版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/jiecxy/article/details/58153648
1. 介绍
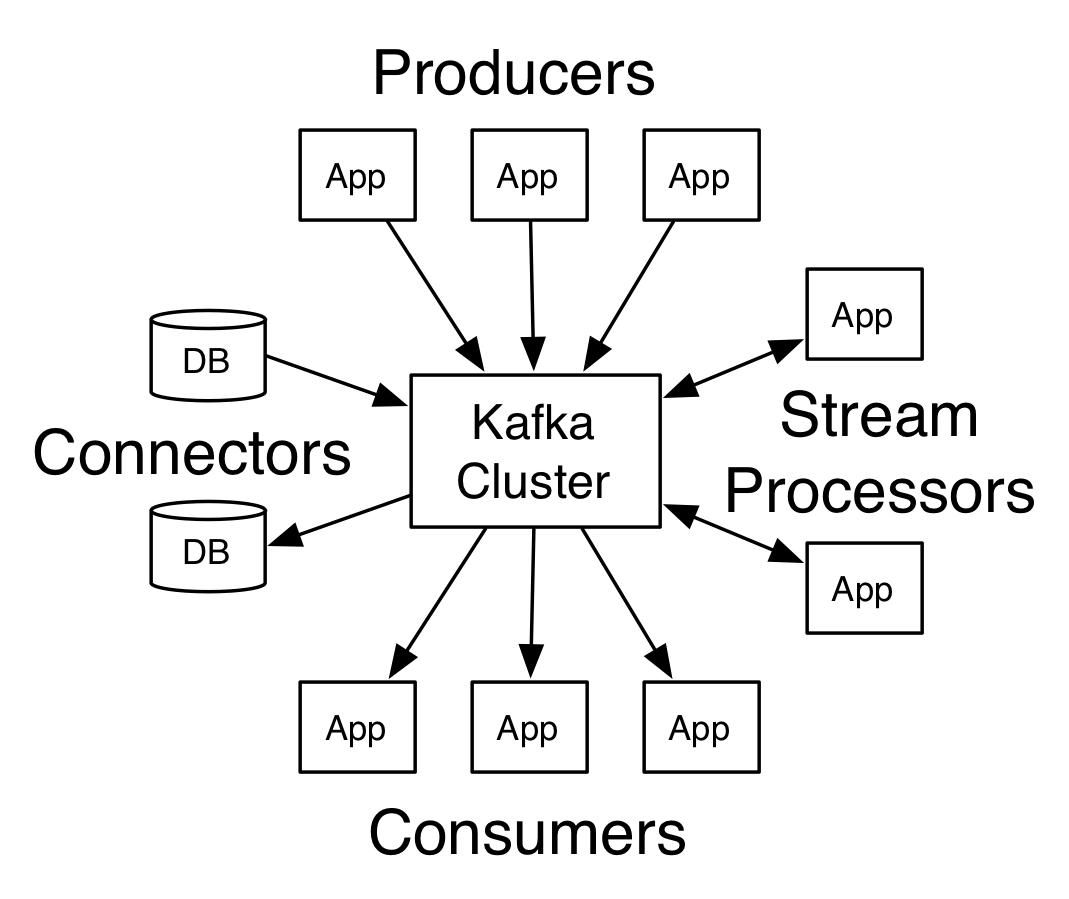
Kafka 是一个分布式的流平台.
2. 应用
构建实时流数据管道,在系统和应用程序间可靠地获取数据。
构建实时流应用程序,能够对数据流进行转换或响应。
3. 概念
Kafka 运行在一个或多个服务器上,以 topic 分类,每个 record 包含 key, value 和 timestamp.
