了解kafka的基本知识,对kafka进行安装和基础环境配置
Kafka基本介绍
Kafka是非常流行的日志采集系统,可以作为DStream的高级数据源,也可以作为Flume的Sink端接收来自Flume的数据。本实验同时用到这两种功能。
Kafka的使用依赖于zookeeper,安装Kafka前必须先安装zookeeper.
文档格式工整规范,一目了然。
文字描述与截图说明相结合,清清楚楚。
一、Ubuntu 系统安装Kafka
1. cd ~/下载
2. sudo tar -zxf kafka_2.11-0.10.1.0.tgz -C /usr/local
3. cd /usr/local
4. sudo mv kafka_2.11-0.10.1.0/ ./kafka
5. sudo chown -R hadoop ./kafka
此处我选择的是kafa 2.11-2.0.1.tgz,下载后需要解压:
核心概念
1.Broker Kafka集群包含一个或多个服务器,这种服务器被称为broker
测试简单实例
1. # 进入kafka所在的目录
2. cd /usr/local/kafka
3. bin/zookeeper-server-start.sh config/zookeeper.properties
1. cd /usr/local/kafka
2. bin/kafka-server-start.sh config/server.properties
3.
Shell 命令
1. cd /usr/local/kafka
2. bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic dblab
Shell 命令
1. bin/kafka-topics.sh --list --zookeeper localhost:2181
Shell 命令
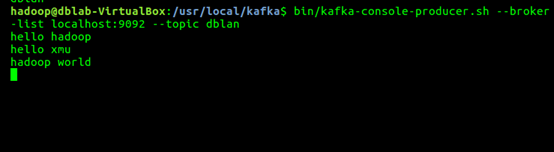
1. bin/kafka-console-producer.sh --broker-list localhost:9092 --topic dblab
Shell 命令
hello hadoop
hello xmu
hadoop world
然后再次开启新的终端或者直接按CTRL+C退出。然后使用consumer来接收数据,输入如下命令:
1. cd /usr/local/kafka
2. bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic dblab --from-beginning
Shell 命令
二、Flume的安装和准备
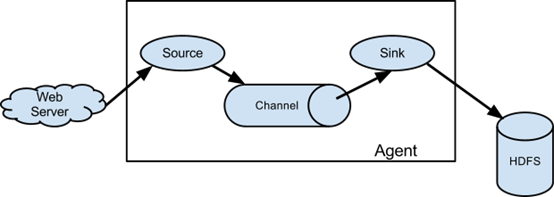
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
Event:一个数据单元,带有一个可选的消息头
flume下载地址: flume下载官网
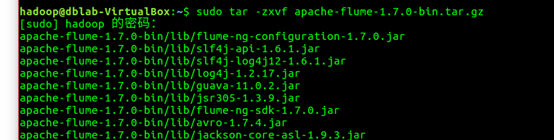
1. sudo tar -zxvf apache-flume-1.7.0-bin.tar.gz -C /usr/local # 将apache-flume-1.7.0-bin.tar.gz解压到/usr/local目录下,这里一定要加上-C否则会出现归档找不到的错误
2. sudo mv ./apache-flume-1.7.0-bin ./flume #将解压的文件修改名字为flume,简化操作
3. sudo chown -R hadoop:hadoop ./flume #把/usr/local/flume目录的权限赋予当前登录Linux系统的用户,这里假设是hadoop用户
Shell
1. sudo vim ~/.bashrc
Shell
1. export JAVA_HOME=/usr/lib/jvm/java -8-openjdk-amd64;
2. export FLUME_HOME=/usr/local/flume
3. export FLUME_CONF_DIR=$FLUME_HOME/conf
4. export PATH=$PATH:$FLUME_HOME/bin
Shelljava ”,则使用原来的设置即可。
1. source ~/.bashrc
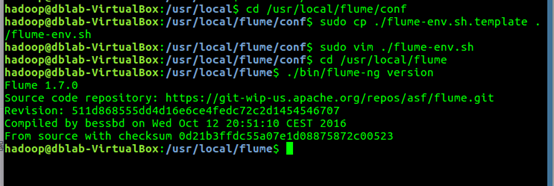
flume-env.sh 配置文件:
1. cd /usr/local/flume/conf
2. sudo cp ./flume-env.sh.template ./flume-env.sh
3. sudo vim ./flume-env.sh
Shell
3.查看flume版本信息
1. cd /usr/local/flume
2. ./bin/flume-ng version #查看flume版本信息;
Shell
1. cd /usr/local/hbase/conf
2. sudo vim hbase-env.sh
1. #1、将hbase的hbase.env.sh的这一行配置注释掉,即在export前加一个#
2. #export HBASE_CLASSPATH=/home/hadoop/hbase/conf
3. #2、或者将HBASE_CLASSPATH改为JAVA_CLASSPATH,配置如下
4. export JAVA_CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
5. #笔者用的是第一种方法
三、Spark准备工作
要通过Kafka连接Spark来进行Spark Streaming操作,Kafka和Flume等高级输入源,需要依赖独立的库(jar文件)。也就是说Spark需要jar包让Kafka和Spark streaming相连。按照我们前面安装好的Spark版本,这些jar包都不在里面,为了证明这一点,我们现在可以测试一下。请打开一个新的终端,输入以下命令启动spark-shell:
1. cd /usr/local/spark
2. ./bin/spark-shell
Shell 命令
1. import org.apache.spark.streaming.kafka._
Shell 命令
<console>:23: error: object kafka is not a member of package org.apache.spark.streaming
import org.apache.spark.streaming.kafka._
^
根据Spark官网的说明,对于Spark2.1.0版本,如果要使用Kafka,则需要下载spark-streaming-kafka-0-8_2.11相关jar包。
cd /usr/local/spark/jars
mkdir kafka
cd ~
cd 下载
