一、Sqoop 基本命令
1. 查看所有命令
# sqoop help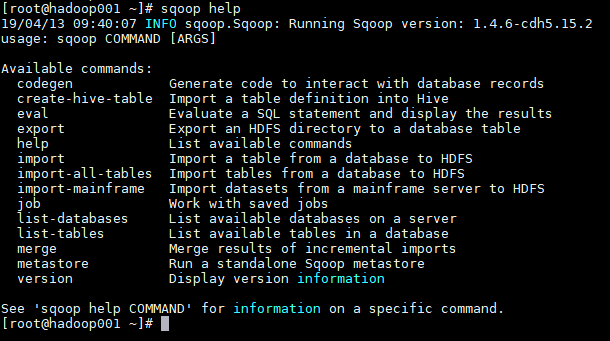
2. 查看某条命令的具体使用方法
# sqoop help 命令名二、Sqoop 与 MySQL
1. 查询MySQL所有数据库
通常用于 Sqoop 与 MySQL 连通测试:
sqoop list-databases \
--connect jdbc:mysql://hadoop001:3306/ \
--username root \
--password root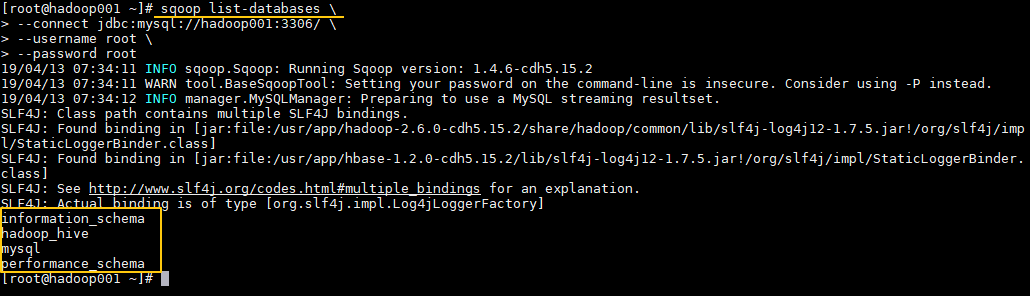
2. 查询指定数据库中所有数据表
sqoop list-tables \
--connect jdbc:mysql://hadoop001:3306/mysql \
--username root \
--password root三、Sqoop 与 HDFS
3.1 MySQL数据导入到HDFS
1. 导入命令
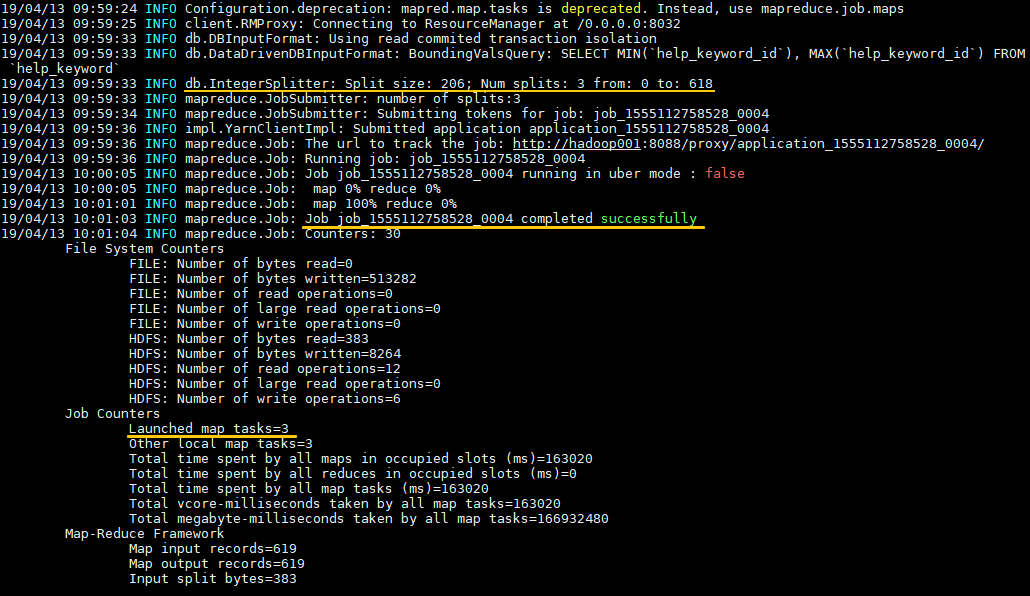
示例:导出 MySQL 数据库中的 help_keyword 表到 HDFS 的 /sqoop 目录下,如果导入目录存在则先删除再导入,使用 3 个 map tasks 并行导入。
注:help_keyword 是 MySQL 内置的一张字典表,之后的示例均使用这张表。
sqoop import \
--connect jdbc:mysql://hadoop001:3306/mysql \
--username root \
--password root \
--table help_keyword \ # 待导入的表
--delete-target-dir \ # 目标目录存在则先删除
--target-dir /sqoop \ # 导入的目标目录
--fields-terminated-by '\t' \ # 指定导出数据的分隔符
-m 3 # 指定并行执行的 map tasks 数量日志输出如下,可以看到输入数据被平均 split 为三份,分别由三个 map task 进行处理。数据默认以表的主键列作为拆分依据,如果你的表没有主键,有以下两种方案:
- 添加
-- autoreset-to-one-mapper参数,代表只启动一个map task,即不并行执行; - 若仍希望并行执行,则可以使用
--split-by <column-name>指明拆分数据的参考列。
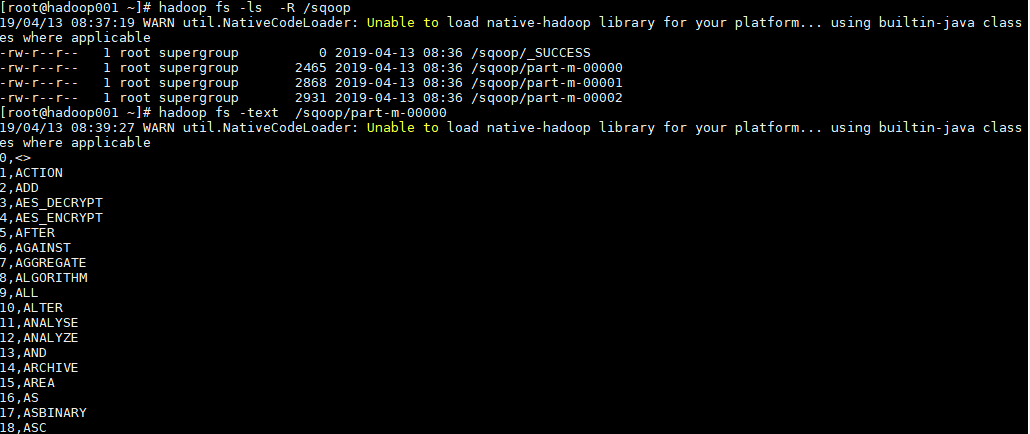
2. 导入验证
# 查看导入后的目录
hadoop fs -ls -R /sqoop
