Kafka介绍
关于kafka入门的文章最好的就莫过于kafka的官方文档 了,这上面对kafka的定义是:
Kafka is used for building real-time data pipelines and streaming apps. It is horizontally scalable, fault-tolerant, wicked fast, and runs in production in thousands of companies.
Kafka用于构建实时数据管道和流应用程序。它具有水平可扩展性 ,容错性 ,高性能 ,并在数千家公司的生产中运行。
kafka最早是由美国领英公司(LinkedIn)的工程师们研发的,当时主要解决LinkedIn数据管道的问题
消息系统
1.消息系统是用于不同系统之间传输消息的系统,主要有消息生产者、消息消费者以及消息引擎系统组成
2.使用消息系统的好处有如下几点
解耦
冗余
扩展性
削峰
可恢复性
缓冲
3.消息系统简略架构图
消息系统架构图
Kafka概要设计
主要设计目标如下:
对于任何消息系统而言,吞吐量都是至关重要的性能指标,对于kafka吞吐量就是每秒能够处理的消息数或者字节数,时延代表请求与响应之间的间隔时间,当然时间越短,代表该系统的性能越好
kafka是要持久化消息到磁盘上,这样可以实现消息的灵活处理,并且保证了消息的可靠性,在服务器down机的情况也能保证消息不会丢失,kafka消息持久化的设计也有独到之处,尽量使用内存,然后进行批量刷盘,极大的提高了写盘的效率
作为分布式系统,kafka集群提供了负载均衡以及故障转移的功能,负载均衡机制可以将集群中各个节点的资源充分利用起来,提升集群性能,kafka具备消息备份机制,当某一个节点故障之后,可以由备份节点接管后续的消息处理工作,提高了整体的可用性
kafka支持在线水平扩展,提升集群的吞吐量
Kafka基本架构
kafka集群应用架构如下图所示:
kafka集群常用的场景就是,producer把日志信息推送(push)到broker节点上,然后consumer(可以是写入到hdfs或者其他的一些应用)再从broker拉取(pull)信息。kafka的push&pull机制如下图所示,具体的这样设计的原因我会在后续的文章中进行介绍。
作为一个message system,kafka遵循了传统的方式,选择由kafka的producer向broker push信息,而consumer从broker pull信息。kafka的consumer之所以没有采用push模式,主要是因为push模式很难适应速率不同的consumer,因为消息发送速率是由broker决定的。push模式的目标就是尽可能以最快速度传递消息,但是这样很容易造成consumer来不及处理消息,典型的表现就是拒绝服务以及网络拥塞,而pull模式则可以根据consumer的消费能力以适当的速率消费message。
Kafka基本概念与术语
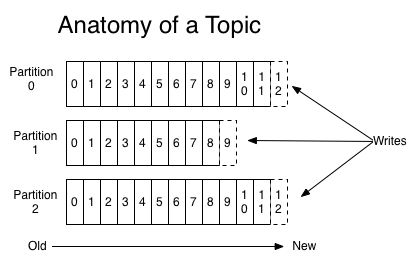
Topic: 指Kafka处理的消息源的不同分类,其实也可以理解为对不同消息源的区分的一个标识;Partition: Topic物理上的分组,一个topic可以设置为多个partition,每个partition都是一个有序的队列;Offset: partition中的每条消息都会被分配一个有序的id(offset);Message: 消息,是通信的基本单位,每个producer可以向一个topic(主题)发送一些消息;Producer: 消息和数据生产者,向Kafka的一个topic发送消息的过程叫做producers(producer可以选择向topic哪一个partition发送数据)。Consumer: 消息和数据消费者,接收topics并处理其发布的消息的过程叫做consumer,同一个topic的数据可以被多个consumer接收;ConsumerGroup: 每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)。Broker: Kafka集群包含一个或多个服务器,这种服务器被称为brokerTopic、Partition、Offset的关系
Topic代表kafka中一种消息的分类,每个Topic具有多个Partition(Partition序号从0开始),而每个Partition具有自己独有的Offset,Offset从0开始,最大值代表该Partition写入消息的条数
Producer、Consumer、 ConsumerGroup、Broker、Message的关系
Producer 将Message发送给它所选择的topic,可以指定Message的Partition或者默认使用Hash路由后发送至broker,Consumer Group拥有一个或者多个Consumer,这些Consumer共同消费一个或者多个Topic的数据,简单来讲,生产者发送消息到broker,消费者从broker消费消息
多个消费者消费一个topic时如下图所示
从上图可以看出,该Topic具有4个Partition,分别在broker1和broker2上面,当消费者个数多于Topic分区数是将不能分配到分区,将造成资源浪费,kafka分配给消费者的数据是以partition平均分配,当不能均分时如总共有10(P0-P9)个分区,该ConsumerGroup有3个consumer消费数据那么将如下分配
C1:P0、P3、P6、P9
C2:P1、P4、P7
C3:P2、P5、P8
有一个消费者将多分配一个分区
Kafka使用场景
