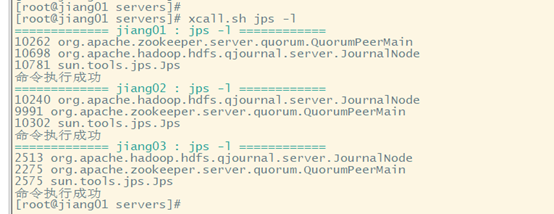
[root@jiang02 mapreduce]# start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /export/servers/hadoop-2.8.5/logs/yarn-root-resourcemanager-jiang02.out
jiang03: starting nodemanager, logging to /export/servers/hadoop-2.8.5/logs/yarn-root-nodemanager-jiang03.out
jiang01: starting nodemanager, logging to /export/servers/hadoop-2.8.5/logs/yarn-root-nodemanager-jiang01.out
jiang02: starting nodemanager, logging to /export/servers/hadoop-2.8.5/logs/yarn-root-nodemanager-jiang02.out
[root@jiang02 mapreduce]#