RequestPurgatory
purgatory,炼狱的意思。第一次看RequestPurgatory类的代码时,一头雾水,不明白是干什么的。要理解这个,需要先理解kafka处理FetchRequest和ProduceRequest的思路:
1. 请求到达,先判断该请求执行完成的条件是否满足(例如ProduceRequest,需要判断是否有足够多的Follower都已经同步了指定的offset),如果满足,则直接返回响应,否则请求就由Purgatory来处理了。
2. 对于进入到Purgatory中的请求,根据请求的key(TopicAndPartition)放入不同的Wather中。当相应的TopicAndPartition有可能影响hw或者leo的操作时,Watchers.collectSatisfiedRequests函数被调用,检查Purgatory中的每个请求所需的条件是否已经满足;
3. 除此之外,每个请求都有timeout,Purgatory会定时检查是否有请求超时,如果超时则从Purgatory中移除,并调用expire函数;
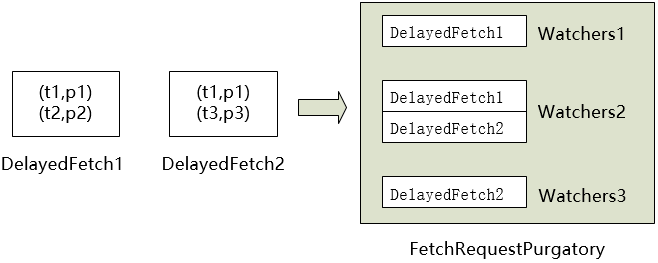
所以,RequestPurgatory可以理解为一个包含以TopicAndPartition为主键的Map,如果相应的TopicAndPartition有动作,则触发检查,同时,还有定时检查,清理超时项。
/**
* Watcher中的检查函数,一个TopicAndPartition对应一个Watcher,每个
* Watcher包含一个requests队列。这个函数就是遍历requests队列,检查是否
* 有request被satisfied
* @return satisfied的请求列表
*/
def collectSatisfiedRequests(): Seq[T] = {
val response = new mutable.ArrayBuffer[T]
synchronized {
val iter = requests.iterator()
while(iter.hasNext) {
val curr = iter.next
if(curr.satisfied.get) {
iter.remove()
} else {
val satisfied = curr synchronized checkSatisfied(curr)
if(satisfied) {
iter.remove()
val updated = curr.satisfied.compareAndSet(false, true)
if(updated == true) {
response += curr
}
}
}
}
}
response
}
RequestPurgatory是个抽象类,FetchRequestPurgatory和 ProducerRequestPurgatory分别采用不同的方式实现了checkSatisfied和expire函数。checkSatisfied返回boolean,用于判断一个请求返回所需的条件是否已经满足;expire则是在请求超时时被调用。
ProducerRequestPurgatory
ProducerRequestPurgatory用于处理生产请求,收到ProducerRequest时,请求就有可能放入到ProducerRequestPurgatory中。将请求放入watcher中之前,会先调用checkSatisfied判断请求返回所需的条件是否已经满足,如果满足了则直接返回;否则加入到watcher中,并在后面不断查询;
ProducerRequestPurgatory.checkSatisfied(delayedProduce)直接调用了delayedProduce.isSatisfied函数,该函数会对ProducerRequest中的每个Partition的状态进行检查,调用partition.checkEnoughReplicasReachOffset,有如下几个步骤:
1. 对于除去leader外的,leo > requiredOffset的replica数进行统计,设为变量numAcks;
2. 如果requiredAcks < 0,当 hw >= requiredOffset时即满足条件;
3. 如果requiredAcks >0,当numAcks>=requiredAcks时满足条件;
如果请求超时,ProducerRequestPurgatory.expire被调用,最终调用DelayedProduce.respond函数。该函数代码如下:
def respond(offsetManager: OffsetManager): RequestOrResponse = {
val responseStatus = partitionStatus.mapValues(status => status.responseStatus)
val errorCode = responseStatus.find { case (_, status) =>
status.error != ErrorMapping.NoError
}.map(_._2.error).getOrElse(ErrorMapping.NoError)
//如果该请求是offsetCommit请求,在message写入没有异常时,将新的offset更新到cache中
if (errorCode == ErrorMapping.NoError) {
offsetCommitRequestOpt.foreach(ocr => offsetManager.putOffsets(ocr.groupId, ocr.requestInfo) )
}
//1.如果是offsetCommitRequest,则转换errorCode,并返回响应;
//2.如果是ProduceRequest,则根据partitionStatus返回Response;
val response = offsetCommitRequestOpt.map(_.responseFor(errorCode, offsetManager.config.maxMetadataSize))
.getOrElse(ProducerResponse(produce.correlationId, responseStatus))
response
}
DelayedProduce的repond函数有点难懂,这里不仅包含了返回ProduceRequest的操作,还包含返回OffsetCommitReuqest的逻辑。在OffsetCommitRequest请求成功执行到每个replica后,需要将offset更新到OffsetCache中。
FetchRequestPurgatory
同样,FetchRequestPurgatory.checkSatisfied由delayedFetch.isSatisfied实现,满足delayFetch有四种情况:
1. 当前broker不再是该partition的leader;
2. 错误的topicAndPartition,当前replica不存在该partition;
3. fetch的offset不在log的最新的segment上;
4. 累计的字节数达到了最低要求――――这个才是满足Fetch的正常方式;
对于FetchRequest中的每一个 parition->fetchOffset, 累计的字节数 accumulatedSize += endOffset.positionDiff(fetchOffset);即每一个partition的leo-fetchOffset是该partition累计的字节数,如果所有partition累计的字节数之和accumulatedSize>fetch.minBytes,则Fetch请求被满足。
当FetchRequest超时DelayedFetch.respond被调用:
def respond(replicaManager: ReplicaManager): FetchResponse = {
//从log中读取messageSet
val topicData = replicaManager.readMessageSets(fetch)
FetchResponse(fetch.correlationId, topicData.mapValues(_.data))
}
即从log中读取FetchRequest指定offset开始的MessageSet,并包装成FetchResponse返回。