cp ./spark-streaming-kafka-0-8_2.11-2.1.0.jar /usr/local/spark/jars/kafka
这样,我们就把spark-streaming-kafka-0-8_2.11-2.1.1.jar文件拷贝到了“/usr/local/spark/jars/kafka”目录下。
1. cd /usr/local/kafka/libs
2. ls
3. cp ./* /usr/local/spark/jars/kafka
Shell 命令
四、实验过程
1. cd /usr/local/flume
2. cd conf
3. vim flume_to_kafka.conf
Shell 命令
a1.sources=r1
a1.channels=c1
a1.sinks=k1
#Describe/configure the source
a1.sources.r1.type=netcat
a1.sources.r1.bind=localhost
a1.sources.r1.port=33333
#Describe the sink
a1.sinks.k1.type=org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic=test
a1.sinks.k1.kafka.bootstrap.servers=localhost:9092
a1.sinks.k1.kafka.producer.acks=1
a1.sinks.k1.flumeBatchSize=20
#Use a channel which buffers events in memory
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000000
a1.channels.c1.transactionCapacity=1000000
#Bind the source and sink to the channel
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
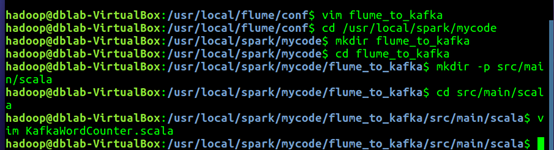
1. cd /usr/local/spark/mycode
2. mkdir flume_to_kafka
3. cd flume_to_kafka
4. mkdir -p src/main/scala
5. cd src/main/scala
Shell 命令
1. vim KafkaWordCounter.scala
package org.apache.spark.examples.streaming
import org.apache.spark._
import org.apache.spark.SparkConf
import org.apache.spark.streaming._
import org.apache.spark.streaming.kafka._
import org.apache.spark.streaming.StreamingContext._
import org.apache.spark.streaming.kafka.KafkaUtils
object KafkaWordCounter{
def main(args:Array[String]){
StreamingExamples.setStreamingLogLevels()
val sc=new SparkConf().setAppName("KafkaWordCounter").setMaster("local[2]")
val ssc=new StreamingContext(sc,Seconds(10))
ssc.checkpoint("file:///usr/local/spark/mycode/flume_to_kafka/checkpoint") //设置检查点
val zkQuorum="localhost:2181" //Zookeeper服务器地址
val group="1" //topic所在的group,可以设置为自己想要的名称,比如不用1,而是val group = "test-consumer-group"
val topics="test" //topics的名称
val numThreads=1 //每个topic的分区数
val topicMap=topics.split(",").map((_,numThreads.toInt)).toMap
val lineMap=KafkaUtils.createStream(ssc,zkQuorum,group,topicMap)
val lines=lineMap.map(_._2)
val words=lines.flatMap(_.split(" "))
val pair=words.map(x => (x,1))
val wordCounts=pair.reduceByKeyAndWindow(_ + _,_ - _,Minutes(2),Seconds(10),2)
wordCounts.print
ssc.start
ssc.awaitTermination
}
}
reduceByKeyAndWindow函数作用解释如下:
1. vim StreamingExamples.scala
Shell 命令
package org.apache.spark.examples.streaming
import org.apache.spark.internal.Logging
import org.apache.log4j.{Level, Logger}
//Utility functions for Spark Streaming examples.
object StreamingExamples extends Logging {
//Set reasonable logging levels for streaming if the user has not configured log4j.
def setStreamingLogLevels() {
val log4jInitialized = Logger.getRootLogger.getAllAppenders.hasMoreElements
if (!log4jInitialized) {
// We first log something to initialize Spark's default logging, then we override the
// logging level.
logInfo("Setting log level to [WARN] for streaming example." +" To override add a custom log4j.properties to the classpath.")
