开发环境:Java 1.8 + Idea2016.2.1 + Scala 2.10.6 +Gradle 4.5.1 + Kafka 0.10.0.0
kafka下载地址:http://kafka.apache.org/downloads.html
gradle下载地址:https://services.gradle.org/distributions/gradle-4.5.1-bin.zip
一、Gradle安装配置
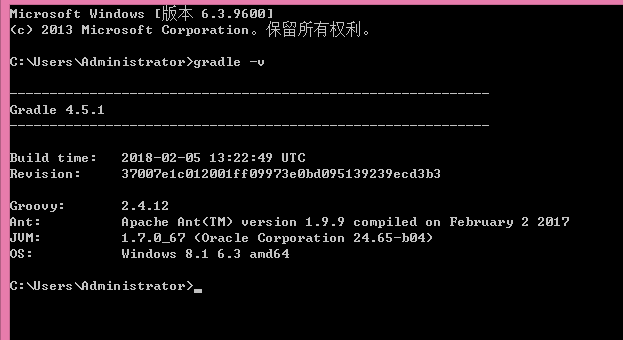
Kafka代码自0.8.x之后就使用Gradle来进行编译和构建了,因此首先需要安装Gradle。Gradle集成并吸收了Maven主要优点的同时还克服了Maven自身的一些局限性――你可以访问https://www.gradle.org/downloads/下载最新的Gradle版本。下载解压到一个目录,然后创建一个环境变量GRADLE_HOME指向解压的目录,再将%GRADLE_HOME%\bin加到PATH环境变量中,Gradle就安装配置好了。打开一个cmd输入gradle -v验证一下:
二、Kafka源代码下载
安装好Gradle之后我们开始下载Kafka的源代码,当前下载的版本是0.10.0.0,你可以从http://kafka.apache.org/downloads.html处下载源代码包。下载之后解压缩到一个目录,目录结构如下图所示:
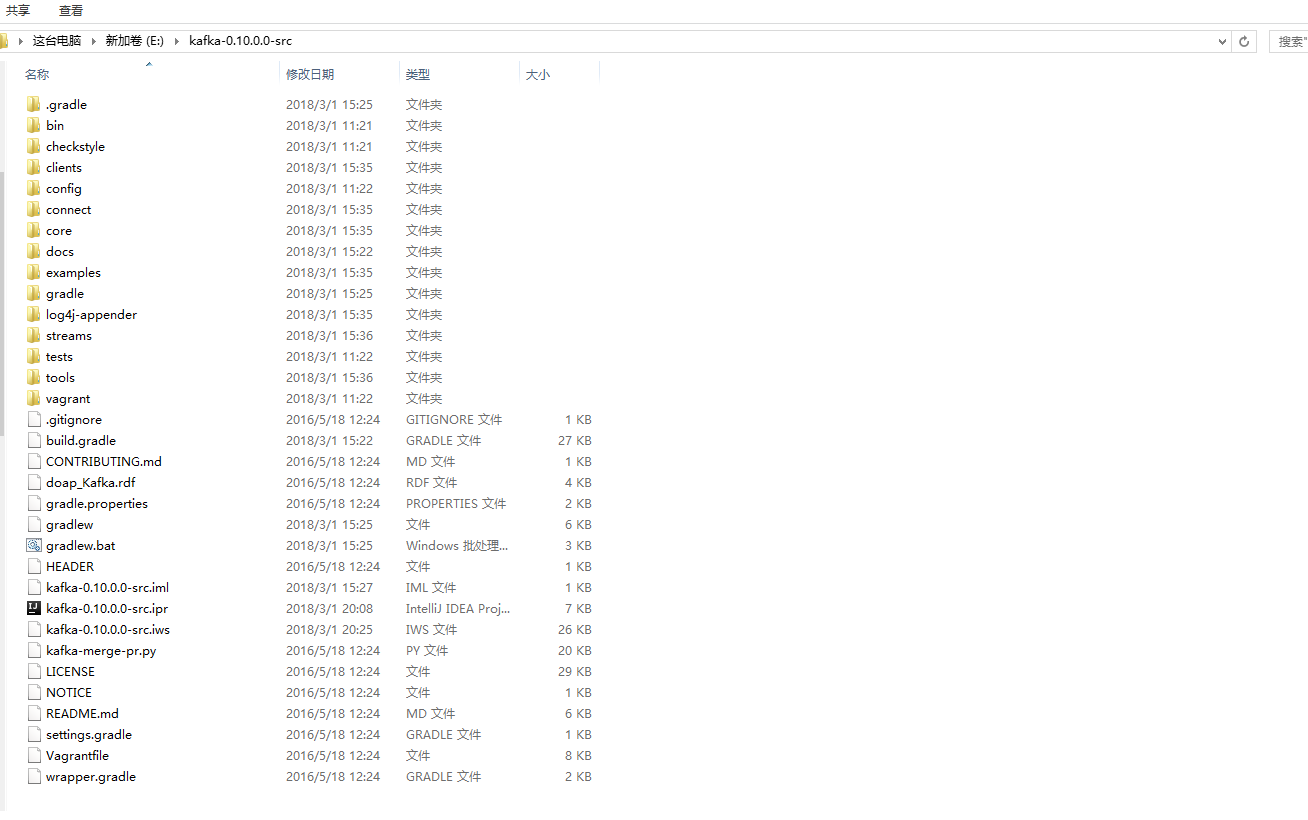
重要目录的作用如下:
bin目录: Windows和Unix平台下的执行脚本,比如kafka-server-start,console-producer,console-consumer等
clients目录: Kafka客户端代码
config目录: Kafka配置文件,其中比较重要的是server.properties,启动Kafkabroker需要直接加载这个文件
contrib目录: Kafka与hadoop集成的代码,包括hadoop-consumer和hadoop-producer
core目录: Kafka的核心代码,也是作者后面重点要学习的部分
examples目录: Kafka样例代码,例如如何使用Java编写简单的producer和consumer
system_test: 系统测试脚本,主要用python编写
其他的目录和配置文件大多和gradle配置有关,就不赘述了。
三、下载gradle wrapper类库
将这个配置单独作为一个步骤是因为官网的教程中并没有详细给出这方面的配置方法。如果直接从官网下载了源代码进而执行gradlew eclipse生成项目工程就会报错:
Error: Could not find or load main classorg.gradle.wrapper.GradleWrapperMain
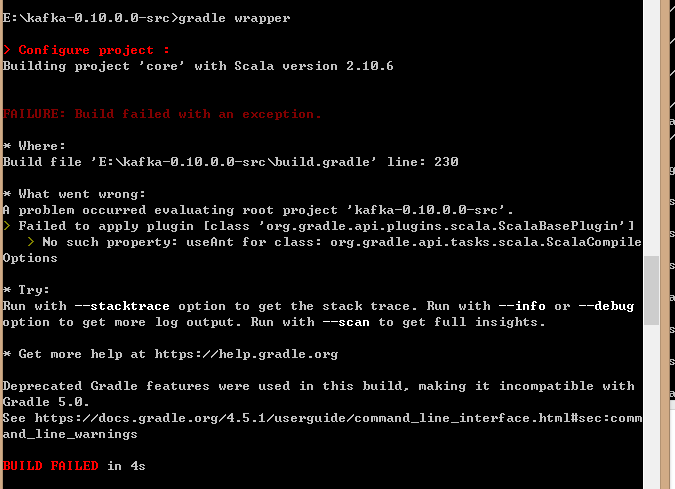
在Kafka源代码的gradle子目录中果然没有wrapper类库,因此我们要先安装一个Gradle Wrapper库,方法也很简单,打开个cmd窗口,在Kafka源代码根目录下执行gradle wrapper即可。你只需运行这个命令一次即可。如果是首次安装需要花一些时间去下载所需的jar包。Kafka的源代码是用Scala语言编写的,下图中清晰地显示我们使用Scala版本是2.10.6。你可以在gradle.properties文件中指定Scala版本
执行报错:
解决方法:vim kafka-0.10.0.0-src/build.gradle文件
添加如下行
ScalaCompileOptions.metaClass.daemonServer = true
ScalaCompileOptions.metaClass.fork = true
ScalaCompileOptions.metaClass.useAnt = false
ScalaCompileOptions.metaClass.useCompileDaemon = false

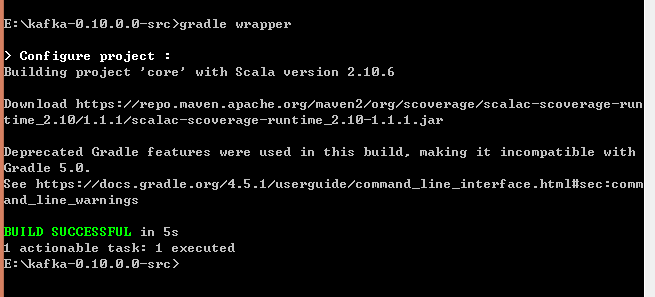
修改后再执行,成功:
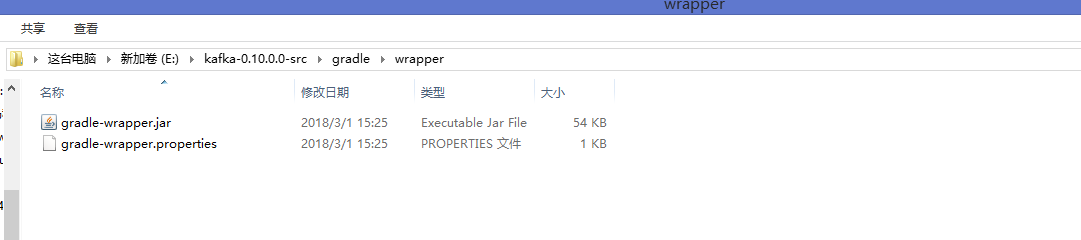
命令运行成功之后,在kafka的gradle子目录中会多出一个wrapper子目录,里面包含了一个jar包和一个配置文件。至此Gradle wrapper已被成功安装在本机:
四、生成IDEA工程文件并导入到IDEA中
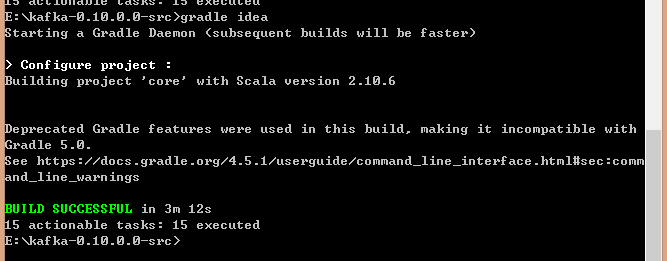
上述准备工作一切就绪后,我们现在可以生成IDEA工程文件。具体做法为打开一个cmd窗口,切换到kafka源代码根路径下,运行gradle idea,如果是第一次运行,可能会花费一些时间去下载必要的jar包,在等待了一段时间之后,终于看到了BUILDSUCCESSFUL的字样表示项目工程文件生成成功:
项目导入到IDEA工程中
File-->Open

IDEA中查看源码工程
五、配置server.properties
kafka broker启动时需要加载server.properties文件。该文件默认位置是在config目录下,因此需要设置运行kafka.Kafka.scala时的Program arguments为../config/server.properties以保证Kafka.scala能够找到该配置文件。
