这次我们来总结一下kafka Consumer客户端从 brokers集群上拉取拉取消息的过程,首先看一下KafkaConsumer所以依赖的组件:

metadata 记录了集群的元数据信息
netClient表示consumer与kafka集群网络通信的组件
client 是对netClient的封装,引用了netClient实例
subscriptions 包含了两部分信息,SubscriptionType和TopicPartitionState,SubscriptionType是一个枚举类,表示订阅topic的方式,包括NONE, AUTO_TOPICS, AUTO_PATTERN, USER_ASSIGNED这4种值,TopicPartitionState类表示topic分区的消费状态,有两个比较重要的字段position和lastStableOffset,position表示上次消费到的位置,也就是下次开始消费的位置,lastStableOffset表示最后一次提交的偏移量offset
coordinator是一个ConsumerCoordinator类,表示与kafka集群协调交互的节点,consumer的Rebalance和提交偏移量的操作都是通过coordinator来完成的
fetcher就是本次要介绍的主角,主要负责从kafka集群拉取消息
首先来看一下consumer负责拉取消息的方法poll的处理代码:
public ConsumerRecords<K, V> poll(long timeout) {
acquireAndEnsureOpen();
try {
if (timeout < 0)
throw new IllegalArgumentException("Timeout must not be negative");
if (this.subscriptions.hasNoSubscriptionOrUserAssignment())
throw new IllegalStateException("Consumer is not subscribed to any topics or assigned any partitions");
// poll for new data until the timeout expires
long start = time.milliseconds();
long remaining = timeout;
do {
Map<TopicPartition, List<ConsumerRecord<K, V>>> records = pollOnce(remaining);
if (!records.isEmpty()) {
// before returning the fetched records, we can send off the next round of fetches
// and avoid block waiting for their responses to enable pipelining while the user
// is handling the fetched records.
//
// NOTE: since the consumed position has already been updated, we must not allow
// wakeups or any other errors to be triggered prior to returning the fetched records.
if (fetcher.sendFetches() > 0 || client.hasPendingRequests())
client.pollNoWakeup();
return this.interceptors.onConsume(new ConsumerRecords<>(records));
}
long elapsed = time.milliseconds() - start;
remaining = timeout - elapsed;
} while (remaining > 0);
return ConsumerRecords.empty();
} finally {
release();
}
}
timeout参数表示拉取消息的最大阻塞时间,这个方法主要是调用pollOnce拉取消息
private Map<TopicPartition, List<ConsumerRecord<K, V>>> pollOnce(long timeout) {
client.maybeTriggerWakeup();
long startMs = time.milliseconds();
//触发协调器事件,保证 coordinator协调器存在并且消费者已经加入cunsumerGroup
coordinator.poll(startMs, timeout);
// 查找消费分区对应的potion信息,确保所有的分区都有对应的position信息,次方法是异步完成的
boolean hasAllFetchPositions = updateFetchPositions();
// 如果已经有拉取数据则立即返回数据
Map<TopicPartition, List<ConsumerRecord<K, V>>> records = fetcher.fetchedRecords();
if (!records.isEmpty())
return records;
// 发送拉取数据请求
fetcher.sendFetches();
long nowMs = time.milliseconds();
long remainingTimeMs = Math.max(0, timeout - (nowMs - startMs));
long pollTimeout = Math.min(coordinator.timeToNextPoll(nowMs), remainingTimeMs);
//如果有分区的positon不存在,则需要通过网络请求获取
if (!hasAllFetchPositions && pollTimeout > retryBackoffMs)
pollTimeout = retryBackoffMs;
client.poll(pollTimeout, nowMs, new PollCondition() {
@Override
public boolean shouldBlock() {
//如果已经有完成的拉取到的数据,则次方法无需阻塞
return !fetcher.hasCompletedFetches();
}
});
//检查是否需要rebalance
if (coordinator.needRejoin())
return Collections.emptyMap();
return fetcher.fetchedRecords();
}
重点关注一下fetcher.sendFetches()这个方法,其处理流程如下:
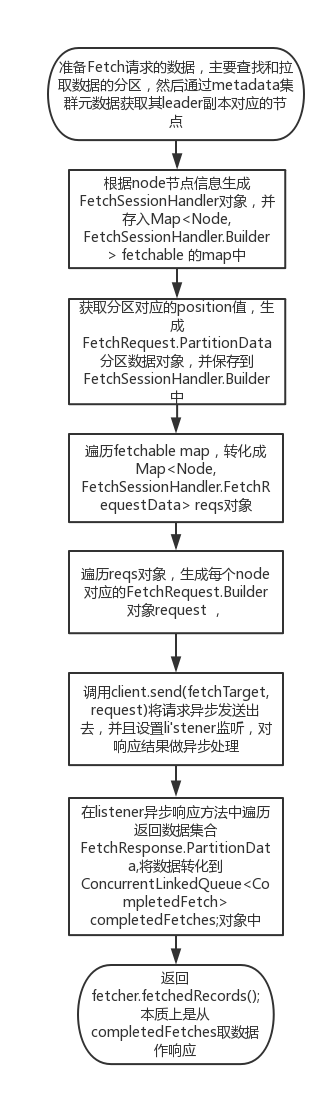
上面流程只是对Fetcher对象拉取数据的一个大致流程做了介绍,里面涉及到很多异步网络通信,异步回调等方法
下一节我们将对consumer做一个整体的总结并讨论如何实现多线程消费