消息系统 :kafka擅长解耦生产者和消费者以及实现消息的批处理,同时具备高吞吐量的特性。日志收集 :kafka可以将整个系统的日志全量收集,并集中送往分布式存储系统中(如HDFS),以便进行离线分析,kafka是日志解决方案中最常用的的组件,提供高性能,并且具备完备的可靠性解决方案存储系统 任何允许发布与消费它们分离的消息的消息队列实际上充当了正在进行的消息的存储系统。Kafka的不同之处在于它是一个非常好的存储系统。写入Kafka的数据将写入磁盘并进行复制以实现容错。Kafka允许生产者等待确认,以便在完全复制之前写入不被认为是完整的,并且即使写入的服务器失败也保证写入仍然存在。 流式处理 :大多数人都知道kafka提供消息系统的功能,kafka目前也推出Kafka Streams,目的是实现流的实时处理。在Kafka中,流处理器是指从输入Topic获取连续数据流,并进行实时的分析处理,相比其他流式处理框架Apache Storm、Spark Streaming、Apache Flink成熟度相对较低,但随着社区的发展,我们拭目以待。Kafka安装
kafka下载地址 进行下载最新安装包
下载完成后 可以使用SSH工具连接Linux环境 使用MobaXterm或者Xshell等我这里使用MobaXterm
在/opt下新建目录src mkdir /opt/src 然后进入该目录cd /opt/src/
[root@192 ~]# mkdir /opt/src/
[root@192 ~]# cd /opt/src/
[root@192 src]#
将之前下载的安装包上传到该目录 我这里使用MobaXterm直接将kafka拖进即可
[root@192 src]# ll
total 62500
-rw-r--r--. 1 root root 63999924 Jan 12 07:46 kafka_2.11-2.2.0.tgz
然后进行解压 tar -zxvf kafka_2.11-2.2.0.tgz -C /opt
[root@192 src]# tar -zxvf kafka_2.11-2.2.0.tgz -C /opt
进入kafka解压目录 cd/opt/kafka_2.11-2.2.0
[root@192 src]# cd /opt/kafka_2.11-2.2.0
[root@192 kafka_2.11-2.2.0]# ll
total 52
drwxr-xr-x. 3 root root 4096 Mar 9 2019 bin
drwxr-xr-x. 2 root root 4096 Mar 9 2019 config
drwxr-xr-x. 2 root root 4096 Jan 12 07:56 libs
-rw-r--r--. 1 root root 32216 Mar 9 2019 LICENSE
-rw-r--r--. 1 root root 336 Mar 9 2019 NOTICE
drwxr-xr-x. 2 root root 44 Mar 9 2019 site-docs
在启动kafka之前需要先安装JDK,可以参考这篇文章https://www.cnblogs.com/Dylansuns/p/6974272.html
kafka是依赖zookeeper的,首先要启动zookeeper进程,这里我使用的kafka包中自带的zookeeper,在实际生产环境中一般使用的单独的zookeeper集群,可以参考这篇文章进行zookeeper集群搭建https://www.cnblogs.com/wrong5566/p/6056788.html
前台启动zookeeper (不推荐)
[root@192 kafka_2.11-2.2.0]# sh bin/zookeeper-server-start.sh config/zookeeper.properties
后台启动进程(推荐)
[root@192 kafka_2.11-2.2.0]# sh bin/zookeeper-server-start.sh config/zookeeper.properties > zookeeper.out 2>&1 &
然后修改kafka server配置文件 vim config/server.properties
找到 zookeeper.connect 这里填写zookeeper的主机和端口号,这里因为kafka和zookeeper在同一个ip,zookeeper的默认启动端口为2181,所以不用进行修改
启动kafka server
[root@192 kafka_2.11-2.2.0]# sh bin/kafka-server-start.sh config/server.properties > logs/kafka.log 2>&1 &
查看进程 jps
[root@192 kafka_2.11-2.2.0]# jps
17650 Kafka
17992 Jps
17341 QuorumPeerMain
QuorumPeerMain为zookeeper进程 Kafka进程也启动了 至此kafka最简易安装完成了,接下来使用kafka
Kafka使用 查看kafka中的topic信息
[root@192 kafka_2.11-2.2.0]# sh bin/kafka-topics.sh --list --zookeeper localhost:2181
__consumer_offsets # 该topic保存kafkaconsumer的offset信息 建议不要对该topic进行使用或者删除
test-topic
新建一个topic进行测试 并进行查看
[root@192 kafka_2.11-2.2.0]# sh bin/kafka-topics.sh --create --zookeeper localhost:2181 --topic test-kafka --partitions 2 --replication-factor 1
Created topic test-kafka.
