6.1 SELECT ... FROM 语句
hive> SELECT name,salary FROM employees; --普通查询
hive>SELECT e.name, e.salary FROM employees e; --也支持别名查询
当用户选择的列是集合数据类型时,Hive会使用 JSON 语法应用于输出:
hive> SELECT name,subordinates FROM employees; 显示 John Doe ["Mary Smith","Todd Jones"] 数组类型的显示
hive>SELECT na
me,deductions FROM employees; 显示 John Doe {"Federal Taxes":0.2,"State Taxes":0.05} MAP 输出
hive>SELECT na
me,adress FROM employees; 显示 John Doe {"street":"1 Michigan Ave.","city":"Chicago","state":"IL"} address 列是一个 STRUCT
hive> SELECT name,subordinates[0] FROM employees; 查看数组中的第1个元素,如果不存在元素将返回 NULL
hive>SELECT na
me,deductions["State Taxes"] FROM employees;
查询MAP 元素
hive>SELECT na
me,adress.city FROM employees; 查询STRUCT 中的一个元素,可以用 . 符号
以上三种查询 在 where 子句中同样可以使用这些方式;
hive>SELECT symbol, `price.*` FROM stocks; 用正则表达戒严 选择我们想要的列,本句是查 symbol 列和所有列名以 price 作为前缀的列;
hive>SELECT upper(name), salary, deductions["Federal Taxes"], round(salary * (1 - deductions["Federal Taxes"])) FROM employees; 使用 round() 方法返回一个 Double 类型的最近整数。
Hive 中所支持的运算符:
A + B 、A - B、A * B、A / B、A % B [求余]、A & B [按位与]、A | B [按位或]、A ^ B [按位取异或]、~A [按位取反]


【图片取自《hive编程指南》 81页】
注意:算术运算符接受任意的数值类型,不过,如果数据类型不同,那么两种类型中值范围较小的那个数据类型转换为其他范围更广的数据类型。
当进行算术运算时,用户需要注意数据溢出或数据下溢问题,Hive 遵循的是底层 Java 中数据类型的规则,因为当溢出或下溢发生时计算结果不会自动转换为更广泛的数据类型,乘法和除法最有可能会引发这个问题;
有时使用函数将数据值按比例从一个范围缩放到另一个范围也是很有用的,如 按照 10 次方幂进行除法运算或取 log 值等。
所有数学函数:

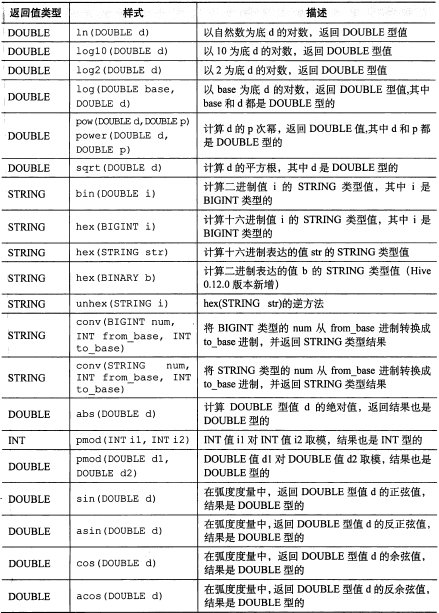




【图片取自《hive编程指南》 82页】
需要注意的是函数 floor、round、ceil (向上取整)输入的是 DOUBLE 类型的值,返回的值是 BIGINT 类型的。
所有聚合函数:

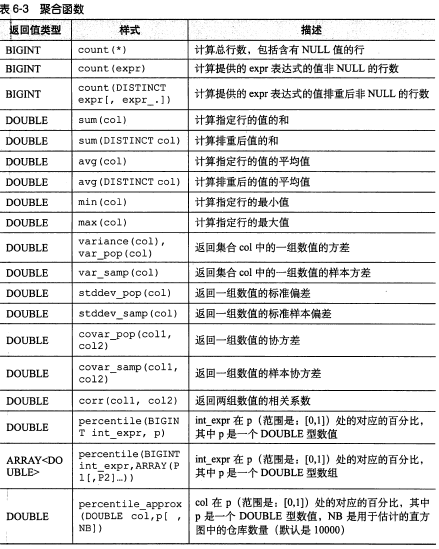


【图片取自《hive编程指南》 85页】
hive> SET hive.map.aggr=true; --设置这个属性为 true 来提高聚合的性能
hive>SELECT count(*), avg(salary) FROM employees; --这个设置会触发在 map 阶段进行的“顶级”聚合过程,(非顶级聚合过程将会在执行一个 GROUP BY 后进行),不过这个设置将需要更多的内存。
hive>SELECT count(DISTINCT symbol) FROM stocks; 多个函数还可以接受像 DISTINCT 这个表达式,来进行排重;v如果 symbol 是分区列时会返回 0.。。。是个bug;
hive>SELECT count(DISTINCT ymd), count(DISTINCT volume
) FROM stocks; 官方不允许这样查,但实际可以这样查;
表生成函数:与聚合函数相反的一类函数不是所谓的表生成函数,基可以将单列扩展成多列或者多行;
hive> SELECT explode (subordinates) AS sub FROM employees; 本语句将 employees 表中每行记录中 subordinates 字段内容转换成 0 个或者多个新的记录行,如果 subordinates 字段内容为空的话,那么将不会产生新的记录,如果不为空的话,那么这个数组的每个元素都将产生一行新记录;AS sub 子句定义了列别名 sub。当全用表生成函数时,Hive 要求使用列别名。【具体在13章中会详细介绍】
表生成函数:
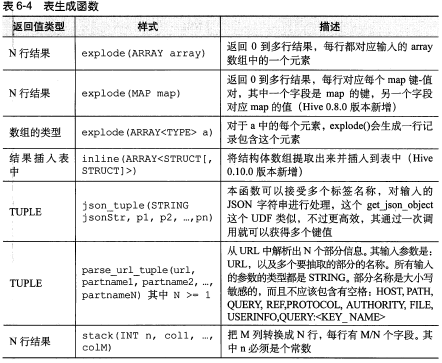

【图片取自《hive编程指南》 85页】
其它内置函数:

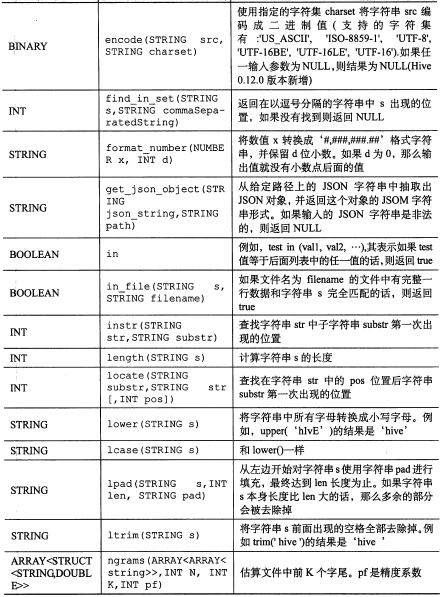
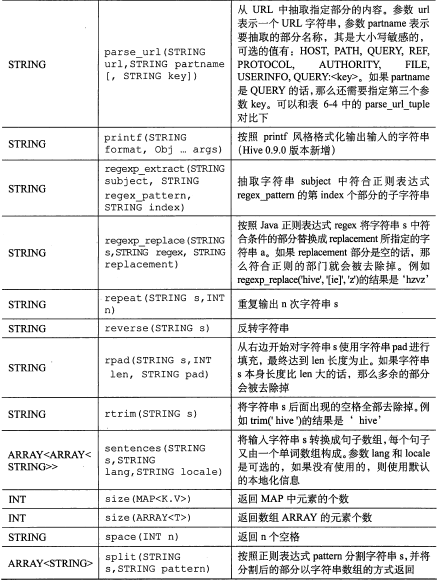
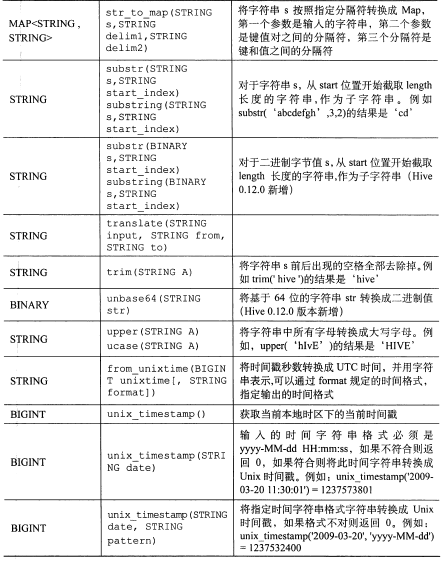
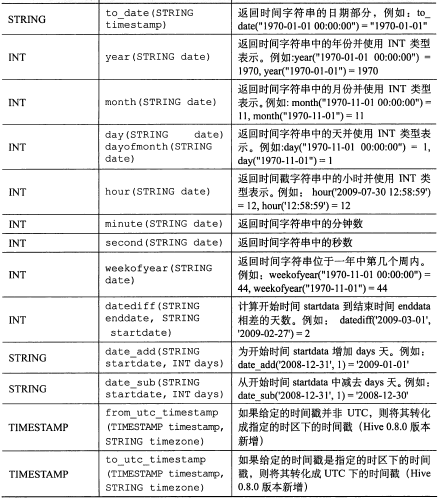
其它内置函数:





【图片取自《hive编程指南》 88-92页】
hive> SELECT upper(name), salary, deductions["Federal Taxes"], round(salary *(1 - deductions["Federal Taxes"])) FROM employees
LIMIT 2
;
LIMIT 子句用于限制返回的行数;
hive> SELECT upper(name), salary, deductions["Federal Taxes"]
as fed_taxes
, round(salary *(1 - deduction