本文版权归博客园和作者吴双本人共同所有 转载和爬虫请注明原文地址 www.cnblogs.com/tdws。
本文参考和学习资料 《ES权威指南》
一.基本概念
存储数据到ES中的行为叫做索引,每个索引可以包含多个类型,这些不同的类型存储着多个文档,每个文档有多个属性。
索引 index/indexes相当于传统关系数据库中的数据库,是存储关系型文档的地方。
索引在ES做动词的时候,索引一个文档就是存储一个文档到索引(名词)中,以便被检阅和查询到。类似于insert。
默认下,一个文档中的每个属性都是被索引的。没被索引的属性是不能搜索到的。
二.ES集群 主分片 副分片 健康状态
垂直的硬件扩容是有极限的,真正的扩容能力来自于水平扩容(为集群内增加更多节点),集群是由一个或者多个拥有相同 cluster.name 配置的节点组成, 它们共同承担数据和负载的压力。当有节点加入集群中或者从集群中移除节点时,集群将会重新平均分布所有的数据。
主节点负责管理集群范围内所有的变更,增加删除索引和增加删除节点等。主节点不涉及文档级别的变更和搜索等操作。任何一个节点都可接受请求,任何一个节点都知道任意文档所处位置。
curl -XGET 'localhost:9200/_cluster/health?pretty' 获取集群健康状态
status 字段指示着当前集群在总体上是否工作正常。它的三种颜色含义如下:
green 所有的主分片和副本分片都正常运行。
yellow 所有的主分片都正常运行,但不是所有的副本分片都正常运行。
red 有主分片没能正常运行。
分片是一个底层的工作单元,是数据的容器,一个分片是一个Lucene实例。它本身就是一个完整的搜索引擎,到本文最后的分页,相信你能更加理解。应用不会与分片交互。一个分片可以使主分片或者副本分片。副本分片只是主分片的一个拷贝。副本分片用于从灾难中保护数据并未搜索读取操作提供服务,注意只是读操作。
默认情况下创建一个索引,会被分配5个分片。当然我们也可以指定分片数量还有副本数量,比如:
curl -XPUT 'localhost:9200/blogs?pretty' -H 'Content-Type: application/json' -d'
{
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 1
}
}
假设我们目前集群中只有一个节点,那么刚才三个分片的存储是这样的。即使我们设置了1个副本分片也没用,因为相同数据的主分片和副本分片在一个节点上没有任何意义。

如果此时,我们为集群增加一个节点,主分片和副本分片是下图这样的。副本分片得以创建,并分配在新节点上。现在我们的容灾能力就可以允许失去一台节点的数据,数据读取服务节点就是两个。

接下来,集群中再加入节点,情况如下图所示。为了提高更强的服务能力和容灾能力,均匀分布了主分片和副本分片,现在我们三个node,失去任意一台,都能保障数据和服务。

最后,关闭node1,使集群失去MASTER, 而集群必须拥有一个主节点来保证正常工作,所以发生的第一件事情就是选举一个新的主节点: Node 2 。在失去Master的同时,也失去了主分片 1 和 2 ,并且在缺失主分片的时候索引也不能正常工作。 如果此时来检查集群的状况,我们看到的状态将会为 red :不是所有主分片都在正常工作。幸运的是,在其它节点上存在着这两个主分片的完整副本, 所以新的主节点立即将这些分片在 Node 2 和 Node 3 上对应的副本分片提升为主分片, 此时集群的状态将会为 yellow 。 这个提升主分片的过程是瞬间发生的,如同按下一个开关一般。

如果现在恢复node1,如果 Node 1 依然拥有着之前的分片,它将尝试去重用它们,同时仅从主分片复制发生了修改的数据文件。
三.基本的操作
一个文档的 _index 、 _type 和 _id 唯一标识一个文档。
索引仅仅是一个逻辑上的命名空间,这个命名空间由一个或者多个分片组合在一起。对于应用程序而言,无需关注分片,只需要知道一个文档位于一个索引内。
索引index名称必须小写,不能以下划线开头,不能有逗号。类型type名称可以大写或者小写,但是不能以下划线或者句号开头,不应该包含逗号并且长度在265字符及以内。
当你创建一个新文档的时候,要么主动给id,要么让ES自动生成。所以,确保创建一个新文档的最简单办法是,使用索引请求的 POST 形式让 Elasticsearch 自动生成唯一 _id,比如:
POST /website/blog/ { ... }
以下两种方式为等效操作:
PUT /website/blog/123?op_type=create { ... }
PUT /website/blog/123/_create { ... }
在获取文档的时候,_source字段是用于筛选我们只想要的目标字段,比如
GET /website/blog/123?_source=title,text
如果想要得到http响应头部,可以通过传递 -i 比如
curl -i -XGET http://localhost:9200/website/blog/124?pretty
如果只想得到source字段,不想得到任何其他元数据,使用方式如下:
GET /website/blog/123/_source
如果查询文档是否存在,使用Http HEAD,比如:
curl -i -XHEAD http://localhost:9200/website/blog/123 //存在则返回200 OK,不存在则是404Not Found
在 Elasticsearch 中文档是 不可改变 的,不能修改它们。 相反,如果想要更新现有的文档,需要 重建索引或者进行替换, 我们可以使用相同的 index API 进行实现。和使用创建时PUT是一样的,ES内部都做了。部分更新,也是如此。使用DELETE删除文档,删除文档不会立即将文档从磁盘中删除,只是将文档标记为已删除状态,随着你不断的索引更多的数据,Elasticsearch 将会在后台清理标记为已删除的文档。
四.并发冲突的解决
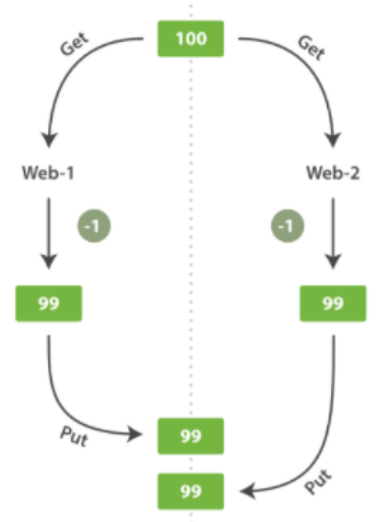
假设上图操作的是库存数量stock_count ,web_1 对 stock_count 所做的更改已经丢失,因为 web_2 不知道它的 stock_count 的拷贝已经过期。变更越频繁,读数据和更新数据的间隙越长,也就越可能丢失变更。在数据库领域中,有悲观和乐观两种方法通常