[root@192 kafka_2.11-2.2.0]# sh bin/kafka-topics.sh --list --zookeeper localhost:2181
__consumer_offsets
test-kafka
test-topic
--partitions 指定该topic的partition数量 --replication-factor 指定该topic的副本数量
查看该topic信息
[root@192 kafka_2.11-2.2.0]# sh bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic test-kafka
Topic:test-kafka PartitionCount:2 ReplicationFactor:1 Configs:
Topic: test-kafka Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic: test-kafka Partition: 1 Leader: 0 Replicas: 0 Isr: 0
可以看到该topic 具有两个分区 (PartitionCount:2) 和一个副本 (ReplicationFactor:1)
[root@192 kafka_2.11-2.2.0]# sh bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test-kafka
>hello kafka
按Ctrl+C退出发送console,然后进行消费消息
[root@192 kafka_2.11-2.2.0]# sh bin/kafka-console-consumer.sh -bootstrap-server localhost:9092 --topic test-kafka --from-beginning
hello kafka
这里使用kafka自带脚本完成了简单的消息发送以及消费过程
新建maven工程 pom文件如下
<xml version="1.0" encoding="UTF-8">
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.huawei</groupId>
<artifactId>kafka</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.12</artifactId>
<version>2.2.0</version>
</dependency>
</dependencies>
</project>
consumer测试类
package com.huawei.kafka.consumer;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java .time.Duration;
import java .util.Arrays;
import java.util.Collections;
import java.util.Properties;
/**
* @author: xuqiangnj@163.com
* @date: 2019/4/13 23:03
* @description:
*/
public class TestConsumer {
private static Properties props = new Properties();
static {
props.put("bootstrap.servers", "192.168.142.139:9092");
props.put("group.id", "Test");
props.put("enable.auto.commit", false);
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
}
final KafkaConsumer<String, String> consumer;
private volatile boolean isRunning = true;
public TestConsumer(String topicName) {
consumer = new KafkaConsumer<String, String>(props);
consumer.subscribe(Arrays.asList(topicName));
}
public void printReceiveMsg() {
int emptyMsgTimes = 0;//当5次没有接受到消息后关闭consumer
while (isRunning) {
ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofSeconds(1));
if (!consumerRecords.isEmpty()) {
for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {
System.out.println("TopicName: " + consumerRecord.topic() + " Partition:" +
consumerRecord.partition() + " Offset:" + consumerRecord.offset() + "" +
" Msg:" + consumerRecord.value());
}
}else {
emptyMsgTimes++;
}
if (emptyMsgTimes == 5){
close();
}
}
}
public void close() {
isRunning = false;
if (consumer != null) {
consumer.close(Duration.ofSeconds(1));
}
}
}
producer测试类
package com.huawei.kafka.producer;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
/**
* @author: xuqiangnj@163.com
* @date: 2019/4/13 23:19
* @description:
*/
public class TestProducer {
public static final Properties props = new Properties();
static {
props.put("bootstrap.servers", "192.168.142.139:9092");
props.put("ack", "-1");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
}
final KafkaProducer<String, String> kafkaProducer;
private String topicName;
public TestProducer(String topicName) {
kafkaProducer = new KafkaProducer<>(props);
this.topicName = topicName;
}
public void sendMsg(String msg) {
kafkaProducer.send(new ProducerRecord<String, String>(topicName, msg));
}
public void close() {
if (kafkaProducer != null) {
kafkaProducer.close();
}
}
}
测试类
package com.huawei.kafka.test;
import com.huawei.kafka.consumer.TestConsumer;
import com.huawei.kafka.producer.TestProducer;
/**
* @author: xuqiangnj@163.com
* @date: 2019/4/13 23:26
* @description:
*/
public class TestKafka {
public static void main(String[] args) {
new Thread(() -> new TestConsumer("test-kafka").printReceiveMsg()).start();
new Thread(() -> {
TestProducer testProducer = new TestProducer("test-kafka");
for (int i = 1; i <= 10; i++) {
testProducer.sendMsg("The " + i + " times to say hello kafka!");
}
testProducer.close();
}).start();
}
}
打印结果为
TopicName: test-kafka Partition:0 Offset:5 Msg:The 2 times to say hello kafka!
TopicName: test-kafka Partition:0 Offset:6 Msg:The 4 times to say hello kafka!
TopicName: test-kafka Partition:0 Offset:7 Msg:The 6 times to say hello kafka!
TopicName: test-kafka Partition:0 Offset:8 Msg:The 8 times to say hello kafka!
TopicName: test-kafka Partition:0 Offset:9 Msg:The 10 times to say hello kafka!
TopicName: test-kafka Partition:1 Offset:5 Msg:The 1 times to say hello kafka!
TopicName: test-kafka Partition:1 Offset:6 Msg:The 3 times to say hello kafka!
TopicName: test-kafka Partition:1 Offset:7 Msg:The 5 times to say hello kafka!
TopicName: test-kafka Partition:1 Offset:8 Msg:The 7 times to say hello kafka!
TopicName: test-kafka Partition:1 Offset:9 Msg:The 9 times to say hello kafka!
这就是kafka的最简单的使用
希望这篇文章对初学者能有所帮助(转载请注明出处)。