# 查看导入内容
hadoop fs -text /sqoop/part-m-00000查看 HDFS 导入目录,可以看到表中数据被分为 3 部分进行存储,这是由指定的并行度决定的。
3.2 HDFS数据导出到MySQL
sqoop export \
--connect jdbc:mysql://hadoop001:3306/mysql \
--username root \
--password root \
--table help_keyword_from_hdfs \ # 导出数据存储在 MySQL 的 help_keyword_from_hdf 的表中
--export-dir /sqoop \
--input-fields-terminated-by '\t'\
--m 3 表必须预先创建,建表语句如下:
CREATE TABLE help_keyword_from_hdfs LIKE help_keyword ;四、Sqoop 与 Hive
4.1 MySQL数据导入到Hive
Sqoop 导入数据到 Hive 是通过先将数据导入到 HDFS 上的临时目录,然后再将数据从 HDFS 上 Load 到 Hive 中,最后将临时目录删除。可以使用 target-dir 来指定临时目录。
1. 导入命令
sqoop import \
--connect jdbc:mysql://hadoop001:3306/mysql \
--username root \
--password root \
--table help_keyword \ # 待导入的表
--delete-target-dir \ # 如果临时目录存在删除
--target-dir /sqoop_hive \ # 临时目录位置
--hive-database sqoop_test \ # 导入到 Hive 的 sqoop_test 数据库,数据库需要预先创建。不指定则默认为 default 库
--hive-import \ # 导入到 Hive
--hive-overwrite \ # 如果 Hive 表中有数据则覆盖,这会清除表中原有的数据,然后再写入
-m 3 # 并行度导入到 Hive 中的 sqoop_test 数据库需要预先创建,不指定则默认使用 Hive 中的 default 库。
# 查看 hive 中的所有数据库
hive> SHOW DATABASES;
# 创建 sqoop_test 数据库
hive> CREATE DATABASE sqoop_test;2. 导入验证
# 查看 sqoop_test 数据库的所有表
hive> SHOW TABLES IN sqoop_test;