Logger.getRootLogger.setLevel(Level.WARN)
}
}
}
4.打包文件simple.sbt
1. cd /usr/local/spark/mycode/flume_to_kafka
Shell 命令
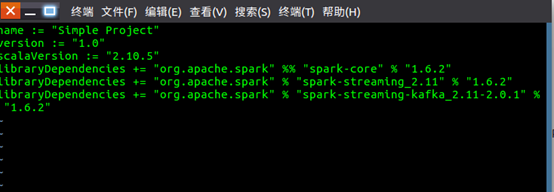
1. vim simple.sbt
2. 内容如下:
3. name := "Simple Project"
4. version := "1.0"
5. scalaVersion := "2.11.8"
6. libraryDependencies += "org.apache.spark" %% "spark-core" % "2.1.0"
7. libraryDependencies += "org.apache.spark" % "spark-streaming_2.11" % "2.1.0"
8. libraryDependencies += "org.apache.spark" % "spark-streaming-kafka-0-8_2.11" % "2.1.0"
9. 要注意版本号一定要设置正确。
在/usr/local/spark/mycode/flume_to_kafka目录下输入命令:
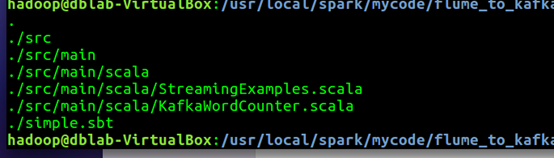
1. cd /usr/local/spark/mycode/flume_to_kafka
2. find .
Shell 命令
.
./simple.sbt
./src
./src/main
./src/main/scala
./src/main/scala/KafkaWordCounter.scala
./src/main/scala/StreamingExamples.scala
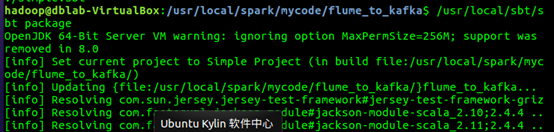
1. cd /usr/local/spark/mycode/flume_to_kafka
2. /usr/local/sbt/sbt package
hadoop@dblab-VirtualBox:/usr/local/spark/mycode/flume_to_kafka$ /usr/local/sbt/sbt package
OpenJDK 64-Bit Server VM warning: ignoring option MaxPermSize=256M; support was removed in 8.0
[info] Set current project to Simple Project (in build file:/usr/local/spark/mycode/flume_to_kafka/)
[info] Compiling 2 Scala sources to /usr/local/spark/mycode/flume_to_kafka/target/scala-2.11/classes...
[info] Packaging /usr/local/spark/mycode/flume_to_kafka/target/scala-2.11/simple-project_2.11-1.0.jar ...
[info] Done packaging.
[success] Total time: 7 s, completed 2018-9-5 10:03:08
6.启动zookeeper和kafka
1. cd /usr/local/kafka
2. ./bin/zookeeper-server-start.sh config/zookeeper.properties
Shell 命令
1. cd /usr/local/kafka
2. bin/kafka-server-start.sh config/server.properties
Shell 命令
7.运行程序KafkaWordCounter
1. cd /usr/local/spark
2. /usr/local/spark/bin/spark-submit --driver-class-path /usr/local/spark/jars/*:/usr/local/spark/jars/kafka/* --class "org.apache.spark.examples.streaming.KafkaWordCounter" /usr/local/spark/mycode/flume_to_kafka/target/scala-2.11/simple-project_2.11-1.0.jar
按Ctrl+z可以退出程序运行
1. cd /usr/local/flume
2. bin/flume-ng agent --conf ./conf --conf-file ./conf/flume_to_kafka.conf --name a1 -Dflume.root.logger=INFO,console
9.打开第五个终端,发送消息
1. telnet localhost 33333
Shell 命令
hello dblab
hello xmu
hello spark
大数据
(hello,3)
(hello,3)
(hello,4)
可以看到”hello”被正确的统计了,数量加一,然而“spark”却和换行符结合变成不能识别的格式“,1)ark”。
运用了Kafka辅助flume这样的海量日志收集工具进行了基础的数据源运行。
kafka对外使用topic的概念,生产者往topic里写消息,消费者从读消息。为了做到水平扩展,一个topic实际是由多个partition组成的,遇到瓶颈时,可以通过增加partition的数量来进行横向扩容。单个parition内是保证消息有序。每新写一条消息,kafka就是在对应的文件append写,所以性能非常高。


](https://img-blog.csdnimg.cn/20190510144058730.pngx-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0pJQVlJTllB,size_16,color_FFFFFF,t_70)