另外,由于kafka broker会将一些元数据信息保存在zookeeper中,因此在启动kafka broker之前必须要先有一个启动着的zookeeper实例或集群,然后我们还需要在server.properties文件更新zookeeper连接信息(主机名:端口CSV列表),如下图所示:
# Zookeeper connection string (seezookeeper docs for details).
# This is a comma separated host:portpairs, each corresponding to a zk
# server. e.g."127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002".
# You can also append an optional chrootstring to the urls to specify the
# root directory for all kafka znodes.
zookeeper.connect=10.11.207.97:2181
# Timeout in ms for connecting to zookeeper
zookeeper.connection.timeout.ms=6000
六、启动kafka broker
Okay!现在可以说一切准备就绪了,可以运行kafka了,如果前面所有步骤都执行正确的话,一个kafka broker进程应该会正确地启动起来,如下图所示:

另外说一下,如果启动时没有看到任何log输出,可以将config目录下的log4j.properties文件拷贝到core\src\main\scala目录下,应该就能解决此问题。
好了,至此你就可以使用这个可运行的环境来研究Kafka源代码了。祝大家好运:)
七、log4j.properties文件路径设置
启动kafka server很奇怪,log4j.properties文件找不到,报如下错误。
log4j:WARN No appenders could be found forlogger (kafka.utils.VerifiableProperties).
log4j:WARN Please initialize the log4j system properly.
只有把log4j.properties放置到src/main/Scala路径下,才能找到文件,然后运行程序,正确输出日志信息。
通过如上7步后就可以正确启动kafka程序,进行相关debug,并研究其源代码了。
本文出自 “数字科技” 博客,请务必保留此出处http://7639538.blog.51cto.com/7629538/1882808