# 查看表中数据
hive> SELECT * FROM sqoop_test.help_keyword;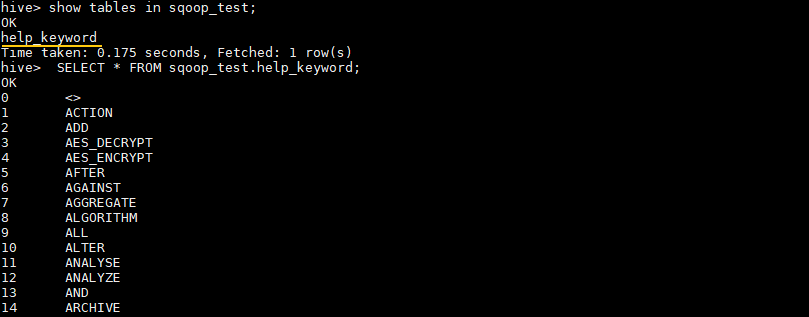
3. 可能出现的问题
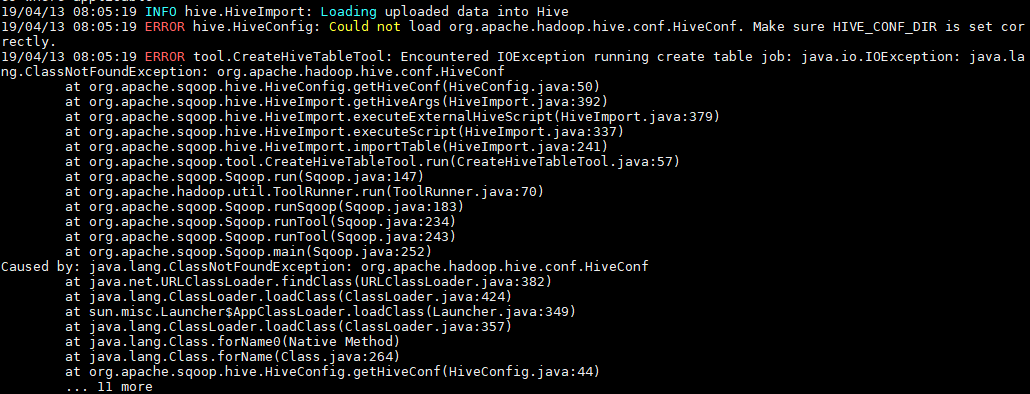
如果执行报错 java.io.IOException: java.lang.ClassNotFoundException: org.apache.hadoop.hive.conf.HiveConf,则需将 Hive 安装目录下 lib 下的 hive-exec-**.jar 放到 sqoop 的 lib 。
[root@hadoop001 lib]# ll hive-exec-*
-rw-r--r--. 1 1106 4001 19632031 11 月 13 21:45 hive-exec-1.1.0-cdh5.15.2.jar
[root@hadoop001 lib]# cp hive-exec-1.1.0-cdh5.15.2.jar ${SQOOP_HOME}/lib4.2 Hive 导出数据到MySQL
由于 Hive 的数据是存储在 HDFS 上的,所以 Hive 导入数据到 MySQL,实际上就是 HDFS 导入数据到 MySQL。
1. 查看Hive表在HDFS的存储位置
# 进入对应的数据库
hive> use sqoop_test;
# 查看表信息
hive> desc formatted help_keyword;Location 属性为其存储位置:
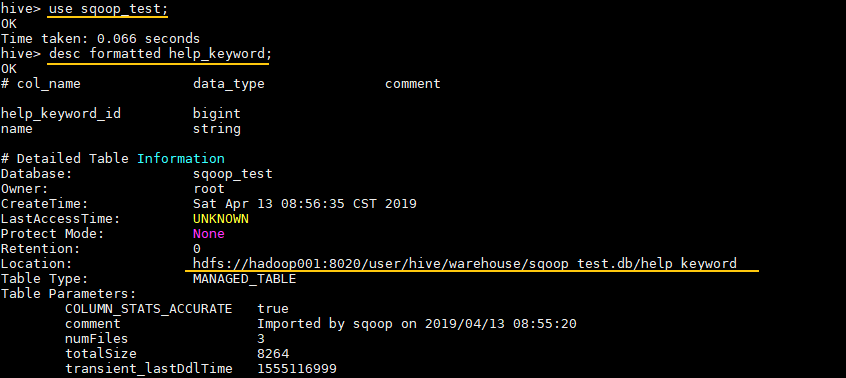
这里可以查看一下这个目录,文件结构如下:

3.2 执行导出命令
sqoop export \
--connect jdbc:mysql://hadoop001:3306/mysql \
--username root \
--password root \
--table help_keyword_from_hive \
--export-dir /user/hive/warehouse/sqoop_test.db/help_keyword \
-input-fields-terminated-by '\001' \ # 需要注意的是 hive 中默认的分隔符为 \001
--m 3 MySQL 中的表需要预先创建:
CREATE TABLE help_keyword_from_hive LIKE help_keyword ;五、Sqoop 与 HBase
本小节只讲解从 RDBMS 导入数据到 HBase,因为暂时没有命令能够从 HBase 直接导出数据到 RDBMS。