上篇的链接在这里:
函数,从编辑到编译 (上) --带你了解预编译做了什么
下面继续:
2. 编译
所谓编译过程,就是把预处理完的文件进行一系列词法分析,语法分析,语义分析及优化后生产相应的汇编代码文件。这一步是整个程序构建的核心部分,也是最容易出错的一部分。
从现在开始,步骤就变得十分复杂了。
对函数来说,这一阶段是最繁琐也是最为危险的:稍有不慎,轻则 warning 重则 error 。
我见过许多出错的函数,他们连着行号被编译器带到窗口,当街示众。
也有些函数和 #pragma 关系比较好,小错误被遮掩过去,免去了示众的命运。
2.1 扫描
我们要先经过一台扫描器 (Scanner),这机器如此庞大,以至于我根本看不出内部的细节。
我对大型机器充满好奇,编译器给了我一本手册――《编译宝典》,他说里面有讲扫描器的实现。
可我看不懂。
编译器告诉我,想要参透这本宝典,需要付出代价。
“代价?像岳不群那样?”
“你想哪儿去了!你说的那是《葵花宝典》,我说的代价是时间和精力!编译器这种庞大的工程,需要一个团队来合作完成,除非你是打算写写玩具编译器。”
所以我放弃了造出这些机器的想法,因为函数的一生太短了,希望你能实现我的愿望。
在扫描器里的体验不太舒服,它像一台 X 光机,把我的身体里里外外看了个遍,给我的感觉很不妙。
出了机器,会收到一个检查报告,像这样(篇幅有限,只拿一个表达式举例子):
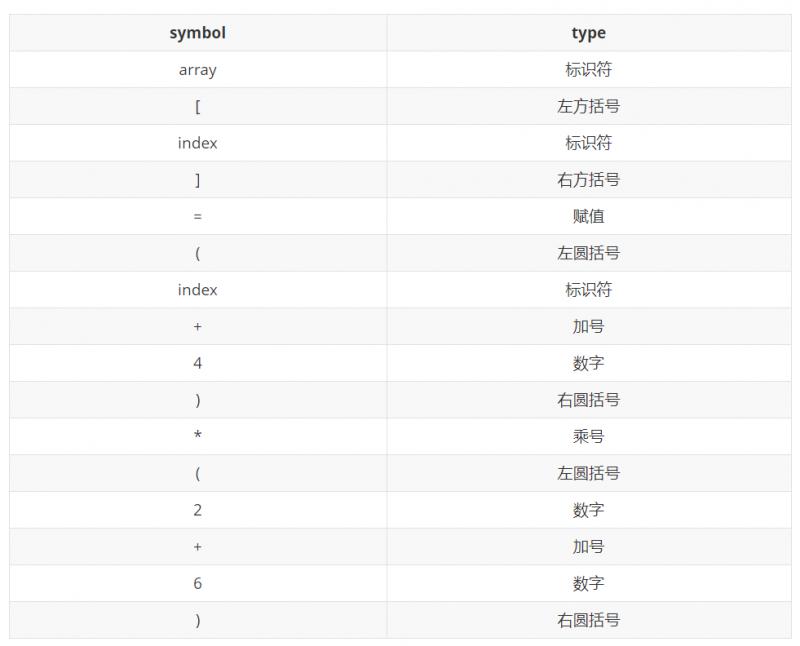
拿着这份报告,就该去进行语法分析了。
2.2 语法分析
语法分析器(Grammar Parser)就不需要我整个躺进去,只用把扫描器生成的检查报告交给他。
分析好之后,我拿到了一个盆栽 新的报告 ―― 一棵树,或者,准确一点,一棵语法树(Syntax Tree)。
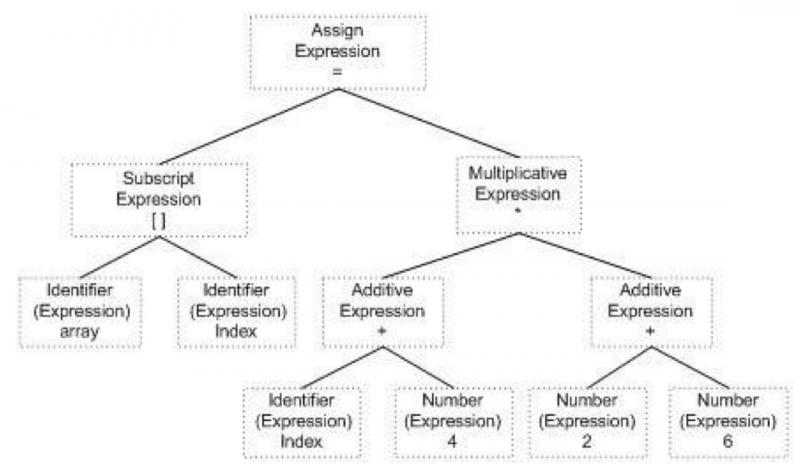
树的枝叶一切正常,表示我的表达式是合法的。毫无疑问,我再次通过了检查。
但有的函数就不这么幸运了,他们会在这一步检查出问题,比如括号不匹配,表达式中缺少操作符等等,这些错误会上报编译器,最后报告给程序员。――他们面临着整改的命运。
2.3 语义分析
刚刚的语法分析器,顾名思义,只完成了语法层面的分析,但他不了解表达式是不是真的有意义。
比如让两个指针做乘法,在语法上是合法的,但这是没有意义的。语义分析器(Semantic Analyzer)就能够检查出这个错误。
但语义分析也不是万能的,它也有局限性――语义分析仅仅能分析静态语句。
你问我什么是静态语义?