4. API
Producer API
Consumer API
Streams API
Connector API:例如,一个关系数据库的连接器可捕获每一个变化
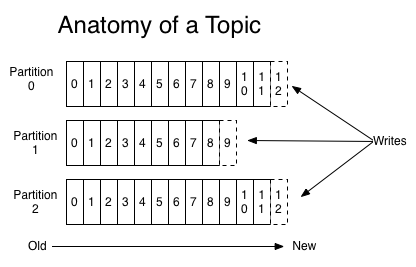
5. Topics and Logs
Topic(主题) :
消息(records)发布到的一个类别名称。
Partition(分区) :
由一段有序且顺序不可改变的消息(records)组成的结构化日志,消息持续追加到分区中。
每个 partition 包含一个leader,和0或多个follower。leader 负责全部读写操作,folloer被动复制leader。
Offset(偏移量) :
唯一标识分区(partition)内每个记录的顺序标识号。
每个consumer的metadata只需要维持 offset 即可。
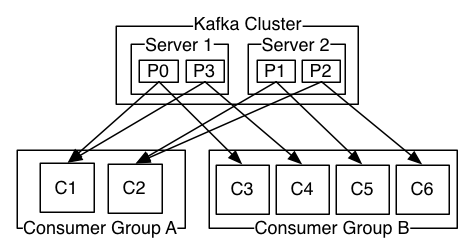
6. Consumers(消费者)
每个 record 会被发送到每个订阅该 topic 的 consumer group,但是 每个 consumer group 中只有一个 consumer 收到消息。
Kafka 只保证同一个 partiton 的 records 的顺序,不保证所有partition的records的顺序
Per-partition ordering combined with the ability to partition data by key is sufficient for most applications.
7. Role
Kafka as a Messaging System 消息系统
Kafka as a Storage System 存储系统
Kafka for Stream Processing 流处理
Kafka provides a fully integrated Streams API. This facility helps solve the hard problems this type of application faces: handling out-of-order data, reprocessing input as code changes, performing stateful computations, etc.
8. 使用场景
Messaging 消息队列
Website Activity Tracking 网站活动追踪
Metrics 指标
Log Aggregation 日志聚合
Sream Processing 流处理
Event Sourcing 事件采集
Commit Log 提交日志
9. 基础操作
, . . . - ,
- - . .
- . - - - - - - - - - - -
- - . - - - - -
- - . - - - - - - - -
- . - - - - - - 10. Kafka Connect 示例
# 创建数据源
$ echo -e "foo\nbar" > test.txt
# 创建 connect (单节点示例)
$ bin/connect-standalone.sh config/connect-standalone.properties config/connect-file-source.properties config/connect-file-sink.properties
# 配置的 sink
$ cat test.sink .txt 11. Kafka Stream 示例
WordCountDemo
KTable wordCounts = textLines
// Split each text line, by whitespace, into words.
.flatMapValues(value -> Arrays.asList(value.toLowerCase().split("\\W+" )))
// Ensure the words are available as record keys for the next aggregate operation.
.map((key, value) -> new KeyValue<>(value, value))
// Count the occurrences of each word (record key) and store the results into a table named "Counts ".
.countByKey ("Counts" ) # 运行类
bin/kafka-run-class.sh org.apache .kafka .streams .examples .wordcount .WordCountDemo
# 查看结果
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 \
--topic streams-wordcount-output \
--from-beginning \
--formatter kafka.tools .DefaultMessageFormatter \
--property print.key =true \
--property print.value =true \
--property key.deserializer =org.apache .kafka .common .serialization .StringDeserializer \
--property value.deserializer =org.apache .kafka .common .serialization .LongDeserializer 12. 使用 API
创建 Maven 工程,添加依赖
<dependency >
<groupId > org.apache.kafka</groupId >
