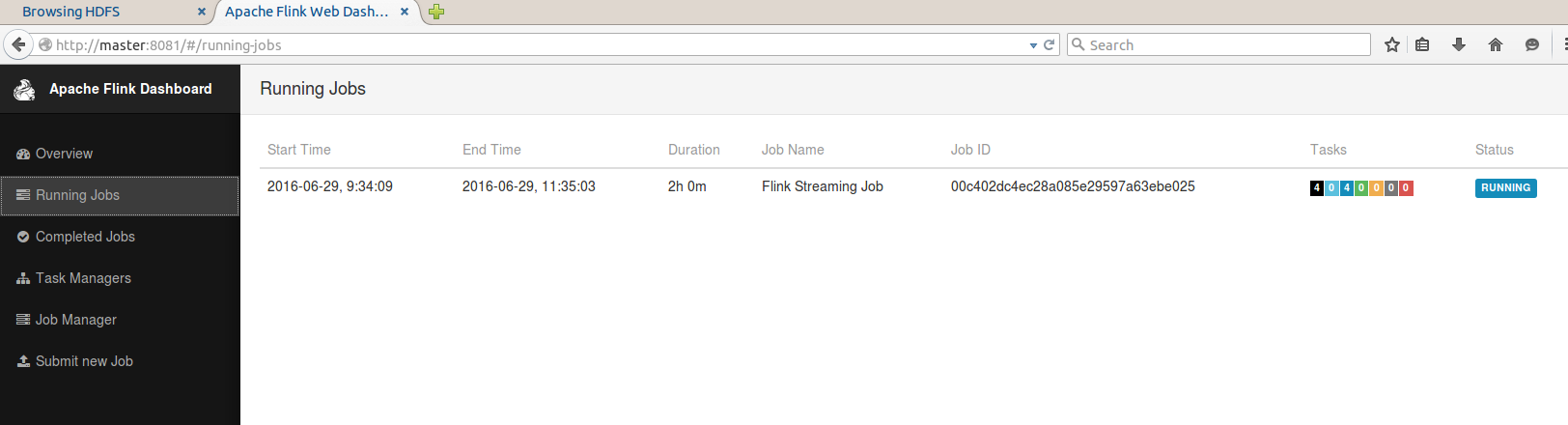
root@master :/usr/local/flink/flink- 1.0 .3 /bin��֤�����̼�WebUI
root@master :/usr/local/flink/flink- 1.0 .3 /bin
6080 CliFrontend
5��kafka produce���ݣ���֤flink�Ƿ���������
5.1��ͨ��kafka console produce����
root@master :/usr/local/kafka/kafka_2 .10 -0 .8.2 .1 /bin�������ݣ�
5.2���鿴flink�ı�����У��Ƿ��Ѿ��������ⲿ�����ݣ�
root@worker2 :/usr/local/flink/flink- 1.0 .3 /log
-rw-r--r-- 1 root root 254 6 �� 29 09: 37 flink-root-taskmanager-0 -worker2.out
root@worker2 :/usr/local/flink/flink- 1.0 .3 /log������worker2��log�з����Ѿ��������ݣ����濴�����ݣ�
OK��û���⣬flink�������������ݡ�
6���ܽ�
kafka��Ϊһ����Ϣϵͳ���������и����¡�����ʱ���־û����ֲ�ʽ���ص㣬��topic����ָ��replication�Լ�partitions��ʹ�ÿɿ��Ժ����ܶ����Ժܺõı�֤��
�ο� http://www.tuicool.com/articles/fI7J3m https://ci.apache.org/projects/flink/flink-docs-master/apis/streaming/connectors/kafka.html http://kafka.apache.org/082/documentation.html http://dataartisans.github.io/flink-training/exercises/toFromKafka.html http://data-artisans.com/kafka-flink-a-practical-how-to/