我不知道,因为我只是一个函数。
所谓静态语义,是能在编译期间可以确定的语义,与之相对的动态语义,就是只有在运行期才能确定的语义。
int a = 6 / 0;从静态语义上看,这句话是合法的,编译期间不会报错,但等到程序运行到这句时,就会报出 devided by 0 的错误,造成程序异常退出。
2.4 代码生成与优化
走到这,编译部分也算快结束了。
剩下的两台机器,一台叫代码生成器(Code Generator),一台叫目标代码优化器(Target Code Optimizer)。
目标代码优化器总是嫌弃代码生成器,因为代码生成器生成的代码效率低,还需要他花大功夫来优化。
用优化器的话讲:“生成器那家伙,每次生成一堆低效率的代码,我还得从头读到尾,进行基于数据流分析(data-flow analyse)技术的全局优化,太累了。”
其实代码生成器有做优化,叫做局部代码优化,只是优化程度远远不及优化器,所以他不好意思反驳优化器。
不过这不代表代码生成器结构就简单了,它生成代码的过程十分依赖于目标机器――这意味着它要适配许许多多的机器,不同的机器有着不同的字长、寄存器、整数数据类型和浮点数数据类型等,它要考虑的事情太多了。
经过生成器,表达式的样子发生了巨大的变化(这里以 x86 的汇编语言来表示):
movl index, %ecx ; value of index to ecx
addl $4, %ecx ; ecx = ecx + 4
mull $8, %ecx ; ecx = ecx * 8
movl index, %eax ; value of index to eax
movl %ecx, array(,eax,4) ; array[index] = ecx优化器对上面的代码又做了一番深层次的优化,包括选择寻址方式,删除多余指令等。(代码比较短,所以优化效果并不明显。)
movl index, %edx
leal 32(,%edx,8), %eax
movl %eax, array(,%edx,4)每次走过这些流程,我都不得不感叹于编译器复杂的结构,也只有优秀的程序员们,才能够完成这么伟大的工程吧。
函数的编译,就是这么繁琐,且枯燥。
今天令我惊讶的是,所有函数都完美的通过了编译阶段。
“Nice~ 这次可以早点休息了!”不止是我,其他函数也是这么想的吧。
我们有说有笑,悠然等待着链接程序来做最后的收尾工作。
但万万没想到,危机竟出现在链接阶段。
3. 链接
我听长辈们说,链接器,拥有比编译器更为悠久的历史。
每当我把这个事实告诉新来的函数时,他们总是一脸不可思议:
“我们都是先编译,再链接的,怎么会先有链接器,再有编译器?这又不是先有鸡还是先有蛋的哲学问题。”
我第一次听说的时候,也有这样的疑惑。
“链接是在汇编语言时代就出现了的概念。在那之前,是机器语言的时代。但是想要对机器语言进行修改,那就太困难了,因为机器指令的修改经常造成具体指令地址的改变,牵一发而动全身。所以汇编语言产生了,用符号来标记位置,而符号与实际地址的映射工作,就是链接器来做的。”我向他解释道。
“我明白了,因为高级语言出现在后面,所以从高级语言到汇编语言的步骤――编译,要比链接来的晚一些。”
是啊,编程语言的发展,从机器语言,到汇编语言,再到现在的高级语言,经过了几十年的时间。但尽管是现代,我们编译型高级语言,想要运行,还是得回到汇编语言,再被翻译成机器语言,看起来是绕了一个大圈,但人类程序员的生产力,却得到了质的飞跃。
人类总是能想出各种办法来减轻他们的工作量。
...
链接过程主要包括了地址和空间分配(Address and Storage Allocation)、符号决议(Symbol Resolution)和重定位(Relocation)等这些步骤。
看起来挺高大上,其实链接器做的和早期程序员人工调整地址没什么两样,只是更加复杂而已――你不要指望现在的语言特性比早期简单。
但从本质上说,就是把指令对其他符号地址的引用加以修正。链接的重点就是两个不同的目标文件。
这一阶段本来是很容易通过的,但今天,居然出现了大错误。
问题出在 main.c 中。
出乎所有函数的意料,包括 main。
4. 尾声
回到编辑器,我们检查遍了 main 函数内部的所有函数,从他们的声明,再到他们的实现,全都没有问题。
“会不会是 #include 的时候出了什么问题?”有函数提出了自己的看法。
我们决定分头行动,一部分和其他文件协作检查函数声明,剩下一部分负责排查有没有出现循环 #include 问题。
不知过了多少 CPU 周期,大家回来了,一无所获,两种问题都没有出现。
我们一筹莫展。
“ main.c ,链接出错...”我满脑子都在想可能原因,“不会是 main 函数本身出了问题吧!”
“快,去看看宏定义有没有异常!”
宏定义?虽然大家有些疑惑,但还是照做了。
果然,发现了异常:
...
...
#define ma