<artifactId > kafka-clients</artifactId >
<version > 0.10.1.0</version >
</dependency >
<dependency >
<groupId > org.apache.kafka</groupId >
<artifactId > kafka-streams</artifactId >
<version > 0.10.1.0</version >
</dependency >
13. Broker Configs 配置
配置文件:config/server.properties 更多配置请见 :Kafka:Broker Config 配置
属性
描述
类型
默认值
broker.id
每一个broker在集群中的唯一表示,要求是正数
int
-1
zookeeper.connect
指定zk连接,[hostname:port]以逗号分隔
string
advertised.listeners
若没配置就就使用listeners的配置通告给消息的生产者和消费者,这个过程是在生产者和消费者获取源数据(metadata)。格式:PLAINTEXT://your.host.name:9092,可选的值有PLAINTEXT和SSL
string
null
auto.create.topics.enable
是否允许自动创建topic,若是false,就需要通过命令创建topic
boolean
true
auto.leader.rebalance.enable
是否自动平衡broker之间的分配策略
boolean
true
delete.topic.enable
是否开启topic可以被删除
boolean
false
listeners
listeners = PLAINTEXT://your.host.name:9092
string
null
log.dirs
kafka持久化数据存储的路径,可以指定多个,以逗号分隔
string
null
message.max.bytes
server能接收的消息体最大大小,单位是字节,消费端的最大拉取大小需要略大于该值
int
1000012
min.insync.replicas
当 ack=”all” 或 -1 时,指定最小确认成功的副本数,如果没满足,producer会抛出 NotEnoughReplicas or NotEnoughReplicasAfterAppend 异常
int
1
num.io.threads
broker处理磁盘IO的线程数,数值应该大于你的硬盘数
int
8
num.network.threads
broker处理消息的最大线程数
int
3
num.replica.fetchers
从source broker进行复制的线程数,增大这个数值会增加follower的IO
int
1
queued.max.requests
等待IO线程处理的请求队列最大数,若是等待IO的请求超过这个数值,那么会停止接受外部消息,应该是一种自我保护机制。
int
500
request.timeout.ms
从发送请求到收到ACK确认等待的最长时间(超时时间)
int
30000
socket.receive.buffer.bytes
socket的接受缓冲区,socket的调优参数SO_RCVBUFF
int
102400
socket.request.max.bytes
socket请求的最大数值,防止serverOOM,message.max.bytes必然要小于socket.request.max.bytes,会被topic创建时的指定参数覆盖
int
104857600
socket.send.buffer.bytes
socket的发送缓冲区,socket的调优参数SO_SNDBUFF
int
102400
zookeeper.connection.timeout.ms
ZooKeeper的连接超时时间
int
null
zookeeper.session.timeout.ms
ZooKeeper的最大超时时间,就是心跳的间隔,若是没有反映,那么认为已经死了,不宜过大
int
6000
connections.max.idle.ms
空闲连接超时,超时则关闭
long
600000
覆盖 Topic 配置方法 :
- -
- . - - - - - - - - - - - - - - . . - - .
- . - - - - - - - - - - - - - - . .
- . - - - - - - - - - - -
- . - - - - - - - - - - - - - - . . Topic-level 配置 :点我
14. Producer Configs 配置
更多配置请见 :Kafka:Producer Config 配置
属性
描述
类型
默认值
bootstrap.servers
用于建立与kafka集群的连接,这个list仅仅影响用于初始化的hosts,发现全部的servers。格式:host1:port1,host2:port2,…,尽量不止一个,以防其中一个down了
list
acks
server完成producer request前需要确认的数量。acks=0时,producer不会等待确认,直接添加到socket等待发送;acks=1时,等待leader写到local log就行;acks=all或acks=-1时,等待isr中所有副本确认
string
1
buffer.memory
producer可以用来缓存数据的内存大小。如果数据产生速度大于向broker发送的速度,producer会阻塞max.block.ms,超时则抛出异常
long
33554432
compression.type
producer用于压缩数据的压缩类型,取值:none, gzip, snappy, or lz4
string
none
batch.size
