kafka�Ļ���ԭ��
Kafka�ļܹ����ֲ�ʽ��Ϣϵͳ��Ĭ�Ͻ���Ϣ������̣��洢ʱ����7�졣
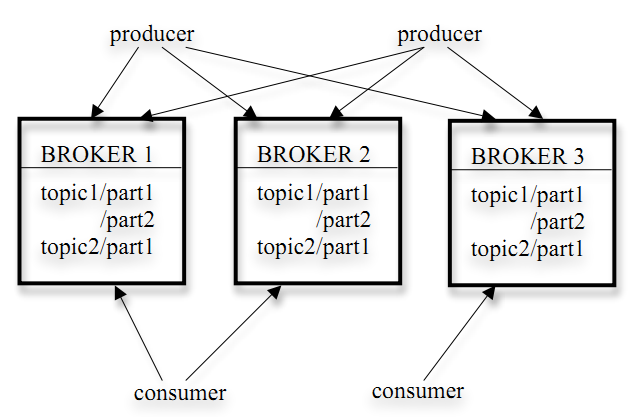
Producer����Ϣ�������ߣ��Լ�������Ϣд���ĸ�partition�����֣�1.hash��2.��ѯ
Broker���齨kafka��Ⱥ�Ľڵ㣬broker֮��û�����ӹ�ϵ��broker��zookeeper��Э����broker������Ϣ�Ķ�д���洢��ÿ��broker���Թ������partition��
Topic��һ����Ϣ���ܳ�/��Ϣ����/����,��partition��ɣ��ж��٣���������ָ��
Partition��ʵ�ʴ洢���ݵĵط���ÿ��partition�и������ж��٣�����topicʱ����ָ����partition��ֱ�ӽӴ����̣�append����Ϣ��ÿ��partition����һ��broker�����������broker�������partition��leader
Consumer����Ϣ�������ߡ�ÿ��consumer�����Լ����������顣������֮������ͬһ��topicʱ������Ӱ�졣ͬһ�����������ڵ�������ͬһ��topicʱ�����topic��ͬһ������ֻ�ܱ�����һ�Ρ�Consumer�Լ�ͨ��zookeeper��ά�������ߵ�offset
Zookeeper��Э�����ݣ��洢Ԫ���ݣ�broker��partition��

---------------------------------------------------------------------------------------------------------------------------------------------------------------------
flume�Ļ���ԭ��
һ.Flume�ܹ�����

���Ľ�Χ��Flume�ļܹ���Flume��Ӧ��(��־�ɼ�)������ϸ�Ľ��ܣ�
flume�Ƿֲ�ʽ����־�ռ�ϵͳ�����������������е������ռ��������͵�ָ���ĵط�ȥ������˵�͵�ͼ�е�HDFS������˵flume�����ռ���־�ġ�
��.Event��������ͼ

flume�ĺ����ǰ����ݴ�����Դ(source)�ռ��������ڽ��ռ����������͵�ָ����Ŀ�ĵ�(sink)��Ϊ�˱�֤���͵Ĺ���һ���ɹ������͵�Ŀ�ĵ�(sink)֮ǰ�����Ȼ�������(channel),��������������Ŀ�ĵ�(sink)��flume��ɾ���Լ���������ݡ�
���������ݵĴ���Ĺ����У���������event��������֤����event������еġ���ôʲô��event�أ����Cevent����������ݽ��з�װ����flume�������ݵĻ�����λ��������ı��ļ���ͨ����һ�м�¼��eventҲ������Ļ�����λ��event��source������channel���ٵ�sink������Ϊһ���ֽ����飬����Я��headers(ͷ��Ϣ)��Ϣ��event������һ�����ݵ���С������Ԫ�����ⲿ����Դ�������ⲿ��Ŀ�ĵ�ȥ��
һ��������event������event headers��event body��event��Ϣ(���ı��ļ��еĵ��м�¼��
flume�ܹ�����
flume֮������ô���棬��Դ����������һ����ƣ������ƾ���agent��agent������һ��java���̣���������־�ռ��ڵ㡪��ν��־�ռ��ڵ���Ƿ������ڵ㡣
agent�������3�����ĵ������source��->channel���C>sink,���������ߡ��ֿ⡢�����ߵļܹ���
source��source�����ר�������ռ����ݵģ����Դ����������͡����ָ�ʽ����־����,����avro��thrift��exec��jms��spooling directory��netcat��sequence generator��syslog��http��legacy���Զ��塣
channel��source����������ռ����Ժ���ʱ�����channel�У���channel�����agent����ר�����������ʱ���ݵġ����Բɼ��������ݽ��мĻ��棬���Դ����memory��jdbc��file�ȵȡ�
sink��sink��������ڰ����ݷ��͵�Ŀ�ĵص������Ŀ�ĵذ���hdfs��logger��avro��thrift��ipc��file��null��hbase��solr���Զ��塣
flume�������
flume�ĺ��ľ���һ��agent�����agent�������������н����ĵط���һ���ǽ������ݵ����롪��source��һ�������ݵ����sink��sink�������ݷ��͵��ⲿָ����Ŀ�ĵء�source���յ�����֮�����ݷ���channel��chanel��Ϊһ�����ݻ���������ʱ�����Щ���ݣ����sink�Ὣchannel�е����ݷ��͵�ָ���ĵط���-����HDFS�ȣ�ע�⣺ֻ����sink��channel�е����ݳɹ����ͳ�ȥ֮��channel�ŻὫ��ʱ���ݽ���ɾ�������ֻ��Ʊ�֤�����ݴ���Ŀɿ����밲ȫ�ԡ�
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
���
kafka�Ƿֲ�ʽ����-������Ϣϵͳ���������LinkedIn��˾������֮���ΪApache��Ŀ��һ���֡�Kafka��һ�ֿ��١�����չ�ġ�������ھ��Ƿֲ�ʽ�ģ������ĺͿɸ��Ƶ��ύ��־����
Kafka�ܹ�
���ļܹ��������������
���⣨Topic�������ض����͵���Ϣ������Ϣ���ֽڵ���Ч���أ�Payload������������Ϣ�ķ����������ӣ�Feed������
�����ߣ�Producer�������ܹ�������Ϣ��������κζ���
���������Broker�����ѷ�������Ϣ������һ��������У����DZ���Ϊ������Broker����Kafka��Ⱥ��
�����ߣ�Consumer�������Զ���һ���������⣬����Broker�����ݣ��Ӷ�������Щ�ѷ�������Ϣ��
Kafka�洢����
1��kafka��topic��������Ϣ������ÿ��topic�������partition��ÿ��partition��Ӧһ����log���ж��segment��ɡ�
2��ÿ��segment�д洢������Ϣ������ͼ������Ϣid������λ�þ�����������Ϣid��ֱ�Ӷ�λ����Ϣ�Ĵ洢λ�ã�����id��λ�õĶ���ӳ�䡣
3��ÿ��part���ڴ��ж�Ӧһ��index����¼ÿ��segment�еĵ�һ����Ϣƫ�ơ�
4�������߷���ij��topic����Ϣ�ᱻ���ȵķֲ������partition�ϣ�������û�ָ����·�ɹ�����зֲ�����broker�յ�������Ϣ����Ӧpartition�����һ��segment�����Ӹ���Ϣ����ij��segment�ϵ���Ϣ�����ﵽ����ֵ����Ϣ����ʱ�䳬����ֵʱ��segment�ϵ���Ϣ�ᱻflush�����̣�ֻ��flush�������ϵ���Ϣ�����߲��ܶ��ĵ���segment�ﵽһ���Ĵ�С����������segmentд���ݣ�broker�ᴴ���µ�segment��
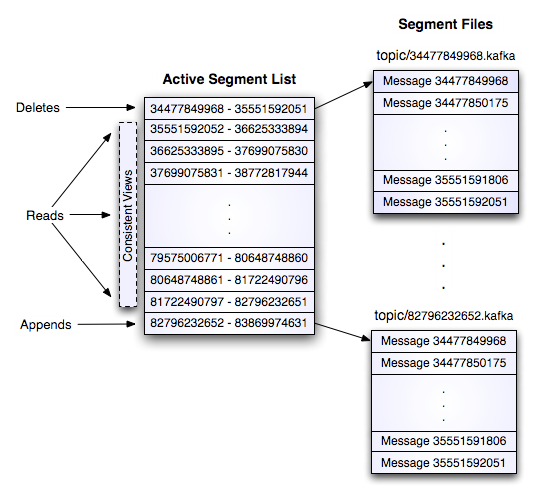
Kafka���ݱ�������
1��N��ǰ��ɾ����
2����������Ķ���Size���ݡ�
Kafka broker
��������Ϣϵͳ��ͬ��Kafka broker����״̬�ġ�����ζ�������߱���ά�������ѵ�״̬��Ϣ����Щ��Ϣ���������Լ�ά����broker��ȫ���ܣ���offset managerbroker��������
- �Ӵ���ɾ����Ϣ��úܼ��֣���Ϊ��������֪���������Ƿ��Ѿ�ʹ���˸���Ϣ��Kafka�����Եؽ����������⣬����һ���Ļ���ʱ���SLAӦ���ڱ������ԡ�����Ϣ�ڴ����г���һ��ʱ����ᱻ�Զ�ɾ����
- ���ִ�������кܴ�ĺô��������߿��Թ���ص��ϵ�ƫ�����ٴ��������ݡ���Υ���˶��еij���Լ��������֤�������������ߵĻ���������
����ժ����kafka�ٷ��ĵ���
Kafka Design
Ŀ��
1) ����������֧�ָ��������¼�������
2) ֧�ִ�����ϵͳ��������
3) ���ӳٵ���Ϣϵͳ
�־û�
1) �����ļ�ϵͳ���־û�������
2) ���ݳ־û���log
��
1) �����small IO problem����
ʹ�á�message set�������Ϣ��
serverʹ�á�chunks of messages��д��log��
consumerһ�λ�ȡ�����Ϣ�顣
2�������byte copying����
��producer��broker��consumer֮��ʹ��ͳһ��binary message format��
ʹ��ϵͳ��page cache��
ʹ��sendfile����log�����⿽����
�˵��˵�����ѹ��
Kafka֧��GZIP��Snappyѹ��Э�顣
���ƣ�Replication��
1��һ��partition�ĸ��Ƹ�����replication factor���������partition��leader������
2�����ж�partition�Ķ���д��ͨ��leader��
3��Followersͨ��pull��ȡleader��log��message��offset��
4�����һ��follower�ҵ�����ס����ͬ��̫����leader������follower�ӡ�in sync replicas����ISR���б���ɾ����
5�������еġ�in sync replicas����follower��һ����Ϣд�뵽�Լ���log��ʱ�������Ϣ�ű���Ϊ�ǡ�committed���ġ�
6��������ij��partition�����и��ƽڵ㶼���ˣ�KafkaĬ��ѡ�����ȸ�����Ǹ��ڵ���Ϊleader������ڵ㲻һ����ISR���
Leaderѡ��
Kafka��Zookeeper��Ϊÿһ��partition��̬��ά����һ��ISR�����ISR�������replica��������leader��ֻ��ISR��ij�Ա�����б�ѡΪleader�Ŀ��ܣ�unclean.leader.election.enable=false����
������ģʽ�£�����f+1��������һ��Kafka topic���ڱ�֤����ʧ�Ѿ�commit��Ϣ��ǰ��������f��������ʧ�ܣ��ڴ����ʹ�ó����£�����ģʽ��ʮ�������ġ���ʵ�ϣ�Ϊ������f��������ʧ�ܣ����������Ӷ������ķ�ʽ��ISR��commitǰ��Ҫ�ȴ��ĸ�����������һ���ģ�����ISR��Ҫ���ܵĸ����ĸ��������ǡ��������Ӷ������ķ�ʽ��һ�롣
The Producer
����ȷ��
ͨ��request.required.acks�����ã�ѡ���Ƿ�ȴ���Ϣcommit���Ƿ�ȴ����еġ�in sync replicas�����ɹ����������ݣ�
Producer����ͨ��acks����ָ��������Ҫ���ٸ�Replicaȷ���յ�����Ϣ����Ϊ����Ϣ���ͳɹ���acks��Ĭ��ֵ��1����Leader�յ�����Ϣ����������Producer�յ�����Ϣ����ʱ�����ISR�е���Ϣ���������ϢǰLeader崻����Ǹ�����Ϣ�ᶪʧ��
�Ƽ��������ǣ���acks����Ϊall����-1����ʱֻ��ISR�е�����Replica���յ������ݣ�Ҳ������Ϣ��Commit����Leader�Ż����Producer����Ϣ���ͳɹ����Ӷ���֤������δ֪�����ݶ�ʧ��
���ؾ���
1��producer�����Զ��巢�͵��ĸ�partition��·�ɹ���Ĭ��·�ɹ���hash(key)%numPartitions�����keyΪnull�����ѡ��һ��partition��
2���Զ���·�ɣ����key��һ��user id������ͬһ��user����Ϣ���͵�ͬһ��partition����ʱconsumer�Ϳ��Դ�ͬһ��partition��ȡͬһ��user����Ϣ��
�첽��������
�������ͣ����ò����ڹ̶���Ϣ��Ŀһ���Ͳ��ҵȴ�ʱ��С��һ���̶��ӳٵ����ݡ�
The Consumer
consumer������Ϣ�Ķ�ȡ��
Push vs Pull
1) producer push data to broker��consumer pull data from broker
2) consumer pull���ŵ㣺consumer�Լ�������Ϣ�Ķ�ȡ�ٶȺ�������
3) consumer pull��ȱ�㣺���brokerû�����ݣ������Ҫpull���æ�ȴ���Kafka��������consumer long pullһֱ�ȵ������ݡ�
Consumer Position
1) ����Ϣϵͳ��broker��¼��Щ��Ϣ�������ˣ���Kafka���ǡ�
2) Kafka��consumer������Ϣ�����ѣ�consumer�������Իص�һ��old offset��λ���ٴ�������Ϣ��
Consumer group
ÿһ��consumerʵ��������һ��consumer group��
ÿһ����Ϣֻ�ᱻͬһ��consumer group���һ��consumerʵ�����ѡ�
��ͬconsumer group����ͬʱ����ͬһ����Ϣ��
Consumer Rebalance
Kafka consumer high level API��
���ijconsumer group��consumer��������partition��������������һ��consumer�����Ѷ��partition�����ݡ�
���consumer��������partition������ͬ��������һ��consumer����һ��partition�����ݡ�
���consumer����������partition������ʱ�����в���consumer�����Ѹ�topic���κ�һ����Ϣ��
Message Delivery Semantics
���֣�
At most once��Messages may be lost but are never redelivered.
At least once��Messages are never lost but may be redelivered.
Exactly once��this is what people actually want, each message is delivered once and only once.
Producer���и���acks�����ÿ��Կ��ƽ��յ�leader����ʲô����¾ͻ�Ӧproducer��Ϣд��ɹ���
Consumer��
* ��ȡ��Ϣ��дlog��������Ϣ�����������Ϣʧ�ܣ�log�Ѿ�д�룬�����ٴδ���ʧ�ܵ���Ϣ����Ӧ��At most once����
* ��ȡ��Ϣ��������Ϣ��дlog�������Ϣ�����ɹ���дlogʧ�ܣ�����Ϣ�ᱻ�������Σ���Ӧ��At least once����
* ��ȡ��Ϣ��ͬʱ������Ϣ����result��logͬʱд�롣������֤result��logͬʱ���»�ͬʱʧ�ܣ���Ӧ��Exactly once����
KafkaĬ�ϱ�֤at-least-once delivery�������û�ʵ��at-most-once���壬exactly-once��ʵ��ȡ����Ŀ�Ĵ洢ϵͳ��kafka�ṩ�˶�ȡoffset��ʵ��Ҳû�����⡣
Distribution
Consumer Offset Tracking
1��High-level consumer��¼ÿ��partition�����ѵ�maximum offset��������commit��offset manager��broker����
2��Simple consumer��Ҫ�ֶ�����offset�����ڵ�Simple consumer Java APIֻ֧��commit offset��zookeeper��
Consumers and Consumer Groups
1��consumerע�ᵽzookeeper
2������ͬһ��group��consumer��group idһ����ƽ������partition��ÿ��partitionֻ�ᱻһ��consumer���ѡ�
3����broker��ͬһ��group������consumer��״̬�����仯��ʱ��consumer rebalance�ͻᷢ����
Zookeeper������
1������broker��consumer�Ķ�̬�������뿪��
2���������ؾ��⣬��broker��consumer������뿪ʱ�ᴥ�����ؾ����㷨��ʹ��һ��consumer group�ڵĶ��consumer�Ķ��ĸ���ƽ�⡣
3��ά�����ѹ�ϵ��ÿ��partition��������Ϣ��
��־ѹ����Log Compaction��
1�����һ��topic��partition��ѹ��ʹ��Kafka����֪��ÿ��key��Ӧ�����һ��ֵ��
2��ѹ��������������Ϣ��
3����Ϣ��offset�Dz����ġ�
4����Ϣ��offset��˳��ġ�
5��ѹ�����ͺͽ����ܽ������縺�ء�
6����ѹ�������ʽ�־û������̡