class object layout
//64位系统
class A{ }; //sizeof(A)为1
class B : virtual public A{ }; //sizeof(B)为8
class C : virtual public A{ }; //sizeof(C)为8
class D : public B, public C{ }; //sizeof(D)为16
//sizeof(A)为1是因为编译器会安插一个char,使得多个object会有不同的地址
-
内存布局:
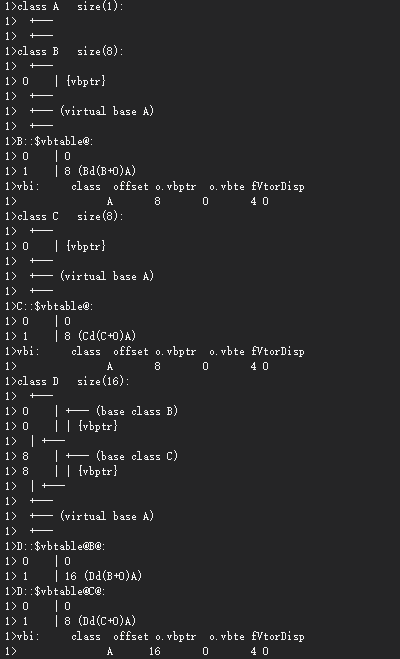
-
造成B和C大小为8的原因如下:
- 语言本身造成的额外负担。若derived class派生自virtual base class,则derived class中含有一个vbptr指针,此指针指向virtual base class subobject或一个相关表格vbtable,而vbtable存放virtual base class subobject地址或编译位置(offset)
- 注:derived class中包含本身和base class组成了对象,而属于某个基类的对象就是base class subobject
- 编译器对特殊情况的优化处理。virtual base class A subobject的1 bytes一般放于derived class的固定部分的末端,某些编译器会对empty virtual base class提供特殊支持
- empty virtual base class不定义任何数据,提供一个virtual interface。某些编译器处理下,一个empty virtual base class被视为derived class object最开始的那一部分,并没有使用任何的额外空间。因为含有member,所以也没有必要安插char
- Alignment padding的限制。聚合的结构体大小收alignment限制,使其在内存更有效率地被存取
- 语言本身造成的额外负担。若derived class派生自virtual base class,则derived class中含有一个vbptr指针,此指针指向virtual base class subobject或一个相关表格vbtable,而vbtable存放virtual base class subobject地址或编译位置(offset)
-
nonstatic data members和virtual nonstatic data members都存与class object中,且没有强制定义其排列顺序;static data members存于global data segment,不影响class object大小
-
nonstatic data members在class object中同一个access level的内存排列顺序应和被声明的顺序相同,不受static data members影响
-
class object的同一个access section中members不一定非得连续排列,member的alignment和内部使用的data members可能会介于声明的members间;且多个access section中data members可以自由排序,不用考虑声明顺序
-
access sections的多少并不影响内存大小
class A { public: ... private: float x; static int y; private: float z; static int i; private: float j; }
the binding of a data member
- 现有以下代码:
extern float x;
class A
{
public:
A(float, float, float);
float X() const { return x; };
private:
float x, y, z;
}
-
放在现在,X()的返回值肯定是class内部那个,但在以前的编译器,此操作会返回extern那个。因此,这也就产生了两种防御性程序风格:
-
将所有data member放于class声明最开始处
class A { private: float x, y, z; public: //这样将保证class内部 float X() const { return x; }; } -
将所有inline member functions,放于class外。inline函数实体,在整个class声明完全看见后,绑定操作才会进行
class A { public: A(); private: float x,y,z; }; inline float A::X() const { return x; }
-
-
请思考如下代码:
typedef int length; class A { public: //length被判定为int类型 //_val 判定为A::_val void do1( length val ) { _val = val; }; length do1() { return _val; }; private: //这里length必须在"本class对它的第一个操作前"被看见.否则先前的判定操作不合法 typedef float length; length _val; } -
对于member function的argument list来说,argument list中的名称会在它们第一次遭遇时被适当判断完成。因此,需要将nested type声明放于判断前
data member 的存取
? 现有如下代码:
A a;
//x的存取成本?
a.x = 0.0;
A* ot = &A;
//通过指针的x的存取成本?
pt->x = 0.0
- 用指针进行存取:若A为derived class且继承体系中含有virtual base class,且存取的member从virtual base class继承而来,和单一继承、多重继承这样的就有很大差距,因为这个存取操作需要延迟至执行器,经由一个额外的间接导引解决
static data members
-
class object里的static data member,对于class objects和其本身,都不会产生额外负担
-
无论是复杂的继承关系还是单一的class object,static data member永远只有一个实例
-
static data member每次被取用时,编译器都会对其进行转化
//a.i = 0; A::i = 0; //pt->i = 0; A::i = 0; -
多个相同的classs都声明相同的static member,在data segment中这肯定会导致名称冲突,但编译器对其进行name-mangling,也就是暗中对每一个冲突的static data member编码,如此即可获得独一无二的识别代码
- 不同的编译器有不同的name-mangling,但都包含两点:
- 运用一个算法推导识别代码
- 若编译系统必须和使用者交谈,这是识别代码可以被轻易地推导回原来的名称
- 不同的编译器有不同的name-mangling,但都包含两点:
-
对于以上代码,虽然使用的member selection operators对static data member进行存取操作,但这只是图方便,实际上static data member并不在class object中,因此也并没有通过class object
若由A中的一函数调用static data member,会发生如下转化:
//do为A中的函数
do().i = 0;
//转化求值
(void) do();
A.i = 0;
若取static data member地址,也只会得到指向其类型的指针,并不会指向其class member
&A