producer将试图批处理消息记录,以减少请求次数
int
16384
linger.ms
Producer默认会把两次发送时间间隔内收集到的所有Requests进行一次聚合然后再发送,以此提高吞吐量,而linger.ms则更进一步,这个参数为每次发送增加一些delay,以此来聚合更多的Message。原文翻译:producer会将request传输之间到达的所有records聚合到一个批请求。通常这个值发生在欠负载情况下,record到达速度快于发送。但是在某些场景下,client即使在正常负载下也期望减少请求数量。这个设置就是如此,通过人工添加少量时延,而不是立马发送一个record,producer会等待所给的时延,以让其他records发送出去,这样就会被聚合在一起。这个类似于TCP的Nagle算法。该设置给了batch的时延上限:当我们获得一个partition的batch.size大小的records,就会立即发送出去,而不管该设置;但是如果对于这个partition没有累积到足够的record,会linger指定的时间等待更多的records出现。该设置的默认值为0(无时延)。例如,设置linger.ms=5,会减少request发送的数量,但是在无负载下会增加5ms的发送时延。
long
0
max.request.size
请求的最大字节数。这也是对最大记录尺寸的有效覆盖。注意:server具有自己对消息记录尺寸的覆盖,这些尺寸和这个设置不同。此项设置将会限制producer每次批量发送请求的数目,以防发出巨量的请求。
int
1048576
receive.buffer.bytes
TCP的接收缓存 SO_RCVBUF 空间大小,用于读取数据
int
32768
request.timeout.ms
client等待请求响应的最大时间,如果在这个时间内没有收到响应,客户端将重发请求,超过重试次数发送失败
int
30000
send.buffer.bytes
TCP的发送缓存 SO_SNDBUF 空间大小,用于发送数据
int
131072
timeout.ms
指定server等待来自followers的确认的最大时间,根据acks的设置,超时则返回error
int
30000
max.in.flight.requests.per.connection=5
在block前一个connection上允许最大未确认的requests数量
int
5
metadata.fetch.timeout.ms
在第一次将数据发送到某topic时,需先fetch该topic的metadata,得知哪些服务器持有该topic的partition
long
60000
reconnect.backoff.ms
连接失败时,当我们重新连接时的等待时间
long
50
retry.backoff.ms
在重试发送失败的request前的等待时间
long
100
15. New Consumer Configs 配置
0.9.0.0 引入new consumer config 更多配置请见 :Kafka:New Consumer Config 配置
待加入。。。
16. Kafka Connect Configs 配置
更多配置请见 :Kafka:Connect Config 配置
待加入。。。
17. Kafka Streams Configs 配置
更多配置请见 :Kafka:Streams Config 配置
待加入。。。
18. 文件系统
Kafka 依赖于文件系统,磁盘的快慢取决于其使用方式,磁盘的线性写入(linear write)速度远高于随机写入(random write),因此操作系统采取预读(read-ahead)和后写(write-behind)技术对磁盘读写进行探测。预读就是提前将一个比较大的磁盘块中内容读入内存,后写是将一些较小的逻辑写入操作合并起来组成比较大的物理写入操作。 缓存占用可能达到很高 ,且服务重启后仍然有效,而不是进程需要重建或重新开始。kafka利用的也是这点,配合文件的线性读写。
19. 效率 sendfile zero-copy
效率低下的两个常见原因:过多小的IO操作 和 大量的字节拷贝操作 。
为了理解sendfile所带来的效果,重要的是要理解将数据从文件传输到socket的数据路径:
使用sendfile就可以避免这些重复的拷贝操作,让OS直接将数据从页面缓存发送到网络中,其中只需最后一步中的将数据拷贝到NIC的缓冲区。如此一来,消息使用的速度就能接近网络连接的极限。
详细的 sendfile zero-copy 参见:Sendfile & Zero-copy
20. 端到端的批量压缩
多数情况下系统的瓶颈是网络而不是CPU或磁盘。高效压缩需要将多条消息一起进行压缩(可能含有共同的field),而不是分别压缩每条消息。数据在消息生产者发送之前先压缩一下,然后在服务器上一直保存压缩状态,只有到最终的消息使用者那里才需要将其解压缩。
Kafka 支持 GZIP, Snappy 和 LZ4 压缩协议。
21. 生产者 Producer
producer 直接发送数据到持有 partition leader 的 broker,而不通过路由层。 Kafka 每个节点会响应其 metadata 请求,metadata 包括 server 是否存活、partition的 leader 在哪。
客户端可以控制其发布消息到达的 partition。用户可以实现相关接口,自己实现发送机制,通过指定 key 值,进行 hash 到 partition。 异步发送
21. 消费者 Consumer
Consumer 通过发送 fetch request 到持有要消费的 partition 的 broker,其指定 offset,然后获得从该位置开始的数据块,consumer 可以控制消费位置。最高水位标记 high water mark指的偏移量 offset
Push vs. pull
消费者进